
A canonical tag (rel = canonical) is a piece of HTML code that helps Google rank a specific page from a set of similar or duplicate pages.
Generally, all websites, especially e-commerce sites, contain duplicate content.
However, it is a practice sanctioned by Google that could affect the visibility and ranking of a website in search results.
Fortunately, there is a very effective way to solve this problem once and for all: It is the use ofcanonical URLs.
However:
- How to use them effectively?
- In which context can they be used?
- How to check their status on a blog or a website?
We talk about it in this guide!
Chapter 1: Canonical URL : What is it and what is its importance in the SEO of a website?
In this chapter, I will provide more explanation about the canonical URL and list the factors that justify its importance in the SEO of a website.
For this, the following points will be discussed:
- Canonical tag: What you need to know
- How do search engines handle duplicate or similar pages?
- Why are canonical tags important in SEO?
- What is the difference between a rel canonical from a 301 redirect ?

1.1) What is a canonical tag?
The rel = canonical tag, also called ” canonical link “is an HTML element that helps webmasters to avoid problems of duplicate content the rel = canonical tag, also known as “canonical link”, is an HTML element that helps webmasters avoid duplicate content problems: One of the common plagues on websites, especially e-commerce sites.

When such content is present on a website, the site faces the risk of cannibalization. This means that the search engine can sometimes index and rank the wrong version of a page in the search results.
For this reason, this canonical tag was created by all the major search engines such as Google, Microsoft and Yahoo in order to quickly and easily solve the problems related to duplicate content
1.1.1. Synonyms of the term canonical URL
Although their meaning differs, the following terms are often used to designate the canonical URL
- Canonical tag
- Canonical link
- canonical rel
- Canonical URL;
- Canonical tag;
- rel=”canonical”
They are all used to refer to the canonical HTML element.
1.1.2. What does a rel = canonical tag look like?
The syntax of the canonical tags found in the “head” section of a Web page is as follows:

The code has two important components:
- link rel = “canonical
rel means relationship. Therefore, the relationship of the link is defined as canonical.
- href = “URL”
href specifies the end point of the link. This is where the URL is placed that Google should index and rank. This is also called theCanonical URL.
Find out in the next section, how search engines handle duplicate content.
1.2. how duplicate or similar pages are handled by search engines
When most search engines encounter two or more pages with very similar content, they get confused. So, they index only one page and abandon the others

The duplicate page URL they decide to choose is often based on a number of factors, including:
- The one that was crawled first
- The one with the most internal and external links.
Duplicate content is not only bad for SEO, but it can also hurt conversion rates.
There will often be situations where you have a number of pages that are vital to your website’s infrastructure, but contain similar or identical content
Rather than risk a penalty for duplicate content, you can add a rel = canonical tag on the page that you feel is the preferred source of information. This will allow search engines to find you.

You will find more details in the example below.
1.2.1. Case study: Example of product page duplication
Let’s take an example of a website that sells toys (trucks) and that contains three different product pages for the same content.

- /toys/trucks/red
- /toys/sale/red
- /toys/under-10/red
All three product pages have the exact same content with only small changes, such as the top breadcrumb link.
With the same product on three different pages, the presence of a canonical tag is essential to specify the original page:

By using the canonical tag, I’m signaling to search engines that the main product page version is located at http://www.example.com/toys/trucks/redwhile the other two URLs are just copies.
Thus, the canonical tag will yield:

However, it is preferable to choose as main page, the product page permanent that is not part of the following categories:
- Sales (sales may end one day);
- Goods under 10 € (the price can exceed 10 € overnight).
Let’s move on to the benefits that this tag brings to the SEO of a website.
1.3. Canonical tag: Why is it important in SEO?
Whether you are an agency or an SEO professional, canonicalization should be on your list of activities for On-Page SEO optimization
Here is a list of the main points that make canonical tags so important in website SEO.
1.3.1. Saves crawling budget
By specifying a canonical tag, you save valuable time for the crawler that crawls your website
This allows it to reach other important URLs and content on your website more easily, thus saving your crawling budget
1.3.2. Proper Link Juice Management
The use of canonical tags ensures that the link juice is passed on to the correct version of the page. Normally, if you have different pages with similar content, Google distributes the link juice evenly to all of them
But, by specifying a canonical tag, you tell Google which page you want to give importance to and rank in the SERPs. Google then passes all the link juice to the important page, ignoring any duplicate pages.
This ensures proper link juice management on your website.
1.3.3. Ensures relevant URLs are ranked for queries
Canonical tags ensure that URLs that are relevant to your search terms are ranked. The problem here is that it is possible for two URLs on your website to compete for the same keyword on SERPs

But, by using rel = canonical, you can avoid this situation. Be sure to specify the appropriate canonical URL that you want Google to index and rank in the HTML code of the canonical tag.
1.3.4. Canonical tags make Google’s job easier on large sites
When you have a huge website with many URLs, crawling and indexing all those URLs can become tedious for Google. This results in the confusion of duplicate pages and other variations it faces.
Indeed, this can lead to huge consequences for your website. So, to make Google’s job easier, you need to specify proper canonical tags on all pages

This ensures that Google crawls and indexes the right pages.
1.3.5. Prevent internal and external duplicate content
With the canonical URL, you can prevent duplicate content not only internally, but also externally
Internal duplicate content occurs only on your website.

External duplicate content occurs when there are duplicate or very similar pages on two different websites.

Before I close this chapter, I need to talk about the difference between canonical URL and 301 redirect to clear up any doubts or confusion.
1.4. What is the difference between a canonical rel and a 301 redirect?
The main difference is the impact on the user’s navigation.
The 301 redirects redirects directly affect theuser experiencebecause the user is redirected to a different URL than the one he started with.

The canonicaldirective, on the other hand, only affects the crawler of search engines, because the user is not redirected and therefore does not perceive its existence.
From an SEO point of view, the rel canonical and 301 redirect are directives that tell search engines which version of a web page is preferred, or rather which one should be indexed in order to limit multiple scans.
Now that you know what a canonical URL is and its importance in SEO, let’s talk about the ideal moments for its use and its implementation on a website. This is what we will see in the second chapter.
Chapter 2: Canonical tag – In what context to use it and how to implement it on a website?
The purpose of this second chapter is to:
- To break down the circumstances in which the canonical URL should be used;
- And to show techniques to easily and correctly implement canonical URLs on a website
2.1. When to use a canonical URL?
There are many occasions in which canonical tags should be used.

Here are a few essential ones:
2.1.1. When you need to self-reference a page
Even if you only have one version of a page, it is recommended to specify it as its own canonical URL. This is known as aCanonical self-referential URL.

In fact, the Google John Mueller confirmed that self-referencing canonical URLs could help your page perform well in search results.
<< I recommend this type of self-referencing normalization, as it tells us the page you want to index or the URL to use when indexing. >>
It is true that this is done automatically on most CMS, but it is prudent to know how to do it manually. This ensures that all link juices are redirected to the URL, regardless of program changes.
2.1.2. When you syndicate your content
Sometimes people publish exact copies of their content on other websites. This is called Content Syndication.

If you syndicate content to third-party websites, it is important to specify the original version with a cross-domain canonical tag.

This allows you to publish your content on other domains without any duplication problem.
In fact, Google can still choose to display syndicated content in search results, but this cross-domain canonical tag will help identify the original link and reduce the risk of syndicated content outranking the original.
Tip: You can ask sites that use your syndicated content to insert the Meta noindex tag. This will prevent search engines from indexing syndicated content on their site.
2.1.3. When you run an A/B test on your web pages
The a/B tests tests run a test by creating several versions of a page to see how users interact with each of these pages

Each page has its own variations. Among these, we have slight changes in the colors of various buttons or other significant changes as the content of the page
In such cases, Google may crawl all the pages and get confused. For this, use the link attribute rel = “canonical” on all your secondary URLs to indicate the original URL
This canonical URL will help search engines identify your preferred version.
2.1.4. When you have different variants of the same page
When the pages are slightly different, they are called duplicates (or near duplicates). I’ve talked about this before, but I’ll come back to it in a different context.

This is common on e-commerce websites. Let’s say you sell Gucci belts and have a red belt available in two different sizes: 34 and 36.
When selecting the different sizes, the URL changes. However, the content remains almost the same
Here is what the URLs will look like
Gucci red belt: example.com/belts/gucci/red/
Gucci red belt size 34: example.com/belt/gucci/red-34/
Gucci red belt size 36: example.com/belt/gucci/red-36/
The content is similar in all three URLs. It is recommended to define a canonical URL (pointing to example.com/belts/gucci/red/) for the other two URLs with the same content.
In fact, URL normalization is a common SEO practice for e-commerce websites, as it helps search engines index the main pages.
2.1.5. When two different contents have the same search intent
Let me help you understand this with an example
We assume you have an article on your blog that talks about SEO best practices in 2015.
Then, another one on the same topic that talks about Best SEO practices in 2020
Even though both the contents are totally unique, your wish would still be to have your users view the updated version
In such a scenario, you can use a canonical tag on the old blog post (from 2015) that will redirect bots to the new one (from 2020)
2.1.6. When you have separate desktop and mobile pages
When you create different pages for mobile and desktop with the same content, don’t forget to use the Canonical URLs and the Alternate URLs (a second URL)

They help convey the relationship between these pages to search engines. An alternate URL allows Googlebot to find the location of mobile pages on your website.

Now you know when to use a rel canonical tag. Now let’s see how to implement it correctly on your website!
2.2. Rel canonical tag: How to implement it correctly on your website?
There are five ways to specify canonical URLs, called canonical signals.
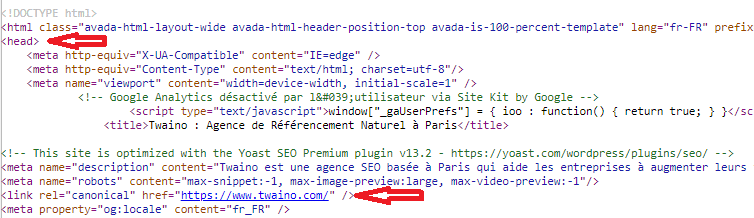
2.2.1. HTML rel = “canonical” tag
This is the most obvious and easiest way to specify a canonical URL. Simply add it to the section of the chosen page:


2.2.2. HTTP header
In some documents, like PDF files, there is no possibility to set the rel canonical in the page header, since there is no section. In these cases, you must use the HTTP header to place the canonical file.
2.2.3. Sitemap
Canonical URLs can be included in the sitemap.

However, non-canonical pages should not be listed on the sitemaphowever, non-canonical pages should not be listed on the sitemap, because search engines consider all pages included in the sitemap as canonical suggestions.
2.2.4. The 301 redirect
As you already know, using a 301 redirect (or permanent redirect) is a great way to divert traffic from a URL with duplicate or similar content to a canonical URL.
2.2.5. Configuration with Yoast SEO
With this WordPress Plugin, you have the ability to tweak the canonical URL of multiple pages.

Note that the Yoast SEO plugin has the habit of automatically configuring self-referencing canonical tags.
Now that you know the ideal circumstances for using canonical links and how to set them on your site, you need to implement some best practices and formally avoid some mistakes. This is what we will see in the following chapter.
Chapter 3: Canonical URLs: Good practices and common mistakes
In this chapter, we will discuss:
- Best practices for URL canonicalization;
- And bad URL canonicalization practices.
3.1 What are the best practices for URL canonicalization?
The canonical URL is a very powerful element in a webmaster’s toolbox
It is essential to follow the best practices below when working with canonical URLs to avoid indexing issues.
Here are eight important points to consider when canonicalizing a URL.
3.1.1. Use of absolute URLs
You should not leave any room for confusion as to which pages search engine spiders should index
It is advisable to use the absolute URL (full URL) which includes
- The protocol
- The domain;
- And the subdomain
In fact, John Mueller of Google says the same thing:

It should look like this

And not this:

This is because some web servers default to being misconfigured, which can make every page on your website accessible across all domains and subdomains
This causes a huge amount of duplicate content, which you should avoid at all costs.

However, having absolute URLs as canonical URLs prevents this type of duplicate content problem.
3.1.2. Placing the canonical rel in the section
As demonstrated above already, I again point out that the canonical URL should always be placed in the section of your page. This is one of the best practices for canonicalization.
If the canonical URL is not placed in the section, search engines will not be able to find and process it
3.1.3. Reference only indexable pages
The canonical URL must always reference an indexable page. I emphasize this point because search engines can get confused when the canonical URL references a page that is 301 redirected.

3.1.4 Include only the preferred version in the XML sitemap
I’m revisiting this term because it is among the most important canonicalization practices
All the pages you include in your XML sitemap are considered canonical. Based on the similarity of the content, Google decides whether the pages are duplicated or not
Therefore, if you have multiple URLs for a page, you should only specify the preferred URL for that page in the sitemap.
3.1.5. Using a single canonical tag per page
There should always be only one canonical URL on each page. If more than one canonical URL is defined, search engines may not find it
Google has stated that it will simply choose one of the canonical URLs and ignore the others when it encounters multiple canonical URLs on a page

Although we do not know how Bing and Yahoo handle multiple canonical URLs per page, it is recommended to use only one canonical URL per page.
3.1.6. Using the correct domain version (HTTPS vs HTTP)
In case you have switched to SSL, you should make sure not to declare a non-SSL URL (e.g. HTTP) as a canonical tag. Otherwise, this could cause confusion and unexpected situations
So, if you are on a secure domain, you need to make sure you use the next version of the URL :
Instead of:

If you mix https and http, it is confusing.
3.1.7 Using lowercase URLs
Google considers URLs to be case sensitive. That is, it treats upper and lower case URLs differently

To avoid confusion, you should stick to one version. However, the lowercase URL is recommended, as many people generally tend to link to this more traditional version.
3.1.8. Using self-referencing canonical tags
I had already talked about this in the section that talks about the context of using canonical URLs, but I’m endorsing it again because it’s part of the essential canonicalization practices
While self-referencing canonical tags are not mandatory, their use is recommended.
For example, if the URL were :

Thus, a self-referencing canonical URL would be :
Now let’s move on to common mistakes that are almost the opposite of good canonicalization practices.
3.2 Common mistakes or bad practices to avoid when using canonical tags
There are some mistakes you may make when you start with canonical tags

At first, they may seem minor, but the risk to your SEO downfall is huge
For this reason, I have compiled a list of mistakes that commonly occur when using canonical tags here.
Let’s start!
3.2.1. Not understanding that canonical tags exist for a single purpose
A lot of the problems encountered by beginners occur when they forget one important detail: The strategy is only to avoid duplicate content and nothing more!
With this in mind, avoid using the canonical tag for any purpose other than troubleshooting duplicate content, as the chances of facing new problems are very high.
3.2.2. Applying rel = canonical to the wrong places
For the technique to work, “rel = canonical” must be placed in the section. Otherwise, if the code is entered in the section, for example, search engines simply ignore the reference.
In addition to the technique not working, this can compromise the HTML structure of the page.
3.2.3. Blocked canonicalized URLs in robots.txt
When canonicalized URLs are blocked in the robots.txt filefile, the search engine robot will not crawl them. Thus, the canonical tags present on these pages will not be visible to the search engine bot
This type of error can harm your SEO, because the link juice from these pages will not be passed on to the canonical page

Therefore, do not block your canonicalized pages in the robots.txt file.
3.2.4. Noindex tag present on canonicalized pages
Never mix ‘noindex’ with rel = “canonical”, because these are two totally different orders

By putting a noindex tag on your canonicalized pages, you prevent Google from indexing them. This is a bad practice when using canonical tags
We know that canonicalization is implemented when a specific page among several is ranked in the SERP
Therefore, it is recommended not to use both noindex and canonical tags.
3.2.5. Canonization of all pages in the series paginated on the first page
The pagination breaks down your main page into a set of pages. Many e-commerce websites implement pagination on their category pages. Here’s an example:

A common mistake SEO professionals make is that they canonicalize all pages (page2, page3, page4, etc.) on the main page (page 1). Pages 2, 3 and 4 are not identical with page 1, so the “rel = canonical” in this case is incorrect
It is also recommended to use “rel = next” and “rel = prev” tags for your paginated pages. This will allow search engines to easily understand the correct order of the pages.
3.2.6. Having many rel = canonical tags
This major problem is encountered when pages include multiple rel = canonical links to different URLs. This usually happens when SEO plugins insert a rel = canonical link by default
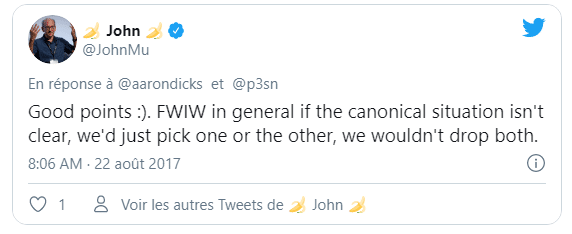
Previously, Google had stated that in case of multiple declarations of the canonical tag, all rel = canonical indexes will be ignored.
However, in a recent tweet by John Mueller (Google webmaster), he stated otherwise.

3.2.7. Canonical tags point to 4XX or 5XX pages
This error occurs when a canonical tag redirects to a page with status codes 4XX or 5XX (invalid page)

Sometimes it may happen that some pages on your website are deleted for various reasons. In this case, be sure to remove the canonical tags on all pages that link to these 4XX or 5XX pages

In fact, search engines do not index the wrong pages (4XX or 5XX) because they are inaccessible. They ignore any canonical tag pointing to these pages and end up indexing the wrong (non-canonical) version of them.
The best way to solve this problem is to replace all bad canonical URLs (4XX and 5XX) with valid ones.
3.2.8. Duplicate pages without indicating the canonical version
When one or more duplicate pages or similar pages do not have a canonical version, the search engines choose the appropriate URL and display it in the search results

This way it may not be the page you want to index.
3.2.9. Non-canonical URL in hreflang
This problem occurs when the hreflang tag on the page contains non-canonical URLs. If this tag is implemented on your website, make sure to add the correct canonical URL in the hreflang code.

Otherwise, search engines will not know which pages to consider for ranking. Therefore, if you encounter non-canonical URLs in hreflang, please replace them immediately with the appropriate canonical URLs.
3.2.10. The indication of canonical URLs in a chain
This error occurs when one or more pages specify a canonical URL that is also the main version of another page

This causes a “canonical chain” where page A defines page B (as main), and page B defines page C (as main).
These canonical strings confuse and mislead search engines, which could lead them to misinterpret or ignore the main canonical page.
To solve this problem, simply replace the canonical URL of page A which specifies the page B with a direct URL to page C.

3.2.11. Canonical URL loop
This error appears when the URL A defines the page B as the canonical version, but page B refuses and redirects to the URL A.

3.2.12. The Open Graph URL does not match the canonical standard
This is the mismatch between the specified canonical URL and the Open Graph URL on one or more pages. To resolve this issue, the Open Graph URL must be replaced on the affected pages with the canonical
Also, make sure that both URLs are:
- Identical
- Absolute;
- And use the protocol http: // or https: // protocol.
3.2.13. HTTP and HTTPS problems
I insist on this error because it is very common. Often, when some site owners switch from HTTP to HTTPSthey rarely think about fixing canonical tags
Although your website is now secure (HTTPS), the canonical tag tells Google that the HTTP version is still the preferred one. And having an HTTP version of a page, then specifying the HTTPS version as canonical is illogical.
3.2.14. Non-canonical pages generate natural traffic
Another major mistake is when one or more pages that are not canonical rise in search results and get natural traffic (which is abnormal).
This incident can be caused by:
- Improper configuration of canonical tags
- Ignoring the canonicalized page by the search engine
3.2.15. Non-canonical URLs in the sitemap
I had already talked about this in the best practices, but it is the opposite here. Google recommends excluding non-canonical URLs from the sitemap, as this can mislead search engines about which pages to index and rank.
To do this, make sure that the canonical version of the page is the only one included in the sitemap. This will ensure that the page is ranked in Google’s SERPs.
Now that you are aware of what is good and what is bad about using canonical tags, you need to move on to checking your website to see if you have already made any of the mistakes listed above. This will be discussed in the next chapter.
Chapter 4: Checking canonical tags and the limitations they display
As agreed, here are the two points I will touch on in this chapter:
- Checking your canonical URLs manually and automatically;
- Two limitations that the rel canonical tag displays.
4.1. How to audit canonical tags and issues on a website?
Let’s start with the manual check!
4.1.1. Manual checks
If you have a small website, you can manually check the compliance of canonical tags on your pages. To do so, follow these steps:
- Go to the page you want to check;
- I use this page from Twaino as an example;

- Press Ctrl + U so that the source code of the page is displayed;

- Search for “canonical” (Ctrl + F to display the search bar);

- You can find the canonical tag code in the section;

- Finally, make sure the canonical tag is implemented correctly.

Now let’s move on to the automatic verification which is easier and faster.
4.1.2. Using the tools
Manual verification can become tedious if you have a large number of pages on your website. For this purpose, you can use various scanning tools to check the implementation of canonical tags.
Ahrefs has its own site audit tool which gives you all the information you need about the canonical tags on your website.

You can also use Screaming Frog to audit canonical tags

It is much more detailed and resourceful. Just open the Screaming Frog Spider software and make sure to check “canonical” in the crawl settings. Once the exploration is complete, you’ll see all the details displayed under the Canonicals tabs

I can’t finish without mentioning the URL inspection tool of Google Search Console

This is a great platform for auditioning canonical URLs on a website.
While canonical tags have huge benefits, they are also limited in some ways. This will be discussed in the next section.
4.2. What are the limitations of the canonical URL?
Although canonical URLs are great, they also have some limitations.
4.2.1. Partial consolidation of link authority
Let’s take an example: The page A contains really good backlinks and refers to page B as canonical. Know that there is a good chance that search engines will give more credit to page B at the expense of page A.
Normally, each link conveys a certain authority, called link authority. The link authority that is passed to the A via strong backlinks is only partially transmitted to page B
I specify partially because this is a fuzzy point that the search engines have not been very clear about. There is no research showing that a canonical URL conveys all link authorities
We all know that the purpose of a canonical URL is to communicate to search engines which pages to consider and which pages to consider less
Therefore, my position on this topic is as follows: A canonical URL does not fully convey link authority. If you want to convey as much link authority as possible, I recommend using a 301 redirect.
4.2.2. Canonical URLs do not prevent crawl optimization problems
The main role of canonical URLs is to solve duplicate content issues. They tell search engines which pages to consider, not which pages to crawl. This is an important distinction to make.
Indeed, we talk about crawl optimization problems when search engines do not crawl the useful and important pages. There are many reasons why they may not crawl the main pages
They may:
- Get caught in endless redirect loops
- Spend more time crawling unwanted pages;
- Etc
This is a waste, especially since search engines have a so-called “crawl budget” (the time allocated forcrawling a Web site) for each website. The robots.txt file file can be used to avoid crawling optimization problems.
Chapter 5: FAQ about the canonical tag
5.1. Can misusing the canonical tag hurt my website’s SEO?
Of course YES! Mistakes when configuring this tag can have problems or even major problems on the referencing of your site by search engines.
5.2. Being a beginner, what is the easiest way to implement a canonical tag on a website?
As the easiest way, you have two possibilities:
- The first option is to configure the tag with the Yoast SEOplugin, if you are a WordPress user. This plugin works on an automatic basis.
- The second option is to use an sEO agency agency that will do everything for you to get the change you are looking for.
5.3. What causes canonical SEO problems?
Canonical problems most often occur when a website has more than one URL that displays similar or identical content
They are often the result of a lack of proper redirects, although they can also be caused by search parameters on e-commerce sites and syndication or publishing of content on multiple sites.
5.4. Why are canonical issues a threat to a website’s SEO?
There are several reasons:
First, Google does not want to include duplicate content in its index. So when it discovers duplicate pages, it selects a canonical (default) version of that page and excludes all other versions of the page from its search results. This can be a problem if Google selects a URL that is not the URL you prefer to index.
Here’s a great video from Google’s John Mueller explaining how the search engine selects a canonical URL when multiple URLs on a site display the same or similar content
https://youtu.be/8j_hxBw5B4E .
Second, if your content is accessible via multiple URLs, other sites may link to different URLs when they cite your site’s content. This diversifies your link value across multiple pages, diluting it
In summary
Finally, just keep in mind that canonical tags are not a guideline, but a signal to search engines.
Using them on your site is the best way to tell Google or other search engines your preferred version among a set of almost identical pages
Now you know everything about a canonical URL. Take advantage of its power to help your pages perform well in search results.
See you soon!