Descripción Deep Crawl
Si necesita examinar el estado técnico de su sitio web, Deepcrawl es un explorador que le permite ver cómo los motores de búsqueda rastrean su sitio.
La herramienta proporciona una amplia gama de información sobre cada página de su sitio web para darle una idea clara de su probabilidad de indexación.
Descubramos en esta descripción cómo funciona Deepcraw.
La herramienta funciona sustrayendo datos de diferentes fuentes como mapas de sitio XML, consola de búsqueda o análisis de Google.
Así, te da la posibilidad de vincular hasta 5 fuentes para que el análisis de tus páginas sea relevantemente efectivo.
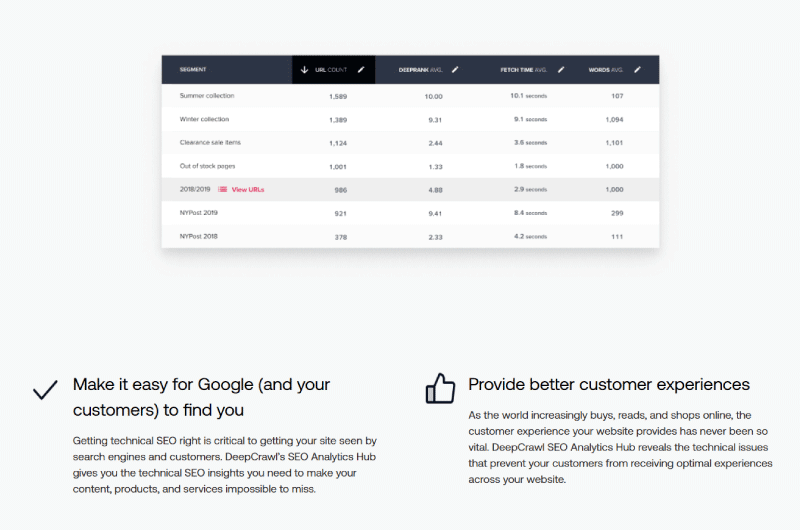
El objetivo es simplificar la detección de fallas en la arquitectura de su sitio proporcionando datos como páginas huérfanas que generan tráfico.
La herramienta le brinda una visión clara de la salud técnica de su sitio web e información procesable que puede usar para mejorar la visibilidad de SEO y convertir el tráfico orgánico en ingresos.
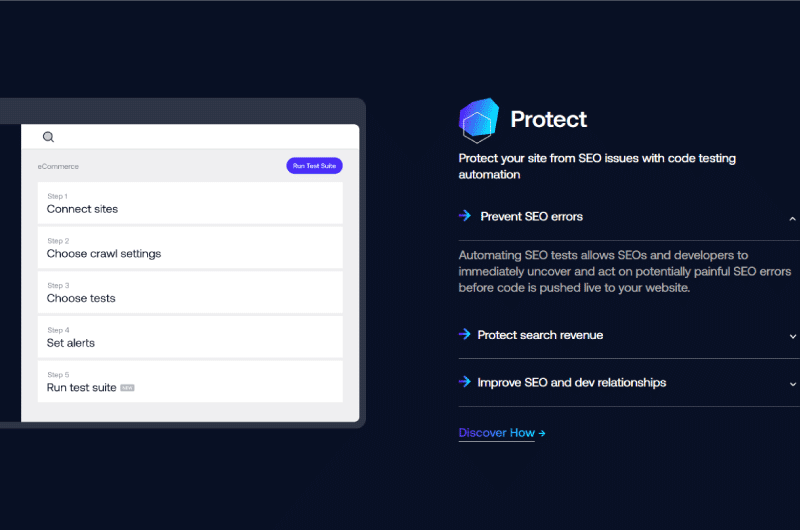
La configuración de un sitio web para el rastreo se puede realizar en cuatro sencillos pasos.
Cuando se registra para una prueba gratuita de Deep Crawl, se le redirige al panel del proyecto. El segundo paso es elegir las fuentes de datos para la exploración.
Siguiendo las instrucciones, puede configurar rápidamente su sitio web y pasar a las cosas más importantes:
Paneles
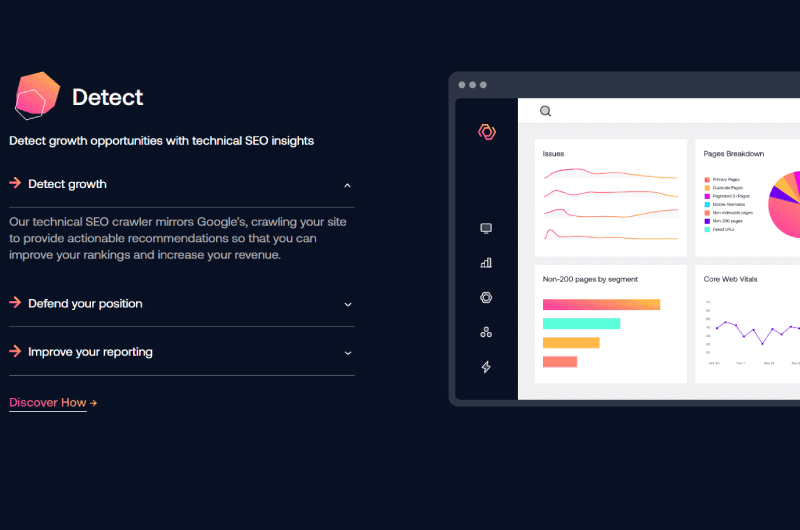
Cuando Deep Crawl termina de rastrear un sitio web completo, muestra en un panel bastante intuitivo una vista global y precisa de todos los archivos de registro identificados.
En un primer gráfico podemos leer un completo y rápido desglose de todas las solicitudes realizadas por los usuarios de dispositivos móviles como ordenadores.
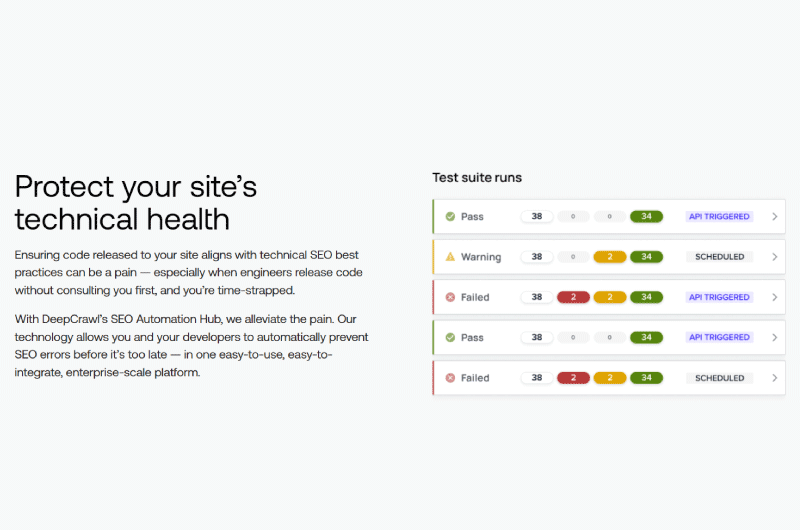
A esto le sigue un resumen que no solo destaca los principales problemas con el rastreo del sitio web, sino también una lista de todos los elementos que pueden, de una forma u otra, impedir que se indexen las páginas del sitio web.
Deep Crawl sustrae y analiza todos los datos de carga útil de todas las fuentes que vinculó durante la configuración y los combina con datos de archivos de registro para calificar mejor cada problema detectado.
Observamos en este informe que muchas de las URL enumeradas en los mapas de sitio XML no se han solicitado.
Y esto puede deberse a una débil vinculación de las páginas entre ellas oa una profundidad bastante importante de la arquitectura del sitio hasta el punto de que se necesita un robot más potente para llegar a las páginas web del fondo.
Además, cuando los mapas de sitio XML quedan obsoletos, ya no reflejan las URL activas de ninguna manera.
En este caso, podemos deducir que un presupuesto de rastreo es muy importante, especialmente si tienes un sitio web grande.
Análisis más
profundo La sección Análisis más profundo se caracteriza por dos conjuntos de datos que son «Accesos de bot» y «Problemas».
El primer conjunto de datos llamado »Bot Hits» enumera el conjunto de URL solicitadas teniendo en cuenta no solo el número total de solicitudes, sino también los dispositivos utilizados para realizar las solicitudes.
La idea es ayudarlo a ver en qué páginas se enfocan más los rastreadores cuando rastrean su sitio web y las áreas de deficiencia, como páginas potencialmente obsoletas o huérfanas.
También hay una opción de filtro que le permite detectar todas las URL que probablemente se vean afectadas por los problemas de unos pocos.
Además, la «Problemas» muestra cualquier problema que afecte a su dominio con todos los detalles del error según los datos del archivo de registro.
Estos son esencialmente:
Páginas de error
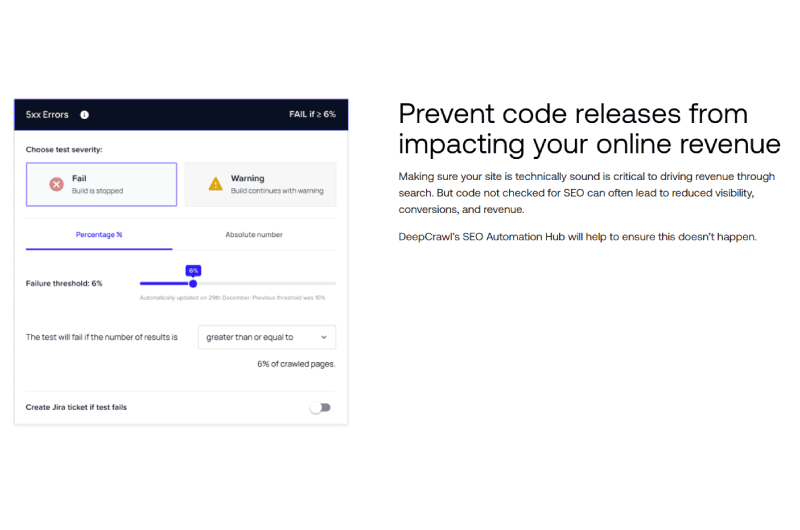
Esta sección proporciona una descripción general de todas las URL que se encuentran en el archivo de registro durante el rastreo, pero que devuelven un código de respuesta del servidor 4XX o 5XX.
Estas son las URL que pueden causar grandes problemas al sitio web y necesitan una reparación urgente.
Páginas no indexables
Esta sección destaca las URL que los motores de búsqueda pueden rastrear, pero que están configuradas como noindex y contienen una referencia canónica a una URL alternativa o están completamente bloqueadas en robots.txt, por ejemplo.
Este informe muestra las URL teniendo en cuenta la cantidad de URL accesibles en los archivos de registro.
En realidad, no todas las URL aquí son necesariamente malas, pero es una excelente manera de resaltar el presupuesto de rastreo real asignado a páginas específicas, lo que le permite hacer una división justa si es necesario.
Páginas no autorizadas
Cuando bloquea ciertas URL de su sitio para que no se indexen en un archivo robots.txt, esto no significa que no habrá solicitudes en el archivo de registro.
Esta sección le permite identificar las URL de su sitio web que se pueden indexar a pesar de estar bloqueadas en un archivo robots.txt.
También le permite ver qué elementos faltan en ciertas páginas para que los rastreadores de los motores de búsqueda no las indexen como le hubiera gustado, por ejemplo, páginas sin elatributo noindex.
Páginas indexables
Aquí puede ver todas las URL de su sitio web que los motores de búsqueda pueden indexar fácilmente.
Lo especial de esta característica es que también le muestra una lista de URL que no generaron ninguna consulta de motor de búsqueda en los archivos de registro proporcionados.
En la mayoría de los casos, se trata de páginas huérfanas, es decir, que tienen pocos enlaces con el resto de páginas del sitio web.
Páginas de escritorio y alternativas móviles
Estos dos informes le permiten ver si sus páginas se muestran correctamente en los dispositivos para los que las configuró.
Esta vista es particularmente útil para sitios que utilizan una versión móvil independiente o para sitios adaptables y receptivos. También es una mejor manera de ver URL menos solicitadas, probablemente antiguas o irrelevantes.






 Alexandre MAROTEL
Alexandre MAROTEL