SEO Agency >> SEO Tools >>
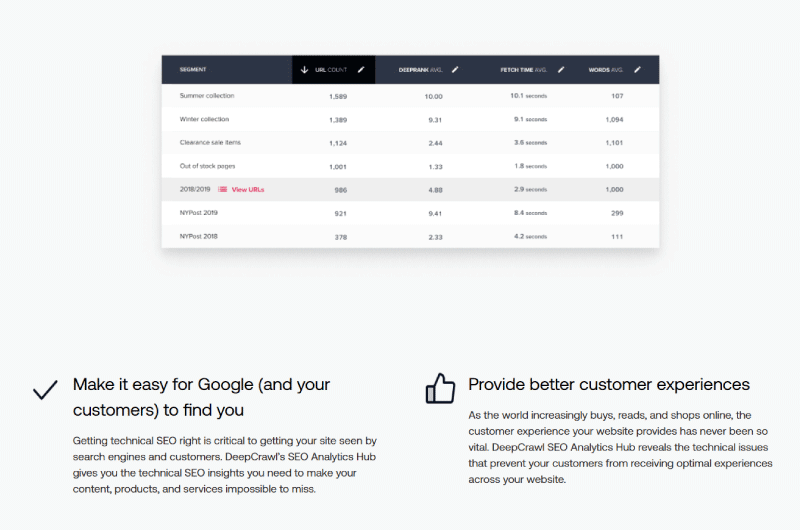
Crawler | Deep Crawl
SEO Agency >> SEO Tools >>



 Alexandre MAROTEL
Alexandre MAROTELFounder of the SEO agency Twaino, Alexandre Marotel is passionate about SEO and generating traffic on the internet. He is the author of numerous publications, and has a Youtube channel which aims to help entrepreneurs create their websites and be better referenced in Google.