
Let’s face it! The slightest change that search engines, especially Google, make to their system does not go unnoticed by the SEO.
In 2010, we knew that Google made more than 500 changes to its algorithm:

This figure is far exceeded since in 2018 alone, the firm changed its algorithm 3,234 times, or more than 6 times.
Of course, most of these updates are minor and their impact on rankings is insignificant. So we don’t have to worry😊
But some changes, considered major, are easily noticeable because of their effect on rankings and website traffic:

Source : Google
This is the case of the last update Google’s most important day: BERT.

In view of the effects of major updates, it is quite legitimate to seek to know the implications of Google BERT.
Therefore and like my article on RankBrain, I will try to show:
- What is Google BERT;
- How BERT works and the problem it is trying to solve;
- The impact of BERT on SEO;
- The different strategies to adopt to optimize your website.
Let’s go!
Chapter 1. What is Google BERT?
1.1. BERT: Google’s Machine Learning Model
A few years after RankBrain, Google is rolling out another update that it calls very important: BERT.
This change was first deployed on the territory of the United States in October 2019. For other countries and languages, in particular France, it will be necessary to wait until December 9, 2019:
As this tweet attempts to point out, BERT will help the search engine algorithm better understand searches, both at the query and content level.
However, it is important to note that BERT is not just a Google algorithm as one would imagine.
In reality, BERT is also a research project and an open source academic paper that was released in October 2018:

Google also says in its blog:
“We have opened up a new NLP pre-training technique called Bidirectional Encoder Representations from Transformers, or BERT. With this release, anyone in the world can train their own state-of-the-art question answering system (or a variety of other models) in about 30 minutes on a single TPU Cloud, or in a few hours using a single GPU..”
You can already see that BERT stands for “Bidirectional Encoder Representation from Transformers”.
Additionally, BERT is a machine learning model used to consider text on both sides of a word.
Whoops ! looks like it gets a bit complicated with technical notions/terms.
Don’t worry, I’ll try to explain these different concepts as simply as possible.
Note that BERT is a model of machine learning and therefore part of AI or artificial intelligence.
And just like RankBrain, BERT is constantly evolving through the models and data submitted to it.

1.2. BERT: The New Era of Natural Language Processing
Currently, BERT has become important because it has dramatically accelerated natural language understanding for computer programs.
Indeed, the fact that Google has made BERT open source has enabled the entire field of natural language processing research to improve the overall understanding of natural language.
This has also prompted many large AI firms to also build BERT versions.
We thus have:
- RoBERTa from Facebook:

- Microsoft extending BERT with MT-DNN (Multi-Task Deep Neural Network):
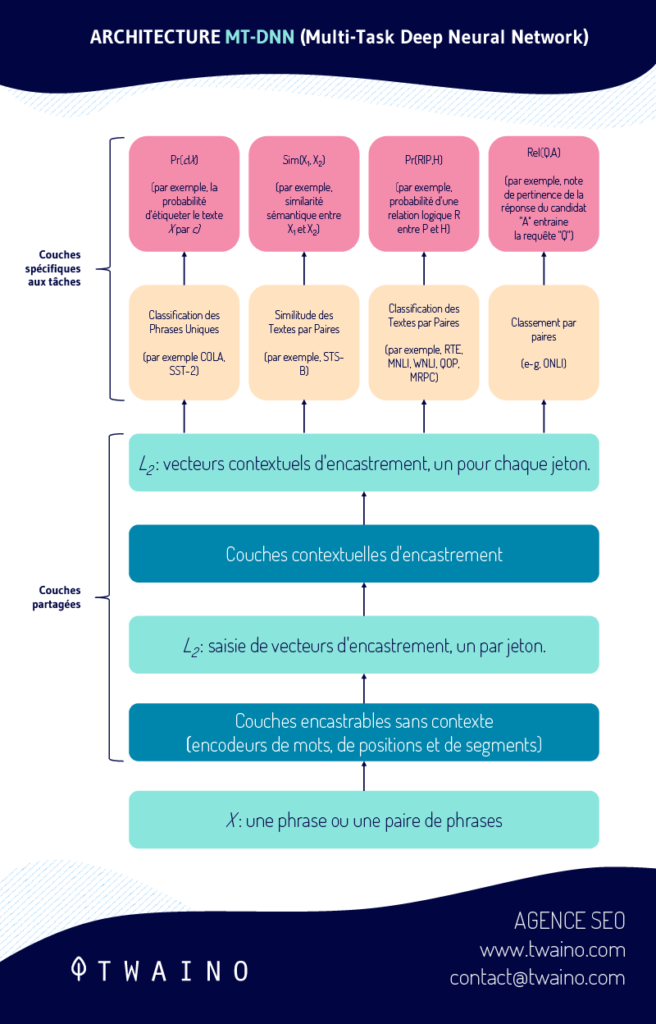
- SuperGLUE Benchmark to replace the GLUE Benchmark:

For example, there is a form of BERT called “Vanilla BERT ”.
The latter provides a pre-trained starting layer for natural language machine learning models. This provides a solid basis for their structure to be continuously improved. Especially since Vanilla BERT was preformed on the Wikipedia database .
This is one of the reasons why BERT is considered the method that will be used to optimize NLP for years to come.
For Thang Luong, senior research scientist at Google Brain, BERT would be the new era of NLP and probably the best one created so far:
From the above, it should be understood that BERT is not exclusively used by Google. If you’ve done a lot of research on the subject, you’ve probably seen that most mentions of BERT online are NOT about updating Google BERT.
You will be entitled to many articles on BERT (which sometimes give headaches because they are too technical / scientific) written by other researchers. And that don’t use what we can think of as Google’s algorithm update.
Now we know what BERT is and we are going to talk about how it works.
Chapter 2: How does Google BERT work?
To understand how Google works, you must first understand the concept of NPL.
2.1. What is Google’s NLP and how does it work?
Communication between humans and computers in natural-sounding language is made possible through NLP.
The acronym NLP stands for “Natural Language Processing” or in French “Natural Language Processing”.
It is a technology based on Artificial Intelligence which consists of the automatic learning of natural language.
This technology is also used in:
- Word processors such as Microsoft Word Grammarly which use NLP to check the grammatical accuracy of text;
- Language translation applications such as Google translate;
- Interactive Voice Response (IVR) applications used in call centers to respond to requests from certain users;
- Personal assistants such as OK Google, Hay siri, Cortana, Alexa…
NLP is the framework that allows Google BERT to work and which consists of five main services to perform natural language processing tasks.
2.1.1. Syntactic analysis
During this analysis, the search engine breaks the query down into individual words and then extracts the linguistic information.
For example, take the following query: “Plant a tree in a garden”
In this query, Google can break it down like this:
- Planter tag : Verb in the infinitive
- A tag : Determiner
- Tree tag : Common
- In tag : Preposition
- A tag Determinant
- Garden tag : Common Name
As is the case with the Stanford/Parser which is a natural language analyzer:

2.1.2. Sentiment analysis
Analysis Google’s sentiment analysis system assigns an emotional score to the query.
The following table shows some examples explaining how the concept of sentiment analysis performed by Google works.
Therefore, note that the values do not come from Google were taken at random:

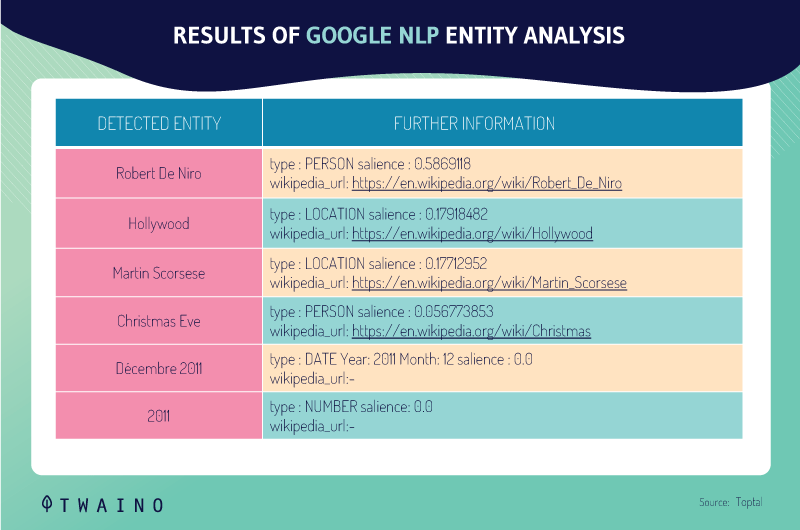
2.1.3. Entity analysis
Here, Google takes into account the entities that are present in the requests to present information about them, most often with the Knowledge Graph.
If you search for example “size of the Eiffel Tower”, the search engine will detect “Eiffel” as an entity.
This way it will send information about this query:

Google can classify things this way for this example from Toptal:
“Robert DeNiro spoke to Martin Scorsese in Hollywood on Christmas Eve in December 2011.”
2.1. 4. Entity Sentiment Analysis
Similar to sentiment analysis, Google tries to identify the overall sentiment in documents containing entities.
In this way, the search engine gives a score to each of the entities according to the way they are used in the documents.
Let’s take another example from Toptal:
« The author is a horrible writer. The reader is very intelligent on the other hand. »

2.1.5. Classification of text
Google’s algorithm knows precisely to what subject the web pages belong.
When a user makes a query, Google matches analyzes the phrase and knows exactly in which category of web pages searched.
Here is another example from the same source:
They analyzed with the Google NLP API this sentence from an announcement on Nikon:
“The D3500’s large 24.2 MP DX-format sensor captures richly detailed photos and Full HD movies—even when you shoot in low light. Combined with the rendering power of your NIKKOR lens, you can start creating artistic portraits with smooth background blur. With ease. “
Translated, we have:
« Le grand capteur DX de 24,2 MP du D3500 capture des photos très détaillées et des vidéos Full HD, même en cas de faible luminosité. Combiné à la puissance de rendu de votre objectif NIKKOR, vous pouvez commencer à créer des portraits artistiques avec un flou d’arrière-plan lisse. En toute simplicité. »
The result of the classification is as follows:
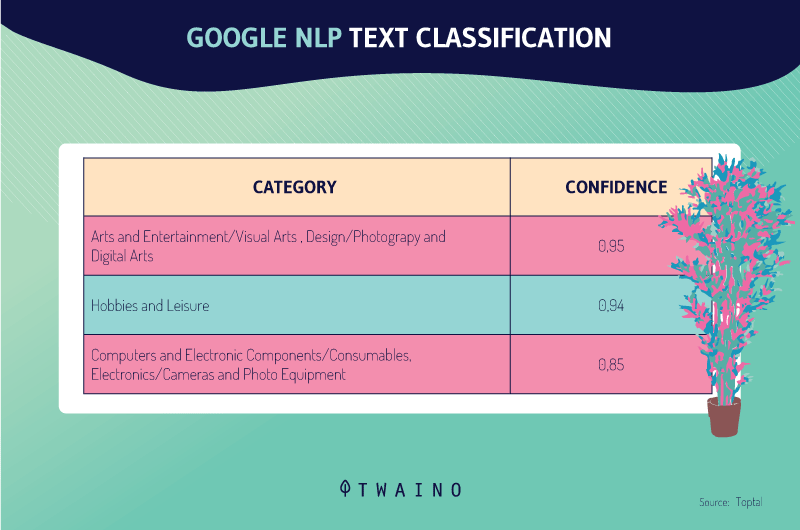
It can be seen that the test is classified in the category:
- and entertainment/Visual art and design/Photographic and digital arts with 0.95 as the confidence index;
- Hobbies and hobbies with a trust index of 0.94
- Computers and electronics / Consumer electronics / Cameras and camcorders with a trust index of 0.85.
These are the 5 pillars of Google NLP whose main challenge is the lack of data.
In the words of Google :
“One of the biggest challenges in natural language processing (NLP) is the lack of training data. Because NLP is a diverse field with many distinct tasks, most task-specific datasets contain only a few thousand or a few hundred thousand human-tagged training examples.
Google went a step further and designed the Google AutoML Natural Language that allows users to create custom machine learning models.
Google’s BERT model is an extension of Google AutoML Natural Language. This is why the NLP community can also use it.
2.2. What problems is BERT trying to solve?
As humans, we can easily understand certain things that machines or computer programs cannot understand.
BERT has come to correct this problem in its own way and here are the main points it deals with:
2.2.1. The number and ambiguity of words
More and more content is released on the web and we are literally overwhelmed:

Their number is not a problem in itself for machines that are designed to process an astronomical amount of data.
Indeed, words are problematic because many of them are:
- Ambiguous and polysemic: A word can have several meanings;
- Synonyms: Different words mean the same thing.

Bert is designed to help resolve ambiguous sentences and expressions that are made up of polysemous words.
You will agree with me that there are a multitude of words which have several meanings.
When I write the word “magnet”, you don’t know if it is the material used to attract iron or if it is the conjugation of the verb “to love”.
This ambiguity is noticeable for writing or written texts, but it becomes much more difficult when it comes to speaking.
Indeed, even the tone can make a word have another meaning.
When I say an insult in a friendly tone to a loved one, it absolutely does not have the same meaning as when I utter insults in an angry tone.
The first will tend to make you laugh, but the second risks giving me a hard time.😊
We humans have this natural ability to easily understand the words that are used.
What computers cannot yet do perfectly. Which brings out another much bigger problem:
2.2.2. The context of words
A word has precise meaning only if it is used in a particular context.
Indeed, the meaning of a word literally changes as a sentence develops.
I’ll take a very simple example: “We all did the work, that’s a fact..
As humans, we have the ability to quickly know that the two words “done” are different
program once more Stanford Parser :

An analysis of my sentence gives me this result:

The software was able to differentiate between “fact” as a verb in the past participle and “fact” as a common noun.
Without NLP, it would have been difficult for computer programs to make a clear enough difference between these two terms.
Indeed, it is the context and particularly the other words of the sentence which make it possible to understand the exact meaning of the words.
Therefore, the meaning of the word “fact” changes according to the meaning of the words around it.
Obviously, the longer the sentence, the harder it is to follow the full context of all the words in the sentence.
Thus, with the increase in content generated on the web, words become more problematic and more difficult for search engines to understand. Not to mention conversational research, which is much more complex than writing.
The big problem that BERT solves here is to add context to the words used in order to understand them.
The essential role that BERT plays is therefore to try to UNDERSTAND the words used.
We will come back to this in the next sections of this guide. For now, let’s focus on another aspect of NLP which is the difference between NLU and NLR.
2.3. The difference between Natural Language Understanding (NLU) and Natural Language Recognition (NLR)
Natural Language Understanding is different from Natural Language Recognition.
Search engines know how to recognize the words that their users use. But that doesn’t mean they can understand the words from their context.

Indeed, to become aware of natural language, you have to use common sense. It is a rather easy thing for humans, but difficult for machines.
For example, we are used as humans to examine several factors in order to understand the context of words and therefore the information that is conveyed.
These include, for example:
- Previous sentences;
- The person we are talking to;
- Of the framework in which we are;
- Etc.
However, a machine cannot do this so easily, even if it can recognize natural language words.
For this, we can state that the NLU, BERT, allows Google to have a better understanding of the words that it is already used to recognizing.
The same is true for structured data and Knowledge Graph data which have many gaps that the NLU fills.

One might rightly ask: How can search engines fill the gaps between named entities?
2.4. Natural Language Disambiguation
Anything that is mapped to the Knowledge Graph is not used by search engines. This is why natural language disambiguation is used to fill the gaps between named entities.
It is based on the notion of co-occurrence which provides a context and can modify the meaning of a word.
For example, you would expect to see a phrase such as “referring site” in an article that discusses backlinks. But seeing a term like “cryptocurrency” would be out of context.
This is why linguistic models that are trained on very large collections of texts must be marked up by datasets. This, by using distribution similarity in order to learn the weight and measure of words and their proximity.
Here, BERT is used to perform the tasks of training these trained models to make the connection between concepts and words:

Thanks to these models, the machines manage to build vector space models for the incorporation of words:

2.5. How Google BERT Provides Context to Words
A single word only has semantic meaning when placed in a given context.
BERT is then used to ensure “text cohesion”, i.e. to maintain a certain consistency in the text.
When talking about cohesion, there is only one factor that gives meaning to a text: The grammatical link.
An important part of the semantic context is part-of-speech tagging / part-of-speech tagging (POS):
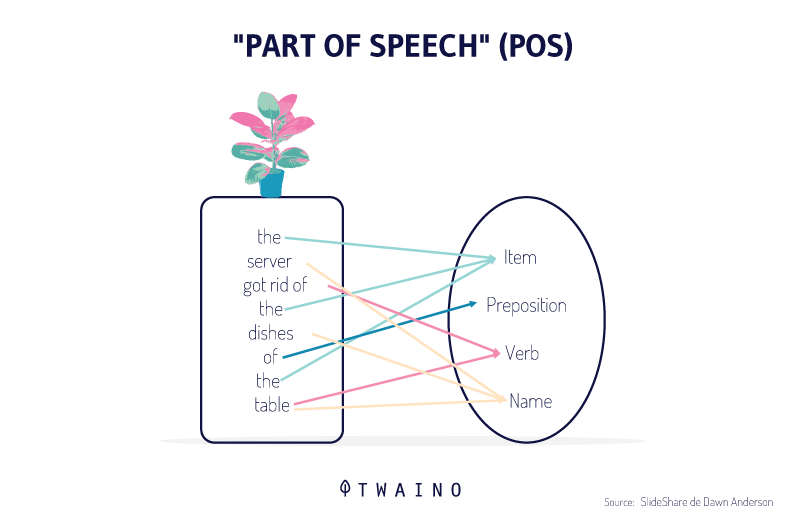
We had to mention it in the section on NLP! You remember that, don’t you?
Now, let’s give an answer to the following question:
2.6. How does Google BERT work?
Old language models such as Word2Vec that we saw in the RankBrain do not integrate words with their context:

This is exactly what BERT is trying to allow search engines to do.
We are going to see how it works and to do this, we are going to dissect the acronym itself of BERT: Bidirectional modeling Encoder Representations Transformers
2.6.1. The B of BERT: Bidirectional
Linguistic models used to be unidirectional when trying to understand the context of words.
In other words, they could only move the context window in one direction to understand the context of the word:

Let’s take this example to understand better: “I have already consumed the content that is published”
The models linguistics could only read the sentence one way to try to understand the context. Which means that they will not be able to use the words surrounding “consumed” in both directions, to know that this word means at this level to consult / to take cognizance.
This is why we say that most language modelers are unidirectional and can only iterate over words in one direction. Which can make a big difference in understanding the context of a sentence.
BERT, on the other hand, uses bidirectional language modeling and can see both sides of a target word to place it in context:

BERT is the first to have this technology which allows it to see the whole sentence on each side of a word in order to get the full context:

Google points this out in this research paper titled “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”:
“BERT is the first representation model based on fine-tuning that achieves peak performance on a broad suite of sentence-level and token-level tasks, outperforming many task-specific architectures…. It is conceptually simple and empirically powerful. It achieved new industry-leading results on eleven natural language processing tasks, including raising the GLUE score to 80.5% (7.7 absolute improvement), MultiNLI accuracy to 86.7% (4 absolute improvement .6%), the answer to the SQuAD v1.1 question in the F1 test at 93.2 (absolute improvement of 1.5 points) and the F1 test SQuAD v2.0 at 83.1.”
B”, we will continue with the:
2.6.2. BERT’s RE: Encoder Representations
Encoder Representation is essentially the act of feeding sentences into the encoder and outputting decoders, patterns, and representations, depending on the context of each word.

I think there is nothing to add, let’s go to the last letter of the acronym:
2.6.3. BERT’s T: Transformers
BERT uses “transformers” and “Masked Language Modeling”.
Indeed, another important problem encountered in natural language was to understand to whom / what context a particular word refers to.
For example, it is sometimes difficult to keep track of who we are talking about when using pronouns in a conversation. Especially when it’s a very long conversation!

This problem is not lacking in computer programs. And it’s a bit the same for search engines, they have a hard time following when you use pronouns:
- He/they;
- She / They;
- We ;
- That ;
- Etc.
It is within this framework that the processors focus, for example, on the pronouns and the meaning of all the words that go together. This allows them to link the people we are talking to or what we are talking about to a given context.
Transformers are all the layers that form the basis of the BERT model. They allow BERT to not only look at all the words in a sentence, but also to focus on each individual word and examine the context from all the words around it.
BERT uses transformers and “Masked Language Modeling”, which means that certain words in a sentence are “masked”, requiring BERT to guess certain words:

Words are randomly masked and BERT is held predict the original vocabulary of words based solely on its context.
This is also part of the model development process.
Chapter 3: Case Studies: How BERT Really Improves SERPs
To understand how Google BERT works, we’ll use the examples that Google provided in their BERT article.
Example 1: The meaning of the word “someone”
The query that is considered is the following:

Literally translated, we have: “Can you get medicine for someone pharmacy”
Although this is not very precise, we can understand that the user is looking to determine if a patient’s loved one can pick up a prescription on their behalf.
Before BERT was integrated into its algorithm, Google gave this kind of response:

Translated, we have the following response:
“Your healthcare provider can give you a prescription in… Write a prescription on paper that you bring in a local pharmacy… Some people and insurance companies choose to use…”
This answer is clearly unsatisfactory since it ignores this “someone” who is not the patient.
In other words, Google could not process the meaning of the word “someone” in the context of the query.
After BERT, Google seems to be able to pick up on the subtleties in the queries it processes.
Here is the answer that Google now provides to such a query:
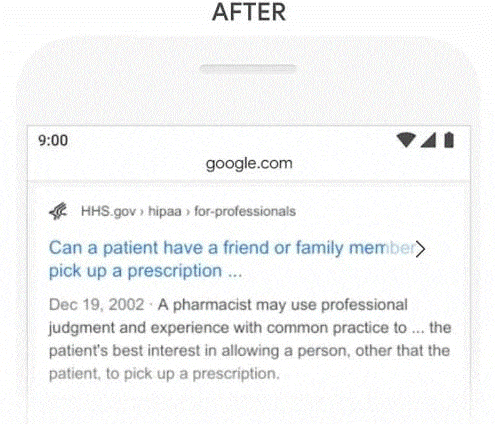
Translated into English, we have:
“A pharmacist may use his professional judgment and experience of current practices to … in the best interest of the patient by allowing a person, other than the patient, to pick up a prescription..
We can agree that this response is explicit and unambiguously responds to the researcher’s request
In other words, Google has now understood the semantic meaning of the word “someone”, without which the phrase takes on a whole new meaning.
So what was BERT’s role in this task? We agree that BERT helped Google understand the query.
Indeed, Google has now been able to identify the most important words of the request thanks to their context and grant during processing a certain note of importance.
This way of doing things has allowed Google to provide much more accurate search results.
Example 2: Considered the word “booth”
The following query:

Translated, we have:
“Do beauticians work a lot”
Before BERT, Google gives this answer:

Translated, we have:
“the type of company in which an esthetician can have an impact on her income, … schools offer aesthetic programs, although there are also independent aesthetic schools..
The answer really has nothing to do with the user’s query
Indeed, Google did not know how to correctly interpret the term “stand” by linking it to the expression “stand-alone” which means “independent / autonomous”.
It is for this reason that Google has proposed a result that evokes the independent work of beauticians.
With Bert, Google gets a little smarter and gets to understand the context of the query:

Translated into French:
“Speak clearly so listeners can understand. Hold the arm and hand in one position or hold the right hand while moving…”
Here, Google lists the physical exertion beauticians are required to perform as part of their job.
The answer to the question “do beauticians work a lot” finds a better answer.
This is exactly what Google says:
“Previously, our systems took a keyword matching approach, matching the term ‘stand-alone’ in the result with the word ‘stand’ in the query. But that’s not the proper use of the word “stand” in context. Our BERT models, on the other hand, understand that the word “stand” relates to the concept of the physical demands of a job and displays a more useful response.
Example 3: The context of the word “adults”
third example, we have this query:

Translated into English, we have:
“Book of practice in mathematics for adults”
Here, we can assume that the user intends to buy math books for adults.
The answer that Google offered before BERT is as follows:

The finding is that Google returns results suggesting books for children, especially 6-8 year olds.
Google provided this answer because the page contains the phrase “young adult”.
But in our context just matching the words doesn’t work and obviously “young adult” is irrelevant to the question.
After BERT, Google is able to correctly discern the difference between the two expressions “Young Adults” and “adult”.
out-of-context responses

Example 4: Considering the word “without”
Considering another example where Google ignores a very important preposition:

Translated into English:
“Stationnement sur une colline without sidewalk”
Here is the answer that Google offers before BERT:

We can see that Google has given far too much importance to the word “sidewalk” while ignoring the word “without”.
Google probably didn’t understand how essential that word was to answering that query correctly.
So it was returning results for parking on a hill with a sidewalk.
Bert seems to solve this problem, because the search engine better understands the query and the context.

As you can see, Google gave a pretty decent answer for the query in question.
At this stage, you have a better understanding of Google BERT. Let’s see how you can optimize your website to enjoy good SEO in the age of BERT.
Chapter 4: How to optimize your website for Google BERT?
Search engine optimization is the process of increasing the visibility of a website in search engines.
Therefore, any update search engines make to their algorithm influences the ranking process.
4.1. What is the impact of BERT on SEO?
The most obvious point that follows from everything we’ve covered so far is that BERT helps Google better understand human language.
BERT can pick up nuances in human natural language, which will make a big difference to how Google interprets queries.
The firm estimates that this change will affect 10% of all queries, as Google is trying to communicate:
“In fact, when it comes to ranking results, BERT will help Search better understand one in ten searches in the United Statesin English, and we will expand to other languages and locations over time.
Google Like RankBrain, intends to handle mostly long, conversational queries with BERT:
“Especially for more conversational queries, or searches where prepositions like ‘for’ and ‘to’ matter a lotfor meaning, Search will be able to understand the context of the words in your query. You can conduct your search in a way that feels natural to you..
The search engine also intends to apprehend queries in which prepositions or any other ambiguous word are important to understand the meaning of the sentence
What to keep: BERT is a powerful update that Google uses to better process queries to present the best possible results to its users.
Obviously, another interpretation / better understanding of the queries causes Google to give other answers instead of the ones it used to give.
Many people have complained about the impact on their rankings and others have seen their rankings improve, as expected.
With BERT, Google is able to determine whether the pages it has ranked for certain queries are relevant or not.
In this case, he could downgrade them and put in their place other pages that he thinks are much more appropriate.
And the long-awaited question:
4.2. How to optimize your website for Google BERT?
We may describe BERT, but the most important question is what you can do to optimize your website for BERT.
For this, we are going to refer to Danny Sullivan who I talked about a lot in my article on RankBrain.
He’s Google’s Audience Liaison, which means he helps people better understand search and helps Google better understand audience feedback.
His answer to the question is quite simple:
What Danny is really pointing out is that there is nothing you should do from today that you shouldn’t have done before BERT.
Like RankBrain, Google BERT allows Google to better understand queries.
For example, it does not rate content like an algorithm that takes into account the loading speed of websites to rank them.
Therefore, optimizing for BERT comes down to: Writing quality content for users.
There’s no doubt that Google has been focusing on content for a few years now, and I think its next updates will go in the same direction.
But let’s try to understand how to optimize the SEO of a site in the context of BERT.
I think there are two main things to consider when you want to optimize your content for this major Google update.
Optimization for BERT: Identify the search intent of your users
BERT tries to better understand the user’s queries or to be more precise their search intent.
If people carry out research, it is above all because he has a need to satisfy.

In the examples given by Google and that we saw in the previous chapter, it was necessary to understand the intention of the users to give a relevant answer.
Let’s take the first example: “Can you get medicine for someone from the pharmacy“.
It should be understood that the intention of the research is to: Find out if it is possible for a loved one to take medication from the pharmacy for a patient.
By reading the request in one go, it is not easy to detect this search intention. This is why, it is very important to go through the step of determining search intent once you have keywords.
Knowing search intent involves asking questions such as:
- Why does your audience search using particular keywords?
- What are they seeking to achieve through their research?
- Are they trying to find the answer to a question?
- Do they want to reach a specific website?
- Do they want to make purchases when they use these keywords?
- Etc.
With the increasing use of mobile and voice search, where people need quick, contextual answers to their questions, Google is trying to become more and more capable of determining people’s search intent.
So keep in mind that the entire Google SERP now tries to best match the search intent and not the exact keyword being searched for.
Over the past few years, you will find that there are situations where the exact term you are looking for will not even be included in the Google search results page. I say this from experience and I am convinced that I am not the only one.
This happens because Google has become increasingly good at determining people’s search intent.
I have covered this subject at length, which you will find through articles such as:
- What is SEO ;
- How to set up a semantic cocoon;
- The EAT.
Content that meets people’s search intent will be rewarded with Google BERT.
Optimizing for BERT: Consider voice search and featured snippets
Google has stated that BERT is about long and conversational queries. And guess in which type of search we usually find these two elements: Voice Search.
If BERT mainly handles long queries and natural language, this means that it allows google to process a good part of voice searches which are generally long:

In addition to length, queries are generally conversational.
In the same way that you can’t tell your friend “Eiffel” to get information about this monument, you won’t do it with your voice assistant.
You will be more conversational by asking a complete question: “What is the Eiffel Tower”.
With long + conversational queries, you will use all the words to phrase your question. This can lead you to use the prepositions that Google talks about and which are sometimes important.
Conclusion: Voice search is the type of queries that Google wants to process with Google BERT.
This fact may be due to the fact that users are using more and more voice assistants to carry out searches:

Google obviously does not want to miss this revolution which is much more demanding than the classic search with the writing:

You must try to optimize your content for voice search and one of the best ways to start is to think about the featured snippet:

You have to understand that searchers want to find very quickly the content that answers their question exactly.
If you search for something like “how much is 300 euros in dollars”, you will get a direct answer in the featured snippet:

With the BERT update, Google has made an effort to show even more relevant featured snippets.
Check out my article on voice search to learn some useful tips.
Let’s finish our guide with some best practices to adopt in content creation in the era of BERT.
Chapter 5: Some good practices to adopt in content marketing in the era of BERT?
Google is giving more and more credit to high-quality content, and you need to focus on writing user-relevant content.
If you have low-quality content on your site, it may be time to clean up or refresh it since it may not perform well with Google BERT.
Which brings us to the first practice:
Practice 1: Audit the content you have published
Before you start creating new content, the best approach is to do an audit of the content you have published so far. .
This step mainly allows you to know the content that brings the most traffic to your website and that allows you to occupy the best positions in the SERPs.
Once these contents have been determined, you will carry out an evaluation to determine if they:
- Are natural and do not contain keywords with a mechanical connotation;
- Respond to the intentions of Internet users;
- Are optimized for conversational search;
- Are qualitative enough to bring real added value to Internet users;
- Are optimized for EAT;
- Etc.
With the resources I’ve listed so far, you’ll likely have several indicators that you’ll be looking at.
This action allows you to optimize your content so that it does not lose positioning in the SERPs.
Especially if the competition from content that offers a better user experience than yours, you will perform less.
Thus, a content audit allows you to strengthen and/or improve the position of your content which already performs well in the SERPs.

It is also an opportunity to discover poor quality content and optimize it or delete it if it is ultimately useless.
That said, if you’ve just launched your website, keep in mind that it usually takes time for your content to start performing.
To take this one step further, you can consider a full SEO audit or take advantage of my free SEO audit.
Practice 2: Create authoritative content
By definition, content marketing involves creating high-value content to attract and retain a clearly defined audience.
As Google understands natural language better, it’s clear that content writers have a great chance of serving their readers with content written in a more “human” way. And which fully meet the research intentions of the researchers.

BERT seems to make Google understand the searcher’s queries even better, so you have no excuse.
Creating authority content is one of the most effective strategies for baiting Google. The proof: My entire content creation strategy is based exclusively on evergreen content, which has allowed me to currently reach 6,000 visitors per month.
Check out my article on the one-upmanship technique to learn how to create such content.
The most important advice is to carry out a SERP analysis to know the current level of quality of the content present in the results of Google.
I detailed this process in my post on 5 Steps to Analyze the SERP for Better Content.
You will pay attention to:
- Search volumes for keywords;
- The type of content ranked on the keywords;
- The difficulty of ranking on these queries;
- The backlinks that allowed the pages to appear in the first results of Google;
- Etc.
You can make it easier for yourself by using tools like Moz, Ahrefs, Ubersuggest…
And if you’re wondering why you need a tool, I’ll tell you that a tool can give you a lot of clues about what that really interests your users. This allows you to write content that will truly meet the needs of your audience.
Practice 3: Optimize your EAT (Expertise Authoritativeness and Trustworthiness)
Google is putting more and more emphasis on the concept of EAT, especially for YMYL sites.
These are the websites that have an impact on the lives of Internet users:

But even if your website does not fall into these categories, it is equally important to give great importance to the EAT.
You might be wondering what is the connection with Google BERT?
Note that you can create quality content, but if you lack authority or reliability on the web, you may underperform compared to your competitors.
Therefore, thinking about optimizing your website for EAT is one of the best SEO strategies:

There you go, there’s almost nothing to add that you don’t already know.
Conclusion: Google BERT – Be simply natural in the creation of your high value-added content

Since its creation, Google has never ceased to maintain its vision which is to offer the best results to its users.
In this logic, the leader of search engines has just added another major update to its list: BERT.
As usual, this change has not gone unnoticed by the SEO community, which must understand how search engines work to optimize their SEO strategy.
In this article, I tried to show how Google BERT works by avoiding technical terms as much as possible. I haven’t completely escaped it unfortunately☹
But we understood that BERT is an “open-source” machine learning model which presents itself as a major advance in the field of Natural Language Processing.
Google uses it to better understand the different words in queries, in particular through their context. A better understanding that impacts 10% of queries processed by the search engine.The only advice the firm gives is to focus on: Creating high-quality content.

Indeed, all the latest Google updates tend to favor content that brings great added value to Internet users.
Therefore, now more than ever is the time to exclusively focus your efforts on creating high-quality content.
I had the opportunity to give you some tips that you can take advantage of to take full advantage of the Google BERT era and probably the next Google updates.
You wish, as usual, a lot of traffic, I tell you:
See you soon!