Search engines are constantly making improvements to their system. Google, on the other hand, implements more than 500 changes to its algorithm each year.
So much so that today , it would be more relevant to speak of “the” algorithm is from Google.
Luckily for SEO, most of these changes are virtually imperceptible due to their subtleties.
Indeed, most of the changes have too little impact to be seen in the SERPs.
But Google is experiencing some major improvements whose effects are clearly noticeable. These include RankBrain, the existence of which was publicly announced in an article by Bloomberg, October 26, 2015.
Although its exact rollout date is unknown, this update officially marked the use of Artificial Intelligence (AI) in products Google’s
A few years after this announcement, RankBrain remains partly a mystery as to how it works. Indeed, Google does not seem to want to reveal the secrets of its system.
This situation has given way to speculation and heated controversy in the SEO community.
This is why following my extensive research, I decided to write this article which will try to shed some light on RankBrain. As a bonus, you’ll have the opportunity to learn how user experience (UX) signals fit into Google’s ranking process.
To write this article, I relied on many different sources to support my point. In particular, you will see several assertions coming directly from Google and its engineers.
So, that sharp analyzes from some SEO industry experts to have a perfect understanding of RankBrain and UX.
Chapter 1. What is RankBrain and Why does Google use it?
1.1. What is RankBrain?
The existence of RankBrain became known to the public on October 26, 2015 thanks to the Bloomberg:
The title translated into French looks like this:
“Google moves from lucrative web search to artificial intelligence.
Through the announcement, Google clearly indicates the implementation of artificial intelligence in its system, which the company will name RankBrain.
Rankbrain is a machine learning machine that Google uses to process its search results.
It is a product of article intelligence (AI) that allows computer programs to perform tasks that only humans are capable of performing with their intelligences or mental processes.
As you can imagine, Google created RankBrain with this technology to improve the results it provides to its users.
But before we get into understanding how Google uses RankBrain, it’s a good idea to first understand what AI is.
1.1.1. What are AI and machine learning machines?
According to Larousse, artificial intelligence (AI) is:
“The set of theories and techniques implemented in order to produce machines capable of simulating intelligence”.
In other words, AI aims to enable computers to become as intelligent as humans through mathematical and statistical approaches.
In other words, they will be able to:
Learn through experience;
To organize their memory;
To reason in order to solve problems on their own.
Artificial intelligence is generally mentioned to refer to computer programs that are designed in this way. So how does this work in practice?
In 2015, Google held the “Machine Learning 101” event to explain how machine learning machines work.
Source : MartchToday
This event took place on its campus in Mountain View and was hosted by several Google experts.
Danny Sullivan who was a journalist and analyst held a “live-blogging” to reveal the most important points of the event.
But first, who is Danny Sullivan and what makes me consider his words?
Rating: In my article, I considered the comments of several people that I nevertheless took the trouble to present so that you can form an opinion on the degree of credibility of the information.
Danny Sullivan has been a Googler since October 2017 and his role is to help the public better understand the Google search engine.
Before joining Google, he was a journalist and analyst in the sphere of web marketing and search engines.
A particularly credible source, isn’t it?
Let’s go back to his “live-blogging” that he held on the “maching learning 101” organized by Google.
It turns out that the system of machine learning machines consist of three main parts:
Model : The system that makes predictions or identifications.
Parameters : The signals or factors used by the model to form its decisions.
Learner : The system that adjusts the parameters – and in turn the model – by examining the differences between predictions and actual results.
It must be admitted: it is quite difficult to digest!
Even Danny makes it known in his article on the subject:
To put it simply, everything starts from a model that the machine will use for its learning. Generally, this model is introduced by a human from certain data.
The machine will use the model and the data to train or solve practical tasks that do not fall outside the scope of its model.
Once the model is assimilated by the machine, it will be possible to provide it with new data or problems to be solved which do not necessarily follow the predefined model.
The machine will attempt to solve these tasks for which it was not programmed by trying several approaches.
According to the feedback on the quality of its answers or results, the program readjusts the parameters and then the model.
Source : Martechtoday
This process is continuous, which implies that machine learning machines are constantly learning, if they are active.
Ultimately, machine learning is where a computer or automatic program teaches itself to do something, rather than being taught by humans or following detailed programming.
It is for this reason that Paul Haahr, a Google engineer, claimed that the firm does not fully understand RankBrain:
Indeed, Google knows how its tool works, but does not always know what it does. As some experts still seem to confirm in the Search Engine Roundtable article:
Google doesn't quite understand what RankBrain is doing says @haahr#smx
Check out this article where Danny details a concrete example given by Greg Corrado,the senior at Google who announced the existence of RankBrain in the Bloomberg article:
You also have Wikipedia which gives lots of details and reference on machine learning .
However, you will have all the information and concrete examples that can help you understand how RankBrain works.
1.1.2. What is the relationship between RankBrain and Google’s algorithms?
RankBrain is part of Google’s global search algorithm: Humminbird.
The company Moz confirms this in its article on Google Hummingbird:
“Unlike previous Panda and Penguin updates which were initially released as add-ons to Google’s existing algorithm, Hummingbird was cited as a complete overhaul of the main algorithm.“.
Moreover, Danny Sullivan confirms this in his article on Hummingbird:
He uses this metaphor:
“It was as if the engine had a new oil filter or an improved pump. Hummingbird is a completely new engine, although it continues to use some of the same parts of the old one, like Penguin and Panda”.
To know the evolution of Google since its beginnings, until Hummingbird, you can follow this presentation of the googler Amit Singhal:
Indeed, it will be with Hummingbird that Google will be able to put more emphasis on natural language queries. And this, taking into account the context and the meaning of the request as a whole rather than the words taken individually.
Google’s complete algorithm is Hummingbird and RankBrain should be considered as part of it.
This conclusion is drawn from the Bloomeberg in which Greg Corrado clearly indicated that RankBrain only handled the 15% of queries that Google’s system had never yet processed.
Google’s machine learning was only taking part of the system’s queries. Unlike the central Hummingbird algorithm which is supposed to handle all search engine queries.
It becomes legitimate to wonder what place RankBrain occupies in the Google algorithm.
1.1.3. RankBrain is the third most important signal
“In a few months, RankBrain has become the third most important signal contributing to the result of a search query.?
That being said, what are the other two most important signals from Google
The answer to this question was given by Andrey Lipattsev from Google:
He says in the previous podcast:
“I can tell you what it is. It’s about the content. And links pointing to your site.“.
Therefore, the three most important Google ranking signals are:
Backlinks;
The contents ;
RankBrain.
There is no precision on the order of importance of each of these signals. We cannot therefore make a classification as such.
Nevertheless, it proves that it is very important to understand how this Google machine learning works. And this, in order to develop effective strategies to optimize the referencing of your website in the SERPs.
At this level, it is legitimate to wonder why Google launched RankBrain.
1.2. Why did Google launch RankBrain?
I basically deciphered two main reasons why Google launched its machine learning.
These are:
Google’s difficulties in interpreting queries it had never processed;
That Google had to hand-code its algorithms to make any changes.
1.2.1. Google’s difficulties in interpreting requests
Since its creation, Google has always tried to improve in order to determine precisely what its users wish to have as answers.
In its early days, the search engine relied mainly on the presence on the web pages of the words present in a query to display its results.
For example, if you search for “buy fruits and vegetables”, the search engine will take care of providing the pages that contain these words.
Moreover, the slightest variation in the expressions used could lead to different results.
For example, the search engine could not give the same results for “clothing” and “clothing”. The same goes for the queries “best garden boots” and “best garden shoes”.
Results could vary dramatically with simple query-level tweaks.
Thus, the search engine itself considered that there was room for improvement in order to give the best results to its users.
But the problem does not stop. Because this operation has given the opportunity to certain “black hat” SEOs to repeat words and expressions in their content to find themselves at the top of the results. And this, even if their content is of poor quality.
Google has come a long way since then. The search engine now manages to detect and punish websites that use Black Hat SEO including Penguin and Panda algorithms.
On the query side, Google has also made great progress.
Indeed, the search engine is increasingly able to understand the queries, and to associate them with each other if they mean the same thing:
The best garden boots:
The best garden shoes:
The engine tries to understand what you search or search intent, as a human would. But to get there, Google has made several contributions to its system.
Hummigbird, Stemming, and the Knowledge Graph epitomized Google’s shift to viewing words as “entities” and not just a composition of characters.
En effet, Google a adopté Word Stemming en 2003 afin d’appréhender les variations d’un same mot. Par exemple, Google comprend que « mangue », « mangues » et « manguier » veulent sensiblement dire la same chose. Ce qui lui permet de donner des résultats similaires pour ces termes.
Google ne s’arrête pas à la variation des mots et arrive à déterminer le « synonyme » des mots. Le moteur de recherche arrive à faire des passerelles entre les termes, par exemple avec « SEO » et « référencement naturel », dans la mesure où les résultats seront proches, voir sensiblement les sames pour ces requêtes.
Le Knowledge Graph, quant à lui, a été un moyen pour Google de devenir encore plus intelligent en ce qui concerne les relations entre les mots.
The Knowledge Graph, meanwhile, was a way for Google to get even smarter when it comes to word relationships.
The search engine has learned to search for “things, not strings,” as Amit Singhalof Google describes it:
“Take a question like [taj mahal]. For more than forty years, search has essentially been about matching keywords to queries.
For a search engine, the words [taj mahal] were just that – two words. But we all know that [taj mahal] has a much richer meaning.
You might think of one of the most beautiful landmarks in the world, or a Grammy Award-winning musician, or maybe even a casino in Atlantic City, NJ.
Or, depending on when you last ate, the nearest Indian restaurant.
That’s why we worked on a smart model – in geek parlance, a “graph” – that understands real-world entities and their relationships to each other: things, not strings.“
strings” used here essentially refers to the processing of searches using only strings of letters.
For example, the results will show pages that contain the exact word “Paris” when a user makes this request.
The “things” means that instead Google understands that when someone searches for “Paris” they probably mean the capital of France, an actual place with links to:
Other places;
Landmarks;
Activities ;
People ;
Etc…
The Knowledge Graph is a database of things in the world and the relationships between them.
That’s why you can do a search like “construction date of the tallest monument in paris” and get an answer on the “Eiffel Tower” like in the image below, without ever using the name:
But while the Knowledge Graph relies on existing databases to see the connections between concepts, RankBrain learns how users connect words and concepts when searching.
1.2.2. RankBrain allows Google to process certain types of queries
During the announcement in the Bloomberg article, Greg Corrado claimed:
“Over the past few months, a “very large fraction” of the millions of queries per second that people enter into the company’s search results are interpreted by an artificial intelligence system […]
If RankBrain sees a word or phrase that it does not know, the machine can guess which words or phrases may have a similar meaning and filter the result as a result, making it more efficient in handling never-before-seen search queries.“.
From his assertion, it can be said that RankBrain makes it easier for Google to process queries that its users have never searched before.
Indeed, the search engine must constantly deal with queries that no one had ever searched before.
Statistics show that around 15% of daily queries on Google have never been searched. What Google confirms in its blog in 2017:
“There are trillions of searches on Google every year. In fact, 15% of the searches we see every day are new, which means there’s always more work to be done to present people with the best answers to their questions from a wide range of legitimate sources.Currently
the search engine handles 5.8 billion queries per day. If 15% are not known, there are nearly 870 million completely new queries that the search engine must answer.
While most queries have never been searched before, clearly Google had to start from scratch to understand what people are looking for.
Moreover, most of the searches we carry out do not contain the exact expressions concerning what we are looking for. We like to let Google guess the information we’re looking for, don’t we?
Know that before, the search engine really had trouble guessing what its users wanted.
This is why RankBrain was launched in 2015 and to try to give effective solutions to these kinds of queries. We will see in the next chapter how it works in practice.
For now, keep in mind that Rankbrain works well for linking a query it’s already processed to a new query it doesn’t yet know about.
For example, suppose a lot of people search for “build a garden shed”.
With the collected data RankBrain understands that a “garden shed” is a kind of building.
At your level if you search for “build a garden building”, which in our example will never have been searched on Google before (of course this example is not real).
Google will not necessarily show you pages that include the words:
Build;
Building ;
Garden.
You have such a result:
Google understood that you were looking for how to build “a garden shed” and not “a garden building”, as a human would have done!
The same goes for this particularly insane query made up of 18 words:
And
Although the first keyword is not very specific, I have essentially the same results with the second which is made up of only one word.
18 words might seem like a lot, but RankBrain is also better at handling long queries.
Indeed, Gary Illyes states that RankBrain is:
“works best for long-tail queries and queries that we haven’t seen before.“.
Indeed, 64% of searches are made up of 4 words or more:
Internet users use specific phrases that describe what they want as an answer:
If managing a handful of words could be a problem for Google, there is no doubt that the difficulty will increase if the number of words increases. Another factor to consider is the voice search rapidly evolving
Source : Justcreative
Statistics show that by 2020, 50% of searches will be voice-based.
However, users use more words when they perform a voice search:
These conversational searches are more like the way people speak naturally.
This means that it is very important for search engines to understand:
The most important words in a query;
What the words actually mean when combined.
It is in this logic that Google developed its automatic learning machine “RankBrain” which was first used to better understand user queries.
Gary Illyes makes this clear through one of his Twitter:
“Let me try to explain one last time: Rankbrain gives us a better understanding of queries..
Lemme try one last time: Rankbrain lets us understand queries better. No affect on crawling nor indexing or replace anything in ranking
— Gary 鯨理/경리 Illyes (so official, trust me) (@methode) March 18, 2016
Any changes Google makes to its system are generally aimed at improving the experience of its usersRankBrain is no exception to the rule and its launch allowed the firm to solve another problem.
1.2.2. Google coded its algorithms by hand
Before launching RankBrain, Google coded all of its algorithms by hand.
This remark was made by Brian Dean in his article on RankBrain.
But first, who is Brian Dean?
Brian Dean is an SEO expert and the founder of Backlinko:
His awards and accolades say a lot about him:
Brian says Google engineers were responsible for making all the changes to his system.
This infographic allows you to understand the process:
But with the arrival of RankBrain, things have changed since it takes care of testing and implementing the changes itself:
Of course Google engineers continue to work on the algorithms of their system.
But RankBrain can do some of the work by adjusting the results it suggests itself. Indeed, once it offers results to users, it evaluates the success of what it has proposed.
In the event that the results have satisfied the intention of the users, the modifications are maintained.
Otherwise, the old configuration or algorithm is reactivated.
So, is RankBrain more efficient than Google’s human engineers?
Greg Corrado said that to determine the best option between its human engineers and the machine, the firm carried out a test.
They asked a group of experts and RankBrain to identify the best pages on certain queries.
The result is conclusive since the automatic learning machine achieves more performance with a prediction accuracy of more than 10% than that of the experts:
The results are conclusive and RankBrain seems to perform the tasks for which it was created excellently. Now, how does Google’s AI actually work?
Chapter 2: How does RankBrain actually work?
2.1. You are the teacher and RankBrain is your student
To easily understand how RankBrain works, I will use an example.
Imagine that a student takes a daily test consisting of 5.8 billion questions, written by millions of teachers.
Each teacher gives feedback after the student has answered a question. He lets the student know:
That’s perfect: The first answer is the right one!
It’s not perfect yet: The best answer is a little further down;
No, you didn’t answer my question: I was asking this instead.
The student remembers feedback from all his teachers for tomorrow’s test, where only 15% will be unknown questions.
By analogy, the student represents RankBrain well and each person who searches on Google is one of his teachers.
Let’s try to see how Google could use its AI.
2.2. How RankBrain works?
As we’ve seen before, Google engineers had to manually program Google’s algorithms to do things differently.
RankBrain, on the other hand, learns directly from how we interact with its results.
Gary Illyes describes it this way:
“[RankBrain] looks at data on past searches and based on what has worked well for those searches, it will try to predict what will work best for a certain query. This works best for long-tail queries and queries we’ve never seen..
Therefore, the system is completely autonomous and does not need to be told that such a result is bad and that the problem must be solved in such a way
RankBrain already has criteria, including other ranking signals, that allow it to know whether a result perfectly answers a query or not. Which I will describe in the next chapter.
He has a large database of old search results that help him make good decisions.
This is the main reason why RankBrain performed better than Google engineers.
RankBrain predicts what will work best, tests it, and if the change works, it sticks with it.
RankBrain doesn’t just stop at improving organic results as it is also able to fine-tune results on Google Suggest.
2.3. Does RankBrain affect suggested searches?
Moz speculated that RankBrain also uses certain factors to deliver relevant results:
“Pre-RankBrain, Google used its core algorithm to determine which results to display for a given query.
Post-RankBrain, the query is believed to now pass through an interpretation model that can apply possible factors like searcher location, personalization, and query words to determine the searcher’s true intent.
By discerning this true intent, Google can provide more relevant results.Othertinkgroup step further and shows a scenario where RankBrain could play a role in Google Suggest. I will give an example similar to what they gave.
Suppose I would like to do a search for “Antoine Griezmann” French player of France Football.
I enter the first two letters “an” of the first name “antoine”, Google displays the suggestions:
You can see that there is no “Antoine Griezmann” in the suggestions.
I stop at this level for the moment and I will first search for “French football team”:
Then I enter the first two letters of Antoine “an”:
You can see that “Antoine Griezmann” is now part of the recommendations. Even if it is not in first position, it is nevertheless part of the suggestions.
So far, I have not yet made a request for the name “Antoine Griezmann”.
The same thing happens for “Kylian mbappé” when I insert the first two letters “ky”:
It is important to note that Google understands the relationships between things well enough to guess what you will be looking for when you want to do a next search . What does this mean for an online business?
Let’s say you’ve written authority content on “building backlinks”.
Your guide offers immense added value to users. When your readers go back to the search bar after finding what they need, Google will suggest related searches.
The search engine could give them another opportunity to interact with your brand, your content, and ultimately your product. It’s rather interesting, isn’t it?
But is it the work of RankBrain? It is not certain.
It is possible that this is not the work of RankBrain but rather another way for Google to use AI in its system.
Either way, it’s a way for Google to clarify the searcher’s intent.
Wired reported in 2016 the words of Google CEO Sundar Pichai:
“Machine learning is a fundamental and transformative way in which we are rethinking the way we do everything. We apply it thoughtfully across all of our products, whether it’s search, ads, YouTube, or Play. And we’re still in the early stages, but you’ll see that we’re consistently applying machine learning in all of these areas.know
that RankBrain focuses on the search intent behind the words we put in the search bar.
But if Google also incorporates machine learning into everything it does, it would be misguided to assume that RankBrain is impacting Google Suggest.
That being the case, let’s now go back to what we know for sure.
RankBrain tries to understand queries by evaluating how well past SERPs have satisfied searcher intent. Machine learning then uses this data to make predictions about what people are really looking for for the query.
These predictions come from RankBrain’s vast understanding of how words are related to each other. Which brings us to the notion of word vectors.
2.4. What are word vectors?
We have already seen that Google uses the Knowledge Graph to connect words to concepts that exist in relation to each other.
But it only works with the information that is present in its database. To go further with machine learning, Google turned to word vectors since it needed to learn the hidden meaning behind words:
Word vectors or word vectors are how learning machines automatically from Google or RankBrain learn the new relationships between words.
The Bloomberg confirms this fact:
“RankBrain uses artificial intelligence to embed large amounts of written language into mathematical entities – vectors – that the computer can understand. If RankBrain sees a word or phrase it doesn’t know, the machine can guess which words or phrases may have a similar meaning and filter the result accordingly, making it more efficient at handling never-before-seen search queries. .“.
For this to be effective, Google has developed an open source tool called “Word2vec“:
This tool uses machine learning and natural language processing to understand for itself the real meaning of words.
In its article on word2vec, Google shows an example of how it can learn the concept of country capitals.
The firm says:
“Word2vec uses distributed representations of text to capture similarities between concepts.
For example, it understands that Paris and France are related the same as Berlin and Germany (capital and country), not the same as Madrid and Italy
This table shows how well he can learn the concept of capital, just by reading a lot of articles topical, without human supervision”.
Schematically, this is how word2vec understands concepts by making connections between them.
RankBrain uses the same system to determine relationships between terms and content on the web in order to make predictions for queries it does not know.
This is the reason why, Google does not indicate a particular way to optimize a site for RankBrain. Indeed, RankBrain is not a “classic algorithm” like Panda and Penguin.
We know how to avoid Penguin penalties and thanks to the guidelines, we know how to satisfy Panda.
RankBrain on the other hand is an interpretative model for which one cannot perform specific optimization.
Google’s only recommendation is to write your content in natural language so that users get as much added value as possible. We will discuss this aspect in the next sections.
There is a question that is still very important to understand how RankBrain works.
2.5. How RankBrain evaluates the results it offers?
Google’s machine learning machine uses old data to try to predict the best future outcomes.
Danny Sullivan states in his article:
“Everything RankBrain learns is offline, Google told us. It takes lots of historical research and learns to make predictions from it.
These predictions are tested, and if they prove to be correct, then the latest version of RankBrain is released. Then the cycle of e-learning and testing is repeated.things
happen like this, how does RankBrain manage to decide whether the result it gives is good or bad?
One would assume that there is a RankBrain score like that of PageRank.
But this is not the case !
On this subject, there have been many rumors that RankBrain gives a score to the pages in order to know what to propose next.Google has had the opportunity to answer this question many times. During the SMX Advanced, Danny Sullivan had an interview with Gary Illyes:
Asked if there is a score, Gary says there is not:
In French:
“Danny Sullivan: Is there a RankBrain score? Gary Illes: You don’t have a score. I think the root of your question is whether you can optimize for RankBrain – (Laughs)”.
If there is therefore no score or a rating system, how does RankBrain manage to determine user satisfaction in relation to its results?
Some SEO experts believe that RankBrain uses UX or user experience signals to make its decisions. Is that the case ?
Whether RankBrain uses user-related signals to perform its rankings is a controversial topic within the SEO community.
While some SEO experts believe that UX or user experience is not considered by RankBrain, others show that it is an important factor to consider.
It is difficult to get a definitive answer on the subject. Especially since Google does not seem to want to give informed and definitive explanations.
But I propose to dissect this problem step by step. Let’s first answer the question of whether Google takes user experience into account when making its rankings.
Chapter 3: Can UX affect the ranking of websites in the SERPs?
Above all, I think it is wise to see what factors are related to user behavior.
In my article on the overbidding technique, I had the opportunity to talk in detail about the metrics concerning the user experience.
This can be summed up perfectly with these images:
The question of whether Google takes into account user experience signals to rank websites is also controversial in the world of SEO.
I will try to answer the question with opinions from Google on the subject and some studies carried out by some giants of the SEO industry.
3.1. Google considers UX for its
3.1.1 ranking. Google considers users to be the most reliable judges
In 2015, Google issued a patent on the subject of “Altering the ranking of search results based on implicit user feedback and a model of presentation bias”:
Google states:
“For example, user reactions to particular search results or lists of search results can be measured, so results that users click on often will rank higher.
The general assumption of such an approach is that search users are often the best judges of relevance, so that if they choose a particular search result, it is likely to be relevant, or at least more relevant. than the alternatives presented.“
« Par exemple, les réactions des utilisateurs à des résultats de recherche particuliers ou à des listes de résultats de recherche peuvent be mesurées, de sorte que les résultats sur lesquels les utilisateurs cliquent souvent seront mieux classés. L’hypothèse générale d’une telle approche est que les utilisateurs de recherche sont souvent les meilleurs juges de la pertinence, de sorte que s’ils choisissent un résultat de recherche particulier, il est susceptible d’be pertinent, ou au moins plus pertinent que les alternatives présentées. ».
This Google patent clearly shows that “user reactions” can be measured and can also affect ranking in the SERPs.
Nevertheless, I will not jump to a conclusion and will take the time to dig deeper.
3.1 2. Search Engines May Collect Cursor Movement Information
Although Google is the search engine with the largest market share, it is possible to get some clues from other entities
. Microsoft which manages Bing has published an article on: “Improving Search Patterns Using Mouse Cursor Activity”:
The company shows:
“Just as clicks provide relevance signals in search results searching, hovering, and cursor scrolling can be additional implicit cues.We find that cursor hovering and scrolling are cues that tell us which search results have been reviewed, and we use these interactions to reveal latent variables in search patterns to more accurately calculate consumer attraction and satisfaction. documents. Accuracy is assessed by calculating how well our model using these parameters can predict future clicks for a particular query. We are able to improve click predictions against a baseline search model for top-ranked search results by using additional log data. “.
Although it is a bit difficult to understand the stakes of a few terms, it is possible to understand the message that this article conveys.
Microsoft seems to be able to know the movement of the cursor of its users and then predict the results that will be clicked.
Is Google able to do the same? I think there is no doubt that the most popular search engine is able to have this same data and act accordingly.
3.1.3 Google can know the time spent on a given article
Let’s stay within the framework of patents and see what other data Google is able to know.In
2015, the search engine Google published a patent entitled: “Methods and systems for improve a search ranking using item information”.
It reads:
“Duration data may include, for example, the time the user spends on an article, such as a web page. Additionally, duration data may include the time the user spends on an item, such as a web page hosted by another web page. For example, the time a user spends on www.google.com/search/images.html can be attributed, in part, to the time spent on the host www.google.com. Access data may include, for example, the number of times the user views an article or opens and enters or interacts with an article […] Web pages that are viewed for significantly longer may be assigned ratings of higher ranking. By determining how long a web page is viewed, the present invention can determine, among other things, whether scrolling or other activity is performed on a page to indicate that the user is actually viewing the page and has not simply left a webpage open while doing another activity.
Here it is the time spent on the web page of a website. The more time users spend on your website, the more your pages will tend to rank better.
What other data can Google collect?
I think the search engine can have access to a lot of information about user behavior in order to come up with relevant results.
So how can they collect user information?
3.1.4. Google is able to collect data from its users through browsers
In 2012, Google published another patent titled: “Classification of documents based on user behavior and/or characteristic data”:
Le moteur de recherche indique :
« Les données relatives au comportement de l’utilisateur peuvent be obtenues à partir d’un navigateur Web ou d’un assistant de navigateur associé à des clients. Un assistant de navigateur peut inclure du code exécutable, tel qu’un plug-in, une applet, une bibliothèque de liens dynamiques (DLL), ou un type similaire d’objet ou de processus exécutable qui fonctionne conjointement (ou séparément) avec un navigateur Web. Le navigateur Web ou l’assistant de navigateur peut envoyer au serveur des informations concernant un utilisateur d’un client. »
The search engine indicates “
aweb browser or browser assistant associated with clients. A browser helper may include executable code, such as a plug-in, applet, dynamic link library (DLL), or similar type of executable object or process that works in conjunction (or separately) with a Web browser. The web browser or browser assistant can send information about a user of a client to the server.»
Google is able to collect user data through browsers.
What web browsers are these? I can’t say, but what is obvious is that Chrome, which is the company’s browser, is certainly part of it.
Google goes further in its explanation:
“For example, the Web browser or the browser assistant can record data concerning the documents which the user accesses and the links in the documents (if any) selected by the user. Additionally, or alternatively, the web browser or browser assistant may record data regarding the user’s language, which may be determined in a number of ways that are known in the art, such as analyzing the documents to which the user has access. Additionally, or alternatively, the web browser or browser assistant may save data regarding the interests of the user. This can be determined, for example, from the user’s favorites or bookmark list, topics associated with the documents the user is accessing, or other ways that are known in the art. Additionally, or alternatively, the web browser or browser assistant may record data regarding query terms entered by the user. The web browser or browser assistant can send this data for storage in the repository.
Browsers are an alternative for search engines to collect user information.
At this stage, there is no longer any doubt that Google is able to use UX to influence the ranking of websites in search engines.
Now let’s see to what extent signals from user behaviors can be used.
3.2. How does Google use UX signals in its rankings?
3.2.1. Google uses UX signals indirectly
Eric Enge and Gary Illyes of Google discussed this topic at SMX Advanced 2016.
But first, who is Eric Enge?
Eric Enge is a high-level SEO expert who had to publish the Book “The Art of SEO“, considered one of the bibles of English-speaking SEO.
He has obtained several awards and distinctions that you will find on his LinkedIn:
It is obvious that this is a source that can be considered reliable on questions related to search engines.
Here is a video of the interview that Gary Illyes of Google and Eric Enge at Pubcon:
Indeed, the two experts had to discuss how Google can consider user signals as factors of ranking.
Eric indicates that the same topic was discussed between him and Paul Haahr at SMX West in 2016:
In his article, Eric states that according to the latter:
“Google uses these signals as an indirect ranking factor“.
The concept can be represented this way:
In the words of Eric:
“Over time, this type of feedback loop will cause the pages that get the highest engagement rate (including the highest CTR higher) will move up in search results. The subtlety of what Haahr said is that Google obviously doesn’t directly measure engagement signals. Instead, they tune their use of other signals so that pages with higher engagement are moved up the rankings.»
Can UX affect rankings?
Even if it is indirectly, this is confirmed once again with Google employees.
But let’s not stop at these assertions and consider the contributions of Gary Illyes.
Rating: In order to keep intact the idea that the googler is trying to convey, I will only translate the comments reported by Eric:
“Many parties disputed this assertion of Google and, for this reason, I asked Gary what he thought of it.
Here’s what he shared:
1. User signals, like CTRs, tend to be very noisy on the web, and Google doesn’t find them reliable.
2. In a controlled environment, they work quite well, and Google uses them that way. (For the rest of this point, I’ll extrapolate a bit from Gary’s comments). To do this, they run sample tests to gauge the quality of the search (Gary suggested they could sample 1% of users). Based on the results of these tests, they rate the quality of their core algorithms. Depending on the results, Google may adjust its factors and reassess the situation.
Executing this type of continuous QC/QA process will indeed cause posts with a high CTR to rise across the SERPs.
« De nombreuses parties ont contesté cette affirmation de Google et, pour cette raison, j’ai demandé à Gary ce qu’il en pensait.
Voici ce qu’il a partagé :
Les signaux utilisateurs, comme les CTR, ont tendance à be very bruyants sur le web, et Google ne les trouve pas fiables.
Dans un environnement contrôlé, ils fonctionnent assez bien, et Google les utilise de cette manière. (Pour le reste de ce point, j’extrapolerais un peu à partir des commentaires de Gary). Pour ce faire, ils effectuent des tests d’échantillonnage pour évaluer la qualité de la recherche (Gary a suggéré qu’ils pourraient échantillonner 1 % des utilisateurs). Sur la base des résultats de ces tests, ils évaluent la qualité de leurs algorithmes de base. Selon les résultats, Google peut ajuster ses facteurs et réévaluer la situation.
L’exécution de ce type de processus continu de QC/QA entraînera en effet une montée des postes ayant un CTR élevé dans l’ensemble des SERP.
1. The main problem with using engagement signals like CTR as a direct driver is that the sporadic nature of CTR would likely cause wild movements in the SERPs at times, and that’s not necessarily desirable (yet once I extrapolated a bit).
2. In a controlled test environment, Google can recognize bad datasets and simply discard them, giving them much better control over the outcome.
3. CTR is one of the things looked at in this way, but there are other factors as well.»
Does click-through rate or CTR affect page rankings? Yes! But not directly as many SEO experts think.
Moreover, it seems that UX signals do not always have the same weight.
3.2.2. UX signals are used to different degrees
User behavior data is used to different degrees in different metrics.
In its 2015 published patent on “Methods and Systems for Improving Search Ranking Using Item Information,” Google writes:
“The ranking processor determines a ranking score based at least in part on behavioral data customer, retrieved from the customer behavior data processor, associated with the nth article. This can be accomplished, for example, by a ranking algorithm that weights the various customer behavior data and other ranking factors associated with the query signal to produce a ranking score. Different types of customer behavior data can have different weights, and those weights can be different for different applications. In addition to the customer behavior data, the ranking processor may use conventional methods to rank the articles according to the terms contained in the articles. It may further use information obtained from a server on a network (for example, in the case of web pages). The ranking processor can request a PageRank value for the web page from a server and use this value to calculate the ranking score. The classification may also depend on the type of article. Ranking can also depend on time, such as time of day or day of week. For example, a user may typically work and be interested in certain types of articles during the day, and be interested in different types of articles during the evening or on weekends. “.
Although it has technical terms, it is easy to understand that Google does not give the same weight to user signals for all queries.
Depending on the queries, certain UX signals may have more impact on ranking than others.
We now know that Google uses user signals to make its rankings. Even if it is indirectly, UX has an impact on rankings.
To close this topic, I suggest you consider some industry studies
3.3 Industry studies showing correlations between UX metrics and position in SERPs
3.3.1 WordStream studies
WordStream is an online advertising company founded by Larry Kim:
Larry maintains a good reputation in digital marketing and has 17 awards and distinctions:
Is he a reliable source? I can say yes!
Larry conducted some studies in 2016, so long after the launch of RankBrain, to determine if there is a correlation between certain user experience signals and the position of websites in search engines.
You can find his article on Moz and as he himself points out, the figures from these studies should not be set in stone. Remember that Google can vary the weight of signals depending on the queries.
Here, Larry says,
“We’re only looking at the numbers for a particular vertical. The expected minimum commitment will vary by industry and query type.“.
That said, this is an excellent study!
Factor 1: Click through rate or CTR is correlated with position in SERPs
Gary acknowledged that CTR can indirectly influence ranking in SERPs
. To clarify things, Larry conducted a study based on 1,000 keywords which allowed him to have such a graph:
There is a strong correlation between the click rate and the position in the SERPs. the type of keyword short or long tail.
The same observation was made by Rand Fishkin of Moz who conducted a simple study. He asked people to carry out a particular search and click on the link of his blog which occupied the 7th position:
Source : Sparktoro
In the space of a few hours, its web page found itself in the first position of the SERPs:
Source : Sparktoro
At this stage, it would still be difficult to have uncertainties on the Influence of click-through rate on ranking in SERPs
Factor 2. : The Bounce Rate has an impact on the organic position
The bounce rate or design rebound rate when someone visits a page and presses its back button without clicking on anything on the page.
Officially, Google does not admit to using the bounce rate or the information from Google Analytics to make its ranking:
@dnespo we don't use analytics/bounce rate in search ranking
— Gary 鯨理/경리 Illyes (so official, trust me) (@methode) May 13, 2015
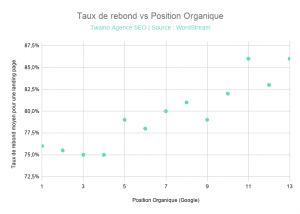
After his study, Larry found that there is a correlation between the bounce rate and the organic position:
For the request that was the subject of his study, having a bounce rate of 76% gives a better chance of appearing in the first positions. By exceeding 78%, your website may have a lower ranking.
Larry is not claiming that the bounce rate is a direct ranking factor.
Rather, he says,
“But I think there’s definitely a link between bounce rate and ranking. Looking at this graph, I have the impression that it is not an accident, but that it is in fact an algorithm.
Also in 2016, Brian Dean conducted a study on 1 million Google results and found almost the same correlation:
It is important to remember that a low bounce rate does not necessarily mean a better ranking since it depends on the niche of the website.
But in general, a high bounce rate will be a bad sign for sites such as e-commerce. On the other hand, it will be less so for a website that just gives information like Wikipedia.
That said, the conclusions we’ve drawn so far still hold true, don’t they?
Factor 3: Time spent on a website can affect its ranking
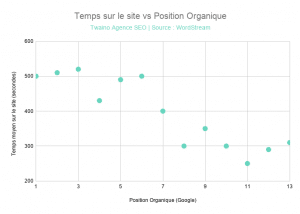
According to Larry King’s study, time spent on a website has a clear correlation with position in the SERPs:
According to this graph, if visitors spend about 500 seconds on your website, you are likely to make it to the top 6 positions.
This does not mean that you have to try to reach the 500 seconds at all costs. The idea is to show you that a constant improvement of this parameter will have a positive effect on your rankings.
And why not exceed 500 seconds or 8 minutes!?
Factor 4: The dwell time and its impact on the position in the SERPs
The dwell time is the time that a Google searcher spends on a page of the search results before returning to the SERPs.
Although there is not a precise way to determine the dwell time, it is possible to evaluate it with the factors that I have just mentioned.
Larry believes that:
“Google uses dwell time – which we can’t measure, but is proportional to user engagement like bounce rate, time on site, and conversion rates – to validate rates. of clicks.
These metrics help Google determine whether users ultimately got what they were looking for.‘s
take an example to illustrate this setting.
Imagine that you are using the query: “how to create backlinks”.
Google shows you some results:
The first result seems well suited and you click on it:
But when you get there, the site is:
Bad designer;
Difficult to use ;
Presents unhelpful content.
For this reason, you leave the site after 10 seconds:
Your dwell time is therefore 10 seconds and this super brief visit indicates to Google that you were not satisfied with the result it offered you.
Now let’s say you next click on result 2:
This time:
The content is very helpful;
You have great ease in using the website;
The design is well elaborated.
In short, you have excellent content:
So this time you spent more than 10 minutes on the website to read the content.
Then you are back in the SERPs:
This long dwell time lets Google know that you have gained some added value from this website.
Now consider that many users, like you, spend a long time on the second web page.
The search engine will tend to boost that page’s rank for that query, right?
“In addition, the user can select a first link in a list of search results, go to a first web page associated with the first link, then quickly return to the list of search results and select a second link. The present invention can detect this behavior and determine that the first web page is not relevant to what the user wants. The first web page may be downgraded, or alternatively, a second web page associated with the second link, which the user has been viewing for longer periods or time, may be upgraded..
Another point, in particular the use of dwell time, has also just been clarifiedIf you are wondering if there is a standard dwell time, know that the dwell time depends on several factors, namely:
Your niche;
The type of content;
The search query people use to find your page;
Seasonal trends;
Etc…
Instead of worrying about an arbitrary number, I recommend focusing on improving your website-wide dwell time.
3.3.2. The Semrush Study
In 2017, Semrush conducted a study on ranking factors through 600,000+ keywords. The results can be summarized with this infographic:
For the keywords used for this query, user signals are very important for the search engine.
Here it is:
Time spent on the website;
The number of pages per session;
Bounce rate.
In addition to information from Google and various studies, there is no longer any uncertainty: The search engine takes into account the user’s experience in its rankings.
Even if it is indirectly and to different degrees, Google takes UX into account. If UX is so important, where will SEO fit in this picture?
3.3.3. SEO and UX: Two powerful tools to optimize a website!
Google has changed significantly over the years.
Indeed, the search engine giant constantly updates its algorithms to ensure that users get the best possible results.
Like me, many experts believe that every update Google has made has been designed to provide more user-friendly and user-focused results.
We had time to see the changes that the search engine made to the SERPs and which showed the importance it places on UX.
These include:
Featured snippets;
From Google Suggest;
Knowledge Graph;
From Google Maps;
From RankBrain;
Etc…
All of Google’s actions are aimed at providing its users with the best possible experience.
Normal that it takes into account the signals of the user experience to make its classifications, is not it?
Moreover, the basic principles that the search engine indicates to webmasters in its instructions are as follows:
«
Concevez vos pages en pensant d’abord aux internautes et non aux moteurs de recherche.
Ne trompez pas les internautes.
Évitez les “astuces” destinées à améliorer le classement sur les moteurs de recherche. Pour savoir si votre site Web respecte nos consignes, posez-vous simplement la question suivante : “Cela me dérangerait-il d’expliquer au propriétaire d’un site Web concurrent ou à un employé de Google quelles sont les solutions que j’ai adoptées ?”. Vous pouvez également vous poser les questions suivantes : “Ces solutions sont-elles d’une aide quelconque pour les internautes ?”, “Aurions-nous fait appel à ces techniques si les moteurs de recherche n’existaient pas ?”
Pensez aux éléments qui rendent votre site Web unique et attrayant, et qui lui confèrent de la valeur. Faites en sorte que votre site Web se distingue des sites concurrents dans votre secteur d’activité. »
We agree, the user is at the center of the decisions made by the search engine.
Does this mean that UX is more important than SEO, which aims to use techniques to improve the positioning of a website in the SERPs? Of course not!
UX and SEO share the same objective and are complementary! There you go, I said it☺
Indeed, UX can fit perfectly into SEO because they both share common goals.
Source : Paldesk
If you’ve followed SEO over the past few years, you’ll know it’s moved away from just ranking for search terms.
Now, SEO seeks to provide searchers with information that meets their needs.
This is where UX and SEO start to interact since both want to help users accomplish their tasks by providing them with relevant information.
While SEO is going to lead a person to the content they need, UX is going to answer their question once it lands on the web page.
That being the case, what about RankBrain? Does it use UX to influence rankings?
Chapter 4: How RankBrain evaluates the success of the results it offers?
To answer this question, let’s first see how RankBrain relates to other ranking signals.
This approach is much more interesting, don’t you think?
4.1. RankBrain Impacts Google Ranking
4.1.1. RankBrain is a ranking factor
Let’s start by establishing the basics in order to better understand this very important point.
You remember ? Greg Corrado stated in the Bloomberg:
“RankBrain is one of ‘hundreds’ of signals that go into an algorithm that determines which results appear on a Google search page and where they are ranked. Within months, RankBrain has become the third most important signal contributing to the result of a search query.you
would think that it directly influences the ranking, wouldn’t you think? But is this really the case?
4.1.2. RankBrain influences SERP results!
With the word “Rank” in the name, that’s certainly what it implies☺.
But let’s not just limit ourselves to this banal remark which obviously has no weight in terms of argument.
Thanks to the previous section, you may already have an idea on the matter. But consider a more direct answer from Gary Illyes:
Lemme try one last time: Rankbrain lets us understand queries better. No affect on crawling nor indexing or replace anything in ranking
— Gary 鯨理/경리 Illyes (so official, trust me) (@methode) March 18, 2016
@randfish I meant any ranking component. It does change ranking, e.g we're better at getting relevant results for negative queries
— Gary 鯨理/경리 Illyes (so official, trust me) (@methode) March 18, 2016
The French translation
“Rand Fishkin: I’m not sure what ‘replace something in the ranking’ means? Are you saying that Rankbrain has “no direct impact” on rankings?Gary Illyes: I meant any ranking component changes the ranking, for example, we are better at getting relevant results for negative queries.“
One can also consider this response from Gary to Moty Malkov:
@MotyMalkov that's the whole point of a ranking change. Now you can actually rank for queries like [can I finish super mario WITHOUT help]
— Gary 鯨理/경리 Illyes (so official, trust me) (@methode) March 18, 2016
Translation:
MotyMalkov: Aren’t they classified differently when you understand them better?
Gary Illyes: That’s the whole point of a ranking change. Now you can really rank for queries like [can i finish super mario WITHOUT help]”
Conclusion: RankBrain helps Google understand queries better and rank their results better.
Is it only the 15% of unknown requests that are affected? It would seem not since Danny Sullivan published an article on the subject:
Danny states:
“Google is typically vague about exactly how it improves search (something to do with the long tail?) but Dean says that RankBrain is ” involved in every query”, and affects the actual ranking “probably not in every query but in a lot of queries”.RankBrain
‘s field of action. AI impacts almost all search engine rankings. But how does he proceed?
4.1.3. How RankBrain can influence the ranking?
RankBrain has no impact on other components of Google’s algorithm. The next section further details this claim.
At this level, it must be understood that if visitors return to the SERPs just after clicking and visiting your web page, RankBrain believes that your page has nothing to do with what its users want.
It does not rate your web page considering your content to be bad, but it will try to offer other content soon to satisfy the user’s intent for the query.
Thus, your web page could have a lower position for this query.
But that doesn’t mean it won’t be featured for another query.
It is important to note that RankBrain does not rate the quality of your page. The other search engine algorithms take care of evaluating the other ranking factors.
Google’s AI simply tries to understand what the user means when performing a given query.
Therefore, if RankBrain decides that your page is not what someone is looking for, it does not mean that your content is not good.
Rather, RankBrain considers your content not to be the best.
This conclusion was confirmed by Gary Illyes during one of his conversations with Rand Fishkin:
@randfish I meant any ranking component. It does change ranking, e.g we're better at getting relevant results for negative queries
— Gary 鯨理/경리 Illyes (so official, trust me) (@methode) March 18, 2016
Let’s take a simple example to illustrate.
A Google user makes the request “construction of a garden shed” and Rankbrain positions your web page at the first position.
If the visitor arrives on your website and does not find the information he is looking for, he is likely to leave it quickly.
Even if enough users do the same, RankBrain won’t consider you to have bad content.
It will feel that it made a mistake by giving a result that does not meet the intent of its users.
For a next time with the same request, it will then adjust the ranking of the pages. Google’s AI will keep doing this until it finds the best answer for that specific query.
It becomes legitimate to seek to know how RankBrain evaluates the success or failure of its proposals.
4.2. RankBrain uses historical data to assess the relevance of its results
“In practice, some systems can continue learning once in production, provided they have a way to obtain a feedback on the quality of the results produced.“.
How RankBrain gets feedback on the quality of the results they offer?
Eric Enge, the SEO expert I have already had the opportunity to quote, had an interview with Gary Illyes at the Pubcon Las Vegas in 2016:
On his blog, Eric published a this article which summarizes the discussion he had with the googler
Regarding RankBrain, Eric shows that Gary did not not only limited to the function of RankBrain that Google has been repeating ever since the launch:
“Focus on improving the handling of long-tailand unknown queries.
Since we have already covered this aspect, it would not be not wise to come back to it.
other hand, certain points are very crucial to remember to understand the functioning of RankBrain.
Like the other very important concepts, I will try to report his remarks faithfully (with a few details since he spoke in English☺):
“2. Gary also indicated that RankBrain makes its decisions based on the evaluation of historical performance data for queries deemed by RankBrain to be very similar (in the language of machine learning, this is determined by seeing how a given query performs to historical queries in vector space high-dimensional). Google may use the historical performance of these other queries to adjust the ranking results of the new long-tail query as it arrives.”
“3. I asked Gary to weigh the pros and cons of claims that RankBrain drives other parts of their algorithm, and he reiterated that it doesn’t change those algorithms. Thus, the algorithms related to links – Penguin, Panda, and other algos – are completely unchanged by RankBrain.“.
What does this actually mean?
Let Eric still shed some light on his second meeting with Gary Illyes at SMX Advanced in 2017(i.e. 1 year later):
“RankBrain leverages historical query performance essentially, or nearly identical, to see what worked and what didn’t, then uses this information to adjust and improve the results provided for the current query.In more detail, RankBrain compares the user’s query with other historical queries of a similar nature.This is where machine learning comes in, as they use it to identify historical queries that are most similar to those that Google has already answered. machine learning, this is done in a “high-dimensional vector space.
This is then used to see how these historical queries performed. By looking at multiple queries, Google e can determine which types of results worked well and which did not.
This information is then used torefine the results obtained from the usual Google algorithms for the new query and, in some cases, they can even modify the algorithms invoked to process the query.Illyes
asserting and Eric Enge’s interpretation of it a year later are similar.
be toWhat does the term “historical query performance” really mean in the context of RankBrain?
This question has led many SEO experts to believe that RankBrain uses UX signals to make decisions. In fact, we have already since Google considers its users to be the best judges of the relevance of its results.
This is a controversial point in the SEO community. While there are some experts who argue that RankBrain seems to take into account UX, others categorically refute this hypothesis.
This is a hypothesis since Google does not seem to want to clearly clarify this question.
Anyway, we know that Google takes into account signals from UX to do their rankings. RankBrain is part of the system and might interact with such kind of signals.
Indeed, Eric Enge, who discussed RankBrain for a long time with Gary Illyes, schematizes its operation this way:
At one point, RankBrain may well interact with data concerning user behavior. Especially since it also allows Google to rank part of the results taking into account past performance.
The only tangible information we have on this is from Google Brain, theGoogle team that designed RankBrain:
Seroundtable reveals a Google employee speaking at the Think Auto Google event in Toronto in 2017:
“So , when search was invented, like when Google was invented many years ago, they wrote heuristics that figured out what the relationship was between a search and the best page for that search. And this heuristic worked quite well and continues to work quite well. But Google is now integrating machine learning into this process. So you have to train models to know when someone clicks on a page and stays on that page, when they go back, or when they go back and try tounderstand exactly this relationship. So research is getting better and better with advances in machine learning.»
It is not explicitly indicated that RankBrain integrates its own system which evaluates the dwell time and its implications. It may well be another machine learning that is/will be provided with this ability.
In any case, user experience is at the heart of Google’s development and RankBrain probably interacts with such signals to offer better results.
To finish this part, let’s see to what extent RankBrain could take UX into account.
4.3. How could RankBrain take UX into account?
In this section, we will consider the scenario where RankBrain considers user satisfaction to validate the results it offers. I admit that this hypothesis seems the most probable for me.
RankBrain might do it this way:
RankBrain shows you a set of search results that it thinks you’ll like.
If a significant number of users like a particular page in the results, the search engine will give that page a ranking boost.
If the result is not satisfactory, Google will replace this page with another one.
And the next time someone searches for that keyword or a similar term, the search engine will see how that page is performing with users.
We have just gone through the operation of RankBrain. Let’s see some examples that describe RankBrain in action.
Chapter 5: Some Examples of How RankBrain Could Improve Search Results
In order to understand precisely how RankBrain improves Google’s search results, we will use some examples.
Some come directly from Google, others come from interpretations made by certain SEO experts.
Rating: Rating thatoverthinkgroup did most of the work since their RankBrain article brought the next six examples together.
I will try to convey these examples faithfully, since some examples are almost impossible to reproduce these days.
5.1. RankBrain guesses what you’re looking for, even if you don’t know what words to use
This is the first example given of how Rankbrain works and is taken from the Bloomberg article.
To explain this ability of RankBrain, Danny Sullivan who now works at Google, uses the same query as that used by Greg:
“What’s the title of the consumer at the highest level of a food chain”.
In English:
“What is the title of the consumer at the highest level of the food chain?.
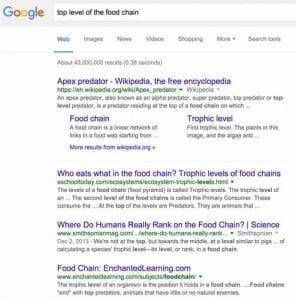
This is the kind of query we typically type into Google when we’ve forgotten a particular term
Here is the result for this query in 2016:
Source : SearchEngineLand
It should be noted that Google is clearly struggling to provide a precise and relevant result for this query.
The search engine nevertheless understood the search intent and returned a few results that might lead the user to find their answer.
That said, the researcher will have to dig through the pages on his own to get the information he needs.
The result is no longer the same when you search for:
“Top level of the food chain” or in French “plus haut level de la chain food”:
This query is much more precise and Google gives the answers that the user wishes to have.
The condition for having such a result was that you had to enter the right terms to get precise answers.
According to Danny, RankBrain allows having the same result for two different queries if it finds that the search intent remains the same.
In 2018, Danny made the same request:
“What’s the title of the consumer at the highest level of a food chain”
In French:
“What is the title of the consumer at the highest level of a food chain?
result is as follows:
At this level, we see that there is a featured snippet that directly gives the answer to the question asked.
In addition, there are related questions that can provide answers for related questions.
It is possible to consider RankBrain has understood over time that this query needed a very specific answer.
This is apex predator or apex predator in English.
On the other hand, the result is different for “top level of the food chain”:
RankBrain has enough data to estimate that the second query should have a different result from the first.
Indeed, the second query aims to obtain information on a particular level of the food chain. Unlike the longer search which aims to obtain information about a specific consumer.
RankBrain tries to understand concepts and their nuances that can be very complex to understand. It is for this reason that it can provide accurate results even when you don’t use the exact words and phrases in searches.
5.2. RankBrain can figure out when stop words matter
This example was given by Gary Illyes to Danny Sullivan at the SMX Advanced conference.
The request considered at this level is:
“Can I beat Mario Bros without using a walkthrough”
In French:
?present
To understand this example, it is important to note that Google has a habit of ignoring certain words in queries.
Ranks gives a list of stop words that are often ignored by Google when processing queries:
Back to our example!
RankBrain is able to determine when a stop word is important in a query.
At this level, the word “without” (“without” in French) must be considered in order not to alter the meaning of the sentence:
“Can I beat Mario Bros without using a walkthrough?”
without,” you end up with another query and results that don’t match the search intent.
On this subject, Gary Illyes says:
“Without RankBrain, we give interesting results which do not meet my needs. But with RankBrain we can give results that satisfy my question..
If after doing this Google search you are presented with pages that only cover how to beat Mario Bros with a walkthrough, you will probably be frustrated
However, RankBrain is smart enough to know that the word “without” is important.
So it will only display pages that answer the question “do I need a walkthrough to beat Mario Bros?” “.
Pages that don’t specifically answer this question RankBrain will likely rank them lower.
That doesn’t mean they’re low quality, they just don’t meet the search intent for that query.
We can conclude that it is important to go through all the aspects concerning the topics you are interested in.
5.3. RankBrain knows when your location changes and offers appropriate results
The third example is also from Danny Sullivan ☺ who reports what Google said.
example is for the query:
Indeed, cups and soup spoons are larger in Australia than in the United States. Google must take your location into account when displaying results.
How many tablespoons in a cup?”
Google lets it be known:
“RankBrain favored different results in Australia versus the U.S. for this query because the metrics in each country are different, despite similar names.”
However, after testing this example, Danny Sullivan says he didn’t notice a real difference:
Indeed, he used the same query on Google.com and Google Autralia.
Danny feels he didn’t find a big difference and even without RankBrain the results were subject to change. This is because of Google’s tendency to favor pages from more well-known local sites for local users.
Bad example given by Google? Personally, it would seem so.
Google is probably trying to theoretically explain how RankBrain works. Or its use of personalization data.
Conclusion: RankBrain uses position to interpret what you really mean by the words you put in the search bar.
5.4. RankBrain may consolidate similar searches to use more reliable data
Once again, Danny Sullivan interprets how RankBrain works using an example in relation to the query:
“Best flower shop in Los Angeles”
&
“Los Angeles Flowers”
Danny says,
“Imagine RankBrain going on a search for ‘best flower shop in Los Angeles’.
He might understand that this is a search similar to one that may be more popular, such as “Best LA flower shops”.
If so, then he could simply translate the first behind-the-scenes search into the second.
He would do this because for a more popular search, Google has a lot more user data that helps him feel more confident about the quality of the results.
RankBrain is able to determine if two different queries have the same search intent.
Thus, it will tend to offer the results of the most popular query for similar queries.
If the results of a query have already been displayed several million or billion times, it is quite normal that the results of this query are displayed for a query that has the same search intent and is less popular.
But as Danny says,
“Ultimately, RankBrain changed the ranking of those results. But it did so simply because it triggered a different search, not because it used a special ranking factor to influence the exact order in which the listing appeared.
RankBrain may therefore consolidate similar searches to provide the best results.
5.5. RankBrain may give you satisfactory results for subtle search intent
This example was used by Rand Fishkin of Moz in his article on: “Optimizing for RankBrain …Should We Do It?”.
This time the request is:
“Best Netflix shows”
In French:
“Best Netflix shows”.
As we have seen, RankBrain tends to show similar results for queries with the same search intent.
It indicates that RanKbrain will tend to do the same for these five queries:
Best Netflix shows: Best Netflix shows;
Best shows on Netflix: Best shows on Netflix;
What are good Netflix shows: What are the good Netflix shows?
Good Netflix shows: Good Netflix shows;
What to watch on Netflix: What to watch on Netflix.
Rand goes further and indicates that for this type of research, the “freshness” factor of the content is very important.
Indeed, RankBrain will look at all this research and understand that: You are looking for what is on Netflix right now.
Which is something that is not stated in your query and is subtle.
Rand Fishkin says,
“If you’re not fresh, you’re not showing searchers what they want, so Google won’t show you. In fact, the number one hit for all of these movies was released, I believe, six or seven days ago, when this Whiteboard Friday was being filmed. Not particularly surprising, is it? Freshness is very important for this query.
As a reminder, Google was already using freshness as a ranking factor with Caffeine :
With RankBrain, Google is now better since it is able to determine when this factor will be taken into account or not for a given query.
Updating your content is important as I had occasion to describe in my article on the one-upmanship technique.
But you shouldn’t rush headlong into updating all your content since Google will not give the same importance to the “freshness” factor for all types of content.
While the freshness factor will be crucial for news on the President’s releases, it will be less so for a guide on building backlinks.
5.6. RankBrain is really good at understanding complicated searches
The fifth example was given by AL GOMEZ in his article on: “Creating content for Google’s RankBrain”.
The main query used is:
“Shape of conversion optimization in the future of digital marketing and beyond”
Gomez successively made the following requests in Google:
Conversion optimization: Conversion optimization;
Best conversion optimization tool: Best conversion optimization tool;
What is the top conversion optimization tool for marketers? : What is the best conversion optimization tool for marketers?
Shape of conversion optimization in the future of digital marketing and beyond: Shape of conversion optimization in the future of digital marketing and beyond .
The results from Google are as follows:
Despite the complexity of the queries, RankBrain or Google understood the search intent and provided the relevant results.
These are just a few examples of how RankBrain could really change the results that Google offers.
Now, how do you make sure that RankBrain likes and ranks your page in top positions?
Chapter 6: How to optimize your content for RanKbrain?
Google’s machine learning machine has come to validate what top SEOs have been saying for a long time: Create the best possible content for your audience.
After its launch in 2015, it wasn’t until 2016 that Gary Illyes gave an answer about optimizing content for RankBrain:
“Optimizing for RankBrain is actually super easy, and that’s something we say probably for fifteen years now, is – and the recommendation is – to write in natural language.
Try to write content that sounds human. If you try to write like a machine, then RankBrain will just get confused and probably push you away.
But if you have a content site, try reading some of your articles or what you’ve written, and ask people if that feels natural.
If it sounds conversational, if it sounds like a natural language that we would use in your everyday life, then of course you are optimized for RankBrain.
If this is not the case, then you are “not optimized“
I can deduce that the strategy to adopt for an optimization for RankBrain is to create content offering an optimal user experience.
It is important to remember that RankBrain does not is not a ranking factor like the others. We have no control over it since it is a faculty of Google to better understand the requests of its users.
Let’s take a simple example:
Backlinks are part of the three ranking factors the most important of Google. By obtaining backlinks thanks to your netlinking campaigns, you have chances to improve your ranking in the SERPs.
You can take concrete actions to optimize for this factor. You know that if you have a considerable number of backlinks, you can rank
This which is not the case with RankBrain which tries to understand queries in order to offer better results. Is it impossible to optimize content for RankBrain? No, you can optimize your content so that Google’s AI better positions your web pages.
6.1. How to perform keyword research in the AI universe?
With RankBrain, Google is able to better understand the search intent behind its users’ queries.
Does this mean that you have to skip the step of researching the keywords?
No, it is not a question of ignoring this step which is also crucial in determining the search intent of your audience. To the extent that you will have the opportunity to design content that meets their needs and that seems relevant enough for RankBrain to position them in its top results.
At this level, it will be a question of choosing the right keywords and using them in the right way.
6.1.1. Avoid optimizing different pages with similar keywords Until
a few years ago, it was relevant to optimize different pages with significantly different keywords.
For example, suppose you are optimizing two different pages with these slightly different keywords:
“how to build a garden shed”
“how to build a garden building”
The Google before allows you to rank for these two different keywords- keys:
Source : Backlinko
With RankBrain, Google gets to know that the search intent is the same and will yield similar results.
For my example, I had almost the same results.
“how to build a garden shed”
“how to build a garden building”
Usually long-tail keywords are used in this way. That is, they sometimes have very little difference in terms of meaning and search intent.
Does this mean that they should no longer be used?
No, I’m not trying to say that a keyword category is completely obsolete. The idea is simply to make sure your pages are optimized for keywords that are clearly distinct and have different search intent.
Otherwise, you risk keyword cannibalization with multiple pages ranking for the same or similar keywords. However, Google opts for diversity in its search results and does not display in its results more than two web pages per site.
So, what to do concretely?
6.1.2. Optimize your pages with medium-sized keywords
How RankBrain works could negatively impact long-tail keywords in different ways.
There is no doubt that long-tail keywords are the most numerous and are much more specific than other types of keywords:
Indeed, RankBrain is able to determine if two queries are similar even if they are composed of different words. For this reason, it might display the same result for “How to build a garden shed yourself” and “build a garden shed”.
And this is indeed the case for this example:
“How to build a garden shed yourself”
“build a garden shed”:
Another reason is the fact that RankBrain offers the most popular keyword results for words similar keys.
Take my example, “build a garden shed” is more likely to have a higher search volume than “How to build a garden shed yourself”.
The first query is popular and RankBrain has already provided results that have satisfied its users more than once. It will be confidant to come up with almost the same results when dealing with similar queries.
It is for these two reasons that it is wise to opt for medium-sized keywords.
When you optimize your page around a medium-tail keyword, Google’s machine learning machine will automatically rank you for that term and similar keywords:
You’ve certainly found that your content is not ranking uniquely for the main keywords you optimized them for. They rank on related or similar keywords.
For this, you can opt for LSI keywords and co-occurrence.
6.1.3. Use LSI Keywords and Co-
occurrence is how often related terms appear on your page.
By using terms that are part of the same semantic field as your main keyword, RankBrain will have more precision on the theme that your article mainly deals with.
When he thinks someone is looking for information related to the topic, he knows that your content will meet his intentions.
LSI or Latent Semantic Indexing keywords also play this role by helping RankBrain see how relevant your content is to a given query.
LSI keywords are words and phrases related to the main topic of your content. They also give RankBrain the context it needs to fully understand your page.
Suppose you are writing a guide on “building a garden shed”. You could use LSI keywords such as:
Single slope garden sheds;
Wooden garden sheds;
Construction cost;
Permit to build garden shed;
Building tools and materials;
Etc…
When RankBrain sees that your content contains these terms, it is confident that your page is really about garden shed construction”.
6.1.4. What to avoid when using keywords
But you have to be very careful not to fall into Keyword Stuffing or accumulation of keywords.
Remember, we try to make optimizations to give users the best possible experience. Your texts must be clear and “sound like anatural language that we would use in your everyday life”
Gary Illyes shows:
“It’s a new signal.
But the reason I asked about optimizing for RankBrain is because you don’t.
This is to ensure that the user gets the result he deserves for his query.
If you write in natural language, you are ready.
If you stuff your content with keywords, it will definitely not be good for you.covered
the topic when it comes to keyword research. Let’s see how you can optimize your pages for the best user experience.
6.2. Optimize your page for UX signals
RankBrain looks at user experience signals to gauge the relevance of the results it delivers.
For this, you should also use UX signals to determine whether you did a good job or not.
The main factors you should pay attention to are:
The CTR or click-through rate in the SERPs;
The bounce rate on your page;
The dwell time.
6.2.1. Optimize your click-through rate in the SERPs
As we have seen, organic CTR is a key Google ranking signal. Rankbrain probably uses it to better rank the results it offers.
Even the best content in the world won’t perform well in the SERPs if it doesn’t drive clicks. There is no doubt that having clicks is crucial since they allow you to have visitors who will then perform certain actions on your website.
Assuming RankBrain includes your page in the right SERPs, you need to make it more appealing than the competition.
To make users click on your result or page, there are three main factors to consider:
The title of your page;
The description of the page;
Branding.
Factor 1: Give captivating titles to your content
The title is the main element that Internet users will consider to determine if you have the information they are looking for. It is no longer enough to put the main keyword of your content in the title for it to perform.
An attractive title should clearly show that your content is able to satisfy the searcher’s need.
If you want to dig deeper, I invite you to consult my complete guide on creating impactful and catchy titles which even gives you access to ready-to-use formulas.
Rating also that titles that arouse strong emotions among Internet users perform very well in terms of clicks and commitments.
Indeed, a study by CoScheduke showed that the more a title arouses emotion, the more it is likely to have engagement. Particularly in terms of shares:
BuzzSumo and OkDork also carried out a study in the same direction which shows that content arousing certain types of emotions experiences the most engagement.
Keep in mind that the most important thing is to be sufficiently clear about what you bring to the Internet user. Your title should immediately convey the following message: “you will definitely find what you are looking for here”.
Once you find the right title for your content, only the description tag remains.
Factor 2: Optimize your description tag to get more clicks
In addition to the title, this is an opportunity to show how your content is unique and can satisfy the user’s search intent.
Touch key concepts in your content so users know you have what they’re looking for.
“There is no limit to the length of meta descriptions, but search result snippets are truncated as needed, usually to fit the width of the device. .Still
, it’s a good idea to keep your description short at around 155 characters to prevent Google from truncating your text. You also need to be clear, specific and don’t forget to include your keyword.
As you can already imagine, it’s important to make your meta tag “sound human” and natural.
You will find much more information on the meta description tag in my article on SEO.
Factor 3: Branding and Awareness of Your Brand
WordStream conducted a study that shows that:
“Searchers are more likely to click on you if they’ve heard of you before“
Indeed, when people are in SERPs, they are much more likely to follow a link to a brand they already know and trust.
This is a very big advantage that you can optimize by raising awareness of your brand.
Branding is part of my marketing strategies as I explain in my article about how I went from 0 to 1000 visitors.
As you can see in the following image, the query that gets me the most traffic is the name of my SEO agency: Twaino.
This shows that a large number of my visitors type my agency name directly into the SERPs to get to my website. I will soon dedicate a full article on branding.
For now, keep in mind to provide the best possible experience for your visitors so that they have some trust in your brand.
To do this:
Create high-quality content;
Send good emails;
Be present on social networks;
Etc…
With these three factors, you will be able to significantly improve your click through rate. But once you’ve brought visitors to your website, you need to be able to keep them there and allow them to find the information they’re looking for.
6.2.2. How to reduce your bounce rate?
When a visitor lands on your page and immediately leaves, that’s a good indicator that they’ve landed in the wrong place.
If a significant number of visitors leave your webpage this way, RankBrain may consider that your page does not meet the search intent for that query.
Thus, it will decrease the ranking of the page and offer other content instead.
Even with a high click-through rate, it is important to consider these two factors to reduce the bounce rate on your pages.
Factor 1: Increase your website’s loading speed
Google has explicitly stated,
“Speeding up websites is important – not just for site owners, but for all Internet users. Faster sites create happy users and we’ve seen in our internal studies that when a site responds slowly, visitors spend less time there.“.
Loading speed is a very important ranking factor as it has a strong correlation with position in the SERPs.
Additionally, 53% of users will leave a page that takes more than 3 seconds to load:
Your Bounce rate will inevitably increase if visitors leave your web page this way.
Keep in mind that top ranked websites average 1.9s to load. It would be a good idea to try to approach this figure and why not, to do
Both of these factors can significantly lower your bounce rate, but you can go further.for
6.2.3 How to increase the dwell time of your pages
The more your content keeps visitors on your page, the better!
This lets RankBrain know that it has offered a good resulta given query.
At this level, it is important to make a good impression quickly.
When someone comes to your page from Google, assume that you will only have a few seconds to impress them. The first thing they will see must confirm to them that they are v come to the right place.
Just because they landed on your webpage doesn’t mean they decided you were the best choice.
Here are some tactics that can help you increase the time people spend on your website.
Tactic 1: Write authoritative content
The first tip is to write authoritative content that deals in depth with the topics you cover. Having long content allows you to significantly increase your dwell time.
Although short content makes it possible to respond directly to readers’ questions, they sometimes leave them with a thirst for information.
Many statistics show the effectiveness of authority content and I invite you to read my article on the overbidding technique.
Suppose you want to know “how to build a garden shed”.
You received 500 words of content that briefly describes the steps to follow and the materials to use. This still leaves several unresolved questions:
So you go back to the SERPs (pogo-sticking) and you finally come across a 10,000-word piece of content that explains the whole process in detail.
You not only have all the information you want, you also discover aspects of the subject that you had not thought of. You therefore take the time to consult everything and come back later to points that you had not retained.
Long content performs very well and here is the result over 1 month when I sort the pages having experienced a high duration:
This would not have been possible if the content was not long and bringing a certain added value to the readers.
However, it is not about publishing a block of text.
Admittedly, reading 10,000 word content is particularly difficult.
To do this, use them:
Subtitles;
The visuals;
Small paragraphs;
Space to provide a good reading experience;
Etc…
Source : SEOPressor
Try to offer an optimal experience for your readers.
Tactic 2: Put your content above the fold
You only have a few seconds to show visitors that they are in the right place to find the information they are looking for.
One of the best ways to do this is to place your content above the folds so that the visitor doesn’t have to scroll down the page before reading the first few sentences.
Instead of having something like this:
Source : Backlinko
Opt for a layout like this instead:
Also, try to have a short introduction since they are much more effective.
Because when someone searches for something in Google, they already know something about it. So you don’t need a long introduction.
The intro is where 90% of your readers will decide whether to continue reading or leave the page. So craft it in such a way that it inspires people to keep reading.
With these two tactics, you should be able to keep your visitors on your web pages longer.
There you go, you have just optimized your content so that RankBrain understands it and considers it to be the best results for the themes you deal with.
Conclusion: Optimization for RankBrain is very simple
Google is continually improving its system and the consequences are often noticeable in terms of the ranking of the results it offers. This is one of the reasons why it is unlikely to maintain a given position in the SERPs.
SEO specialists must therefore know the trends related to the various factors that can affect the positioning of their website.
This is the case with RankBrain which continues to enjoy a certain mystery as to how it works and how it relates to other ranking factors.
In this article we have had the opportunity of these different elements which can be summarized as follows:
RankBrain is used to process unknown or imprecise requests thanks to its capacity for learning and prediction;
Google’s AI is among the three most important ranking signals as it helps serve better results to a query;
RankBrain does not affect other traditional ranking and scoring processes;
RankBrain may use user experience signals to judge the relevance of its results;
Google’s AI also does not affect crawling or indexing.
As for optimization, it’s important to keep in mind that Google’s AI does not rate pages. The other signals take care of this and are already factors for which you should optimize your website.
As for RankBrain, it is enough to publish high quality content for your audience. Without forgetting to target medium-tail keywords with high volume.
Search engines will always continue to improve in order to provide answers like the way we hold our conversations. It is important to stay in this trend in order to offer users the most optimal experience possible.
What do you think of RankBrain’s use of user experience signals?
Feel free to share your point of view!
Goodbye !
Alexandre MAROTEL
Founder of the SEO agency Twaino, Alexandre Marotel is passionate about SEO and generating traffic on the internet. He is the author of numerous publications and has a YouTube channel aimed at helping entrepreneurs create their websites and improve their Google rankings.
Boost your revenue through SEO with the Twaino agency
Nous utilisons des cookies pour optimiser notre site web et notre service.
Fonctionnel
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Préférences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistiques
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.