Domain Name History

Quick Overview : WaybackMachine
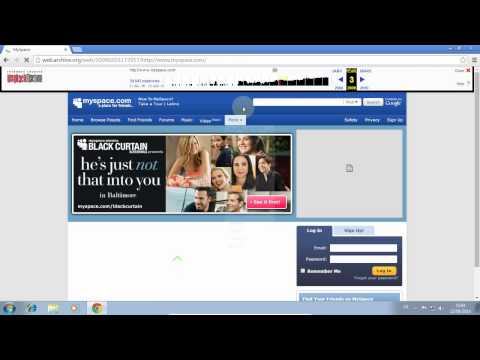
Wayback Machine lets you see what websites looked like in the past. It has over 729 billion archived pages since 1996.
Videos


Gallery









Description
Description Wayback Machine – Internet Archive
Sometimes it can be useful to find out what a website looked like in the past or review the content of an old web page that is currently unavailable.
Wayback Machine is an online service offered by the Internet Archive that allows you to go back through Internet archives and access past snapshots of websites.
Over 729 billion web pages have already been crawled and archived by the Internet Archive’s Wayback Machine. To access it, you just have to enter the domain name of the site you are looking for or a corresponding keyword.
What is Wayback Machine?
Wayback Machine is one of the services offered by the Internet Archive. It was launched in 2001 and is the organization’s most used service among Internet users.
It’s a tool that allows you to “go back in time” to find out what a website looked like at a time in the past.
Currently, the Wayback Machine remains one of the richest digital archives with billions of web pages archived since 1996.
The organization’s (Internet Archive) goal is to help preserve digital artifacts and provide a library Publicly accessible internet for scholars, historians and researchers.
For this, the tool offers an add pages feature to allow website owners to self-archive their pages on the platform.
However, pages can take between 6 and 24 months to appear in the Wayback Machine after being collected.
In addition, the Internet Archive does not archive:
- Pages that require a password to access
- Pages designated by their owners as “excluded from robots”
- Pages that are only accessible when the user must fill out a form
- And pages hosted on secure servers.
In addition to pages that can be added by website owners themselves, the Internet Archive also works with institutions to provide all the information available in its database.
Wayback Machine: How to use the tool to find historical snapshots of a site?
Wayback Machine is a tool accessible to everyone and very easy to use.
- To use it, simply go to the Archive.org
- If you know the full URL of the site you are looking for, you can type it into the site’s search bar.
Otherwise, Wayback Machine also offers a keyword search feature.
- Simply enter a keyword related to the homepage of the site you are looking for and click on launch your query.
- The platform should show you a list of results that match your search. Click on a result to access the pictures of the corresponding website.
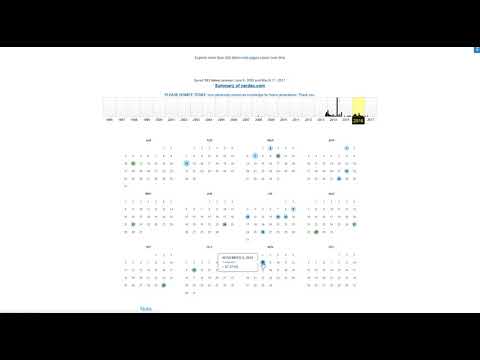
By default, Wayback Machine displays the snapshot of the current year, but also offers a navigation system that allows you to go back in time and quickly see how the site has looked for years past.
But for better viewing, you have a link to display the list of all the archived captures of the site with a calendar to more easily access the rendering of the site on a specific past date.
By hovering the mouse over a given date, Wayback Machine automatically offers a list of times of day that you can click on to access the site snapshot at exactly that time.
Wayback Machine: Advanced features
Wayback Machine is a priori suitable for researchers with a number of features that may go unnoticed by occasional users:
Referencing an archived page : With Wayback Machine, it is possible to easily reference snapshots of archived web pages in your own content by inserting their URLs.
Save Your Pages to the Wayback Machine Archive: With its “Save Page Now” feature, Wayback Machine also allows site owners to save some of their pages to theInternet Archive.
Here is the procedure for saving your web pages on Wayback Machine:
- Go to the Wayback Machine
- At the bottom of the page, you have a field called “Save Page Now”. Enter the URL address of the page you wish to save, then click on the “Save Page” button.
Your page has just been added to the Wayback Machine archive.
Use a search operator to quickly find a page on the Wayback Machine: With the Wayback Machine, you can search for specific content without having to visit the site each time.
The tool offers a search operator in the format ” https://web.archive.org/*/www.yoursite.com/* ” that you can enter directly into your browser and access archived snapshots of a website.
For example, to see Twaino’s pages saved to the Wayback Machine, simply Google https://web.archive.org/*/www.twaino.com/*
Wayback Machine: APIs and Versions Mobile Apps and Browser Extensions
The Wayback Machine is not just a web tool. You can also get it in mobile version on your iOS or Android.
Wayback Machine also exists as an extension that you can install and use on Chrome, Firefox, Opera and Safari.
For developers, the tool also offers different APIs to access its database.
Simply put, the Wayback Machine is the perfect platform for revisiting the past appearances of your favorite websites across almost any medium.
It is also a tool that can be useful for students and professionals looking for information on the history of a website.
Wayback Machine: How to delete your web pages from the Wayback Machine archive?
1. Preventative Measure: Block Access to Wayback Machine
It is possible to remove your information from Wayback Machine so that the pages of your website that are archived are no longer accessible on the Internet Archive.
However, it is a complicated process that can take a long time. That’s why if you have sensitive pages that you don’t want to be archived by the Wayback Machine, you can take steps now to prevent the tool from accessing your website.
To prevent the Wayback Machine from accessing your domain, it will be necessary to modify the contents robots.txt of your website’s
The role of the robots.txt file is to control how outside programs can access your website.
https://www.twaino.com/seo/robots-txt/
Being also a third-party program, the Wayback Machine must also respect the indications that you provide in your robots.txt file.
- Access the robots.txt file of your website then using a text editor, add completely at the end of the file, the following lines:
User-agent: ia_archiver
Disallow: /
- Then make sure you have saved your changes (Ctrl + S) before closing the file.
Once done, your site should now be protected against archive.org and its Wayback Machine.
However, remember that this is a preventive measure. All of your pages that the Wayback Machine would have archived will still be available on the platform.
If you are particularly keen to remove these pages from Archive.org, here are your options:
2. Submit a removal request to the DMCA
One of the options for removing your pages from the archives of the Wayback Machine is to send a DMCA removal request.
Regardless of your niche and the content of your website, the Internet Archive is required to comply with federal regulations related to the protection of intellectual property.
The Digital Millennium Copyright Act (DMCA) is one of the measures proposed by the US government to protect your intellectual property.
However, if you are not in the field, it would be better to have a lawyer accompany you to correctly draft and submit the request for submission to the DCMA.
3. Send an email to [email protected]
To delete an archived page on Archive.org, the best method recommended by the platform is to send an email to [email protected].
However, when the email is sent, the Internet Archive does not respond right away. This may be due to the number of pending deletion requests the Archive.org team receives. But after a few days you should get an answer.
About WaybackMachine
The Internet Archive is not in itself a company, but a non-profit organization that intervenes in the field of information and the Internet. It is actually a digital library of websites.
Like traditional libraries, The Internet Archive offers unlimited access to information for researchers, scholars, historians and the general public. Their mission is to provide free access to diverse global knowledge.
The Internet Archive started archiving in 1996 by archiving the Internet itself, which didn’t really have an information repository. But currently, with over 25 years of web history, you can access all of the information through The Internet Archive’s Wayback Machine.
The latter also works with more than 950 libraries and other partners through its Archive-It program. It is a program that allows you to detect the important web pages of different websites.
