Les moteurs de recherche ne cessent d’apporter des améliorations à leur système. Google, quant à lui, implémente plus de 500 changements à son algorithme chaque année.
A tel point qu’aujourd’hui, il serait plus pertinent de parler « des » algorithmes de Google.
Heureusement pour les professionnels du SEO, la plupart de ces modifications sont pratiquement imperceptibles du fait de leurs subtilités.
En effet, le plus grand nombre des changements ont un impact trop faible pour être perçus dans les SERPs.
Mais Google connaît certaines améliorations majeures dont les effets se font nettement remarquer. Il s’agit notamment de RankBrain dont l’existence a été publiquement annoncée dans un article deBloomberg, le 26 octobre 2015.
Bien que sa date de déploiement exacte ne soit pas connue, cette mise à jour a officiellement marqué l’utilisation de l’Intelligence Artificielle (IA) dans les produits de Google.
Quelques années après cette annonce, RankBrain reste en partie un mystère quant à son fonctionnement. En effet, Google ne semble vouloir dévoiler les secrets de son système.
Cette situation a laissé place à des spéculations et de vives polémiques dans la communauté SEO.
C’est pour pourquoi suite à mes nombreuses recherches, j’ai décidé de rédiger cet article qui va tenter d’apporter des points d’éclairages sur RankBrain. Comme bonus, vous aurez l’occasion de découvrir la place qu’occupent les signaux de l’expérience utilisateur (UX) dans le processus de classement de Google.
Pour faire cet article, je me suis reposé sur beaucoup de sources différentes, afin d’appuyer mon propos. Vous verrez notamment plusieurs assertions issues directement de Google et de ses ingénieurs.
Ainsi, que des analyses pointues de certains experts de l’industrie du SEO pour avoir une compréhension parfaite de RankBrain et de l’UX.
Si vous êtes prêt, allons-y !
Chapitre 1.Qu’est-ce que RankBrain et Pourquoi Google l’utilise ?
1.1. Qu’est-ce que RankBrain ?
L’existence de RankBrain a été connue du public le 26 octobre 2015 grâce à l’article de Bloomberg :
Le titre traduit en français ressemble à ceci :
« Google passe de la recherche lucrative sur le Web à l’intelligence artificielle.
A travers l’annonce, Google indique clairement l’implémentation de l’intelligence artificielle dans son système, que l’entreprise va nommer RankBrain.
Rankbrain est une machine d’apprentissage automatique ou « machine learning » que Google utilise afin de traiter ses résultats de recherche.
Il s’agit d’un produit issu de l’intelligence article (IA) qui permet aux programmes informatiques de réaliser des tâches que seuls les humains sont capables d’effectuer avec leurs intelligences ou processus mentaux.
Comme vous pouvez l’imaginer, Google a créé RankBrain avec cette technologie afin d’améliorer les résultats qu’il fournit à ses utilisateurs.
Mais avant d’aborder comprendre comment Google utilise RankBrain, il est judicieux de comprendre d’abord ce qu’est l’IA.
1.1.1. Qu’est-ce que l’IA et les machines d’apprentissage automatique ?
Selon Larousse, l’intelligence artificielle (IA) est :
« L’ensemble des théories et des techniques mises en œuvre en vue de réaliser des machines capables de simuler l’intelligence ».
En d’autres termes, l’IA a pour objectif de permettre aux ordinateurs de devenir aussi intelligents que les humains par des approches mathématiques et statistiques.
Autrement dit, ils seront capables :
D’apprendre grâce à l’expérience ;
D’organiser leur mémoire ;
De raisonner afin de résoudre des problèmes d’eux même.
L’intelligence artificielle est généralement mentionnée pour faire référence à des programmes d’ordinateurs qui sont conçus de cette façon. Alors, comment cela se passe concrètement ?
En 2015, Google a tenu l’événement « Machine Learning 101 » pour expliquer comment les machines d’apprentissages automatique fonctionnent.
Source : MartchToday
Cet évènement s’est déroulé sur son campus à Mountain View et animé par plusieurs experts de Google.
Danny Sullivan qui était un journaliste et analyste a tenu un « live-blogging » pour dévoiler les points les plus importants de l’événement.
Mais d’abord, qui est Danny Sullivan et qu’est ce qui me permet de considérer ses propos ?
Remarque : Dans mon article, j’ai considéré les propos de plusieurs personnes que j’ai néanmoins pris la peine de présenter afin que vous puissiez vous faire un avis sur le degré crédibilité des informations.
Danny Sullivan est un googler depuis octobre 2017 et son rôle est d’aider le public à mieux comprendre le moteur de recherche Google.
Avant d’intégrer Google, il était un journaliste et analyste dans la sphère du webmarketing ainsi que des moteurs de recherche.
Une source particulièrement crédible, n’est-ce pas ?
Revenons à son « live-blogging » qu’il a tenu sur le « maching learning 101 » organisé par Google.
Il en ressort que le système des machines d’apprentissage automatique se compose de trois parties principales :
Modèle : Le système qui fait des prédictions ou des identifications.
Paramètres : Les signaux ou facteurs utilisés par le modèle pour former ses décisions.
Apprenant : Le système qui ajuste les paramètres – et à son tour le modèle – en examinant les différences entre les prévisions et les résultats réels.
Il faut l’avouer : c’est assez difficile à digérer !
Même Danny le fait savoir dans son article sur le sujet :
Pour faire simple, tout commence à partir d’un modèle que la machine va utiliser pour son apprentissage. Généralement, ce modèle est introduit par un humain à partir de certaines données.
La machine va utiliser le modèle et les données pour s’entraîner ou résoudre des tâches pratiques qui ne sortent pas du cadre de son modèle.
Une fois que le modèle est assimilé par la machine, il sera possible de lui fourni de nouvelles données ou problématique à résoudre qui ne suivent pas nécessairement le modèle prédéfini.
La machine va tenter de résoudre ces tâches auxquelles il n’était pas programmé en essayant plusieurs approches.
Selon les retours sur la qualité de ses réponses ou résultats, le programme réajuste les paramètres et ensuite le modèle.
Source : Martechtoday
Ce processus se fait en continu, ce qui implique que les machines d’apprentissage automatique apprennent constamment, pour peu qu’elles soient actives.
En définitive, l’apprentissage automatique est l’endroit où un ordinateur ou programme automatique apprend de lui-même à faire quelque chose, plutôt que d’être enseigné par des humains ou de suivre une programmation détaillée.
C’est d’ailleurs pour cette raison que Paul Haahr, un ingénieur de Google, a affirmé que la firme ne comprend pas complètement RankBrain :
En effet, Google sait comment fonctionne son outil, mais ne sait pas toujours ce qu’il fait. Comme semblent le confirmer certains experts toujours dans l’article de Search Engine Roundtable :
Google doesn't quite understand what RankBrain is doing says @haahr#smx
Consulter cet article où Danny détail un exemple concret donné par Greg Corrado, le senior chez Google qui a annoncé l’existence de RankBrain dans l’article de Bloomberg :
Vous avez également Wikipédia qui donne beaucoup de détails et de référence sur l’apprentissage automatique.
Toutefois, vous aurez toutes les informations et des exemples concrets pouvant vous permettre d’appréhender le fonctionnement de RankBrain.
1.1.2. Quelle est la relation entre RankBrain et les algorithmes de Google ?
RankBrain fait partie de l’algorithme de recherche global de Google : Humminbird.
L’entreprise Moz le confirme dans son article sur Google Hummingbird :
« Contrairement aux précédentes mises à jour de Panda et Penguin qui ont été initialement publiées en tant qu’add-ons à l’algorithme existant de Google, Hummingbird a été cité comme une refonte complète de l’algorithme principal. ».
De plus, Danny Sullivan le confirme dans son article sur Hummingbird :
Il utilise cette métaphore :
« C’était comme si le moteur était équipé d’un nouveau filtre à huile ou d’une pompe améliorée. Hummingbird est un tout nouveau moteur, bien qu’il continue à utiliser certaines des mêmes parties de l’ancien, comme Penguin et Panda ».
Pour connaître l’évolution de Google depuis ses débuts, jusqu’à Hummingbird, vous pouvez suivre cette présentation du googler Amit Singhal :
En effet, ce sera avec Hummingbird que Google pourra mettre davantage l’accent sur les requêtes en langage naturelle. Et ceci, en tenant compte du contexte et du sens de la requête dans son ensemble plutôt que des mots pris de façon individuelle.
L’algorithme complet de Google est Hummingbird et il faut considérer RankBrain comme une partie.
Cette conclusion est tirée de l’article de Bloomeberg dans lequel Greg Corrado indiquait clairement que RankBrain prenait seulement en charge les 15% de requêtes que le système de Google n’a jamais encore traité.
La machine learning de Google ne prenait qu’une partie des requêtes du système. Contrairement à l’algorithme central Hummingbird qui est censé gérer toutes les requêtes du moteur de recherche.
Il devient légitime de se demander quelle place occupe RankBrain dans l’algorithme de Google.
1.1.3. RankBrain est le troisième signal le plus important
Greg Corrado explique à travers l’article de Bloomberg que :
«En quelques mois, RankBrain est devenu le troisième signal le plus important contribuant au résultat d’une requête de recherche. »
Cela étant, quels sont donc les deux autres signaux les plus importants de Google ?
La réponse à cette question a été donnée par Andrey Lipattsev de Google :
Il indique dans le podcast précédent :
« Je peux vous dire de quoi il s’agit. Il s’agit du contenu. Et des liens pointant vers votre site. ».
Par conséquent, les trois signaux de classement les plus importants de Google sont :
Les backlinks ;
Le contenu ;
RankBrain.
Il n’y a pas de précision sur l’ordre d’importance de chacun de ces signaux. On ne pourra donc pas faire un classement proprement dit.
Néanmoins, cela prouve qu’il est très important de comprendre comment fonctionne cette machine learning de Google. Et ceci, dans le but d’élaborer des stratégies efficaces afin d’optimiser le référencement de votre site web dans les SERPs.
A ce niveau, il est légitime de se demander pourquoi Google a lancé RankBrain.
1.2. Pourquoi Google a lancé RankBrain ?
J’ai déchiffré fondamentalement deux principales raisons pour lesquelles Google a lancé sa machine learning.
Il s’agit :
Des difficultés de Google à interpréter les requêtes qu’il n’avait jamais traitées ;
Du fait que Google devait coder ses algorithmes à la main pour apporter n’importe quel changement.
1.2.1. Des difficultés de Google à interpréter les requêtes
Depuis sa création, Google a toujours essayé de s’améliorer afin de déterminer précisément ce que ses utilisateurs souhaitent avoir comme réponses.
A ses débuts, le moteur de recherche se basait principalement sur la présence sur les pages web des mots présents dans une requête pour afficher ses résultats.
Par exemple, si vous recherchez « acheter des fruits et légumes », le moteur de recherche va s’occuper de fournir les pages qui contiennent ces mots.
De plus, la moindre variation dans les expressions utilisées pouvait conduire à des résultats différents.
Par exemple, le moteur de recherche ne pouvait pas donner les mêmes résultats pour « vêtement » et « vêtements ». Il en va de même pour les requêtes « les meilleures bottes de jardin » et « les meilleures chaussures de jardin ».
Les résultats pouvaient considérablement varier avec de simples modifications au niveau des requêtes.
Ainsi, le moteur de recherche considérait lui même qu’il y avait une marge de progression dans le but de donner les meilleurs résultats à ses utilisateurs.
Mais le problème ne s’arrête pas. Car ce fonctionnement a donné l’opportunité à certains référenceurs “black hat” de répéter des mots et expressions dans leur contenu pour se retrouver en tête des résultats. Et ceci, même si leur contenu est de mauvaise qualité.
Google a beaucoup évolué depuis ce temps. Le moteur de recherche parvient désormais à détecter et punir les sites web qui font usages des pratiques SEO Black Hat avec notamment les algorithmes Penguin et Panda.
Du côté des requêtes, Google a fait également de grands progrès.
En effet, le moteur de recherche arrive de plus en plus à comprendre les requêtes, et à les associer entre elles si elles veulent dire la même chose :
Les meilleures bottes de jardin :
Les meilleures chaussures de jardin :
Le moteur essaie de comprendre ce que vous recherchez ou l’intention de recherche, comme un humain le ferait. Mais pour en arriver là, Google a fait plusieurs apports à son système.
Hummigbird, Stemming et le Knowledge Graph ont incarné la transition de Google à considérer les mots comme des “entités” et non une simple composition de caractères.
En effet, Google a adopté Word Stemming en 2003 afin d’appréhender les variations d’un même mot. Par exemple, Google comprend que « mangue », « mangues » et « manguier » veulent sensiblement dire la même chose. Ce qui lui permet de donner des résultats similaires pour ces termes.
Google ne s’arrête pas à la variation des mots et arrive à déterminer le « synonyme » des mots. Le moteur de recherche arrive à faire des passerelles entre les termes, par exemple avec « SEO » et « référencement naturel », dans la mesure où les résultats seront proches, voir sensiblement les mêmes pour ces requêtes.
Le Knowledge Graph, quant à lui, a été un moyen pour Google de devenir encore plus intelligent en ce qui concerne les relations entre les mots.
Le moteur de recherche a appris à rechercher des « choses et non des chaînes de caractères » (things, not strings), comme le décrit Amit Singhal de Google :
« Prenez une question comme [taj mahal]. Depuis plus de quarante ans, la recherche consiste essentiellement à faire correspondre les mots-clés aux requêtes. Pour un moteur de recherche, les mots [taj mahal] n’ont été que cela – deux mots. Mais nous savons tous que [taj mahal] a une signification beaucoup plus riche. Vous pourriez penser à l’un des plus beaux monuments du monde, ou à un musicien lauréat d’un Grammy Award, ou peut-être même à un casino à Atlantic City, NJ. Ou, selon la dernière fois que vous avez mangé, le restaurant indien le plus proche. C’est pourquoi nous avons travaillé sur un modèle intelligent – en langage geek, un « graph » – qui comprend les entités du monde réel et leurs relations les unes avec les autres : things, not strings. »
Le « strings », employé ici, désigne essentiellement le traitement des recherches grâce uniquement aux chaînes de lettres.
Par exemple, les résultats vont présenter les pages qui comportent exactement le mot « Paris » lorsqu’un utilisateur fera cette requête.
Le « things » signifient qu’au lieu de cela, Google comprend que lorsque quelqu’un cherche « Paris », ils veulent probablement dire la capitale de la France, un lieu réel avec des liens à :
D’autres lieux ;
Monuments ;
Activités ;
Personnes ;
Etc…
Le Knowledge Graph est une base de données sur les choses dans le monde et les relations entre elles.
C’est pourquoi vous pouvez faire une recherche comme « date de construction du plus haut monument de paris » et obtenir une réponse sur la « Tour Eiffel » comme dans l’image ci-dessous, sans jamais utiliser le nom :
Mais alors que le Knowledge Graph se fonde sur les bases de données existantes pour voir les liens entre les concepts, RankBrain apprend comment les utilisateurs relient les mots et les concepts lorsqu’ils font des recherches.
1.2.2. RankBrain permet à Google de traiter certains types de requêtes
Lors de l’annonce dans l’article de Bloomberg, Greg Corrado affirmait :
« Depuis quelques mois, une « très grande fraction » des millions de requêtes par seconde que les gens saisissent dans le moteur de recherche de l’entreprise sont interprétées par un système d’intelligence artificielle […] Si RankBrain voit un mot ou une phrase qu’il ne connaît pas, la machine peut deviner quels mots ou phrases peuvent avoir un sens similaire et filtrer le résultat en conséquence, ce qui le rend plus efficace pour traiter les requêtes de recherche jamais vues auparavant. ».
De son assertion, on peut affirmer que RankBrain permet à Google de traiter plus facilement les requêtes que ses utilisateurs n’avaient encore jamais recherchées.
En effet, le moteur de recherche doit constamment faire face à des requêtes que personne n’avait jamais encore recherchées.
Les statistiques montrent qu’environ 15% des requêtes journalières sur Google n’ont jamais fait l’objet de recherche. Ce que Google confirme dans son blog en 2017 :
« Il y a des trillions de recherches sur Google chaque année. En fait, 15 % des recherches que nous voyons tous les jours sont nouvelles, ce qui signifie qu’il y a toujours plus de travail à faire pour présenter aux gens les meilleures réponses à leurs questions provenant d’un large éventail de sources légitimes. »
Actuellement, le moteur de recherche traite 5,8 milliards de requêtes par jour. Si 15% ne sont pas connues, il y a près de 870 millions de requêtes totalement nouvelles auxquelles le moteur de recherche doit donner des réponses.
Si la plupart des requêtes n’ont jamais fait l’objet d’une recherche auparavant, il est clair que Google devait repartir de zéro pour comprendre ce que les gens recherchent.
D’ailleurs, la plupart des recherches qu’on effectue ne contiennent pas les expressions exactes concernant ce que nous recherchons. On aime bien laisser Google deviner l’information que nous recherchons, n’est-ce pas ?
Sachez qu’avant, le moteur de recherche avait réellement du mal à deviner ce que ses utilisateurs voulaient.
C’est pourquoi RankBrain a été lancé en 2015 et pour essayer de donner des solutions efficaces à ces genres de requêtes. Nous verrons dans le prochain chapitre, comment il fonctionne concrètement.
Pour le moment, gardez à l’esprit que Rankbrain fonctionne bien pour faire le lien entre une requête qu’il a déjà traitée et une nouvelle requête qu’il ne connaît pas encore.
Par exemple, supposons que beaucoup de personnes fassent la recherche « construire un abri de jardin ».
Avec les données recueillies, RankBrain comprend qu’un « abri de jardin » est une sorte de bâtiment.
A votre niveau si vous recherchez « construire un bâtiment de jardin », qui dans le cadre de notre exemple n’aura jamais encore fait l’objet de recherche sur Google (bien sûr cet exemple n’est pas réel).
Google ne vous présentera pas nécessairement les pages incluant des mots :
Construire ;
Bâtiment ;
Jardin.
Vous avez un tel résultat :
Google a compris que vous cherchiez plutôt comment construire « un abri de jardin » et non « un bâtiment de jardin », comme un humain l’aurait fait !
Il en va de même pour cette requête particulièrement insensée composée de 18 mots :
Et
Bien que le premier mot clé ne soit pas très précis, j’ai sensiblement les mêmes résultats avec le second qui est composé uniquement d’un seul mot.
Les 18 mots peuvent sembler beaucoup, mais RankBrain est également meilleur dans la gestion des longues requêtes.
En effet, Gary Illyes indique que RankBrain est :
« Cela fonctionne mieux pour les requêtes de longue traîne et les requêtes que nous n’avons jamais vues. ».
En effet, 64 % des recherches sont constituées de 4 mots et plus :
Les internautes utilisent des phrases précisent qui décrivent ce qu’ils veulent comme réponse :
Si la gestion d’une poignée de mots pouvait être un problème pour Google, il ne fait pas de doute que la difficulté va s’accentuer si le nombre de mots augmente.
Un autre facteur qu’il faut prendre en compte est la recherche vocale qui évolue rapidement :
Source : Justcreative
Les statistiques montrent que d’ici 2020, 50 % des recherches seront vocales.
Or, les utilisateurs utilisent plus de mots lorsqu’ils effectuent une recherche vocale :
Ces recherches conversationnelles ressemblent davantage à la façon dont les gens parlent naturellement.
Cela signifie qu’il est très important pour les moteurs de recherche de comprendre :
Les mots les plus importants dans une requête ;
Ce que les mots signifient réellement lorsqu’ils sont combinés.
C’est dans cette logique que Google a développé sa machine d’apprentissage automatique « RankBrain » qui a été d’abord utilisé pour mieux comprendre les requêtes des utilisateurs.
Gary Illyes le fait comprendre à travers l’une de ses discussions sur Twitter :
« Laissez-moi essayer d’expliquer une dernière fois : Rankbrain nous permet de mieux comprendre les requêtes. »
Lemme try one last time: Rankbrain lets us understand queries better. No affect on crawling nor indexing or replace anything in ranking
— Gary 鯨理/경리 Illyes (so official, trust me) (@methode) March 18, 2016
Tous changements que Google apporte à son système visent généralement à améliorer l’expérience de ses utilisateurs. RankBrain ne fait pas exception à la règle et son lancement a permis à la firme de régler un autre problème.
1.2.2. Google codait ses algorithmes à la main
Avant de lancer RankBrain, Google codait tous ses algorithmes à la main.
Cette remarque a été faite par Brian Dean dans son article sur RankBrain.
Mais d’abord, qui est Brian Dean ?
Brian Dean est un expert SEO et le fondateur de Backlinko :
Ses prix et distinctions en disent long sur lui :
Brian indique que ce sont les ingénieurs de Google qui s’occupaient d’effectuer toutes les modifications au niveau de son système.
Cette infographie vous permet de comprendre le processus :
Mais avec l’arrivée de RankBrain, les choses ont changé puisqu’il s’occupe de tester et d’implémenter les changements lui même :
Bien évidemment les ingénieurs de Google continuent de travailler sur les algorithmes de leur système.
Mais RankBrain peut faire une partie du travail en ajustant lui-même les résultats qu’il suggère. En effet, une fois qu’il propose des résultats aux utilisateurs, il évalue la réussite de ce qu’il a proposé.
Dans le cas où les résultats ont satisfait l’intention des utilisateurs, les modifications sont maintenues.
Dans le cas contraire, l’ancienne configuration ou algorithme est réactivé.
Alors, RankBrain est-il plus efficace que les ingénieurs humains de Google ?
Greg Corrado a fait savoir que pour déterminer la meilleure option entre ses ingénieurs humains et la machine, la firme a effectué un test.
Ils ont demandé à un groupe d’expert et à RankBrain d’identifier les meilleures pages sur certaines requêtes.
Le résultat est concluant puisque la machine d’apprentissage automatique à réaliser plus de performances avec une précision de prédiction de plus de 10% que celle des experts :
Les résultats sont concluants et RankBrain semble accomplir excellemment les tâches pour lesquelles il a été créé. Maintenant, comment l’IA de Google fonctionne concrètement ?
2.1. Vous êtes le professeur et RankBrain est votre élève
Pour appréhender facilement le fonctionnement de RankBrain, je vais utiliser un exemple.
Imaginez qu’un élève passe quotidiennement un test composé de 5,8 milliards de questions, écrites par des millions d’enseignants.
Chaque enseignant donne son feedback après que l’élève ait répondu à une question. Il fait savoir à l’élève :
C’est parfait : La première réponse est la bonne !
Ce n’est pas encore parfait : La meilleure réponse se trouve un peu plus bas ;
Non, tu n’as pas répondu à ma question : Je demandais plutôt ceci.
L’élève se souvient des rétroactions de tous ses professeurs pour le test de demain, où seulement 15 % seront des questions inconnues.
Par analogie, l’élève représente bien RankBrain et chaque personne qui fait une recherche sur Google est l’un de ses enseignants.
Essayons de voir comment Google pourrait utiliser son IA.
2.2. Comment RankBrain fonctionne ?
Comme nous l’avons déjà vu, les ingénieurs de Google devaient programmer manuellement les algorithmes de Google pour qu’ils fassent les choses différemment.
RankBrain, quant à lui, apprend directement de la façon dont nous interagissons avec ses résultats.
Gary Illyes de Google le décrit de cette façon :
« [RankBrain] examine les données sur les recherches antérieures et en se basant sur ce qui a bien fonctionné pour ces recherches, il essaiera de prédire ce qui fonctionnera le mieux pour une certaine requête. Cela fonctionne mieux pour les requêtes de longue traîne et les requêtes que nous n’avons jamais vues. »
Par conséquent, le système est complètement autonome et n’a pas besoin qu’on lui indique que tel résultat est mauvais et qu’il faut régler le problème de telle manière.
RankBrain a déjà des critères, notamment les autres signaux de classement, qui lui permettent de savoir si un résultat répond parfaitement à une requête ou non. Ce que je vais décrire dans le prochain chapitre.
Il dispose d’une grande base de données d’anciens résultats de recherche qui lui permettent de prendre de bonnes décisions.
C’est la raison principale pour laquelle RankBrain a réalisé de plus belles performances que les ingénieurs de Google.
RankBrain prédit ce qui fonctionnera le mieux, le teste, et si le changement fonctionne, il le maintien.
RankBrain ne s’arrêter pas seulement à l’amélioration des résultats organiques dans la mesure où il est capable également de peaufiner les résultats sur Google Suggest.
2.3. Est-ce que RankBrain affecte les recherches suggérées ?
Moz a spéculé que RankBrain utilise aussi certains facteurs pour proposer des résultats pertinents :
« Pre-RankBrain, Google a utilisé son algorithme de base pour déterminer les résultats à afficher pour une requête donnée.Post-RankBrain, on croit que la requête passe maintenant par un modèle d’interprétation qui peut appliquer des facteurs possibles comme l’emplacement du chercheur, la personnalisation et les mots de la requête pour déterminer l’intention réelle du chercheur. En discernant cette véritable intention, Google peut fournir des résultats plus pertinents. »
Othertinkgroup va un peu plus loin et montre un scénario dans lequel RankBrain pourrait jouer un rôle dans le Google Suggest. Je vais donner un exemple similaire à ce qu’ils ont donné.
Supposons que je voudrais faire une recherche sur « Antoine Griezmann » joueur français de France de Football.
J’entre les deux premières lettres « an » du prénom « antoine », Google affiche les suggestions :
Vous pouvez voir qu’il n’y a pas « Antoine Griezmann » dans les suggestions.
Je m’arrête pour l’instant à ce niveau et je vais d’abord rechercher « équipe football de France » :
Ensuite, j’entre les deux premières lettres de Antoine « an » :
Vous pouvez voir que « Antoine Griezmann » fait désormais partie des recommandations. Même s’il n’est pas en première position, il fait néanmoins partie des suggestions.
Alors que jusque-là, je n’ai pas encore effectué une requête portant sur le nom « Antoine Griezmann ».
La même chose se produit pour « Kylian mbappé » lorsque j’insère les deux première lettre « ky » :
Il est important de noter que Google comprend suffisamment bien les relations entre les choses pour deviner ce que vous chercherez lorsque vous souhaitez effectuer une prochaine recherche. Qu’est-ce que cela peut bien signifier pour un business en ligne ?
Supposons que vous avez rédigé un contenu d’autorité sur « la création de backlinks ».
Votre guide offre une immense valeur ajoutée aux utilisateurs. Lorsque vos lecteurs vont retourner à la barre de recherche après avoir trouvé ce dont ils ont besoin, Google proposera des recherches connexes.
Le moteur de recherche pourrait leur donner une autre occasion d’interagir avec votre marque, votre contenu, et finalement votre produit. C’est plutôt intéressant, n’est-ce pas ?
Mais est-ce l’œuvre de RankBrain ? Ce n’est pas certain.
Il est possible que cela ne soit pas l’œuvre de RankBrain mais plutôt une autre manière pour Google d’utiliser l’IA dans son système.
Quoi qu’il en soit, il s’agit d’une façon qui permet à Google de clarifier l’intention du chercheur.
Wired rapporte en 2016 les propos du CEO de Google, Sundar Pichai :
« L’apprentissage machine est un moyen fondamental et transformateur par lequel nous repensons notre façon de tout faire. Nous l’appliquons de manière réfléchie à tous nos produits, qu’il s’agisse de recherche, d’annonces, de YouTube ou de Play. Et nous n’en sommes qu’aux premiers balbutiements, mais vous verrez que nous appliquons systématiquement l’apprentissage automatique dans tous ces domaines. »
Nous savons que RankBrain se concentre sur l’intention de recherche derrière les mots que nous mettons dans la barre de recherche.
Mais si Google incorpore aussi l’apprentissage automatique dans tout ce qu’il fait, il serait peu judicieux de supposer que c’est RankBrain qui impacte Google Suggest.
Cela étant, revenons maintenant à ce que nous savons avec certitude.
RankBrain essaie de comprendre les requêtes en évaluant dans quelle mesure les SERPs antérieurs ont satisfait l’intention du chercheur. La machine learning utilise ensuite ces données pour faire des prédictions sur ce que les gens recherchent vraiment pour la requête.
Ces prédictions proviennent de la vaste compréhension de RankBrain de la façon dont les mots sont reliés entre eux. Ce qui nous amène à la notion de vecteurs de mots.
2.4. Qu’est-ce que les vecteurs de mots ?
Nous avons déjà vu que Google se sert du Knowledge Graph pour relier les mots aux concepts qui existent en relation les uns avec les autres.
Mais cela ne fonctionne qu’avec les informations qui sont présentent dans sa base de données.
Pour aller plus loin avec la machine learning, Google s’est tourné vers les vecteurs de mots puisqu’il avait besoin d’apprendre le sens caché derrière les mots :
Word vectors ou les vecteurs de mots sont la façon dont les machines d’apprentissage automatique de Google ou RankBrain apprennent les nouvelles relations entre les mots.
L’article de Bloomberg vient confirmer ce fait :
« RankBrain utilise l’intelligence artificielle pour intégrer de grandes quantités de langage écrit dans des entités mathématiques – les vecteurs – que l’ordinateur peut comprendre. Si RankBrain voit un mot ou une phrase qu’il ne connaît pas, la machine peut deviner quels mots ou phrases peuvent avoir un sens similaire et filtrer le résultat en conséquence, ce qui le rend plus efficace pour traiter les requêtes de recherche jamais vues auparavant. ».
Pour que cela soit effectif, Google a développé un outil open source nommé « Word2vec » :
Cet outil utilise l’apprentissage automatique et le traitement du langage naturel afin de comprendre de lui-même la signification réelle des mots.
Dans son article sur word2vec, Google montre un exemple de comment il peut apprendre le concept des capitales des pays.
La firme indique :
« Word2vec utilise des représentations distribuées du texte pour saisir les similitudes entre les concepts. Par exemple, elle comprend que Paris et la France sont liées de la même manière que Berlin et l’Allemagne (capitale et pays), et non de la même manière que Madrid et l’Italie. Ce tableau montre à quel point il peut apprendre le concept de capitale, simplement en lisant beaucoup d’articles d’actualité, sans supervision humaine ».
Schématiquement, c’est de cette façon dont word2vec comprend les concepts en faisant des liaisons entre eux.
RankBrain utilise le même système pour déterminer les relations entre les termes et les contenus sur le web dans le but de faire des prédictions pour les requêtes qu’il ne connaît pas.
C’est la raison pour laquelle, Google n’indique pas une façon particulière d’optimiser un site pour RankBrain. En effet, RankBrain n’est pas un « algorithme classique » comme Panda et Penguin.
Nous savons comment éviter les pénalités Penguin et grâce aux directives, nous savons comment satisfaire Panda.
RankBrain d’autre part est un modèle d’interprétation pour lequel on ne peut pas effectuer une optimisation spécifique.
La seule recommandation de Google est d’écrire vos contenus dans un langage naturel afin que les utilisateurs aient le plus de valeur ajoutée possible. Nous allons aborder cet aspect dans les prochaines sections.
Il y a une question qui est encore très importante pour comprendre le fonctionnement de RankBrain.
2.5. Comment RankBrain évalue les résultats qu’il propose ?
La machine d’apprentissage automatique de Google utilise les anciennes données pour essayer de prédire les meilleurs futurs résultats.
Danny Sullivan indique dans son article :
« Tout ce que RankBrain apprend est hors ligne, nous a dit Google. Il prend des lots de recherches historiques et apprend à faire des prédictions à partir de celles-ci. Ces prédictions sont testées, et si elles s’avèrent bonnes, alors la dernière version de RankBrain est mise en ligne. Ensuite, le cycle d’apprentissage en ligne et de test est répété. »
Si les choses se produisent ainsi, comment RankBrain arrive à décider si le résultat qu’il donne est bon ou mauvais ?
On pourrait supposer qu’il y a un score RankBrain comme celui de PageRank.
Mais ce n’est pas le cas !
A ce sujet, il y a eu beaucoup de rumeurs sur le fait que RankBrain donne un score aux pages afin de savoir quoi proposer par la suite.
Google a eu l’occasion de répondre à cette question à de nombreuses reprises. Lors de la conférence SMX Advanced, Danny Sullivan a eu une interview avec Gary Illyes :
A la question de savoir s’il y a un score, Gary fait savoir qu’il n’y en a pas :
En français :
« Danny Sullivan : Existe-t-il un score RankBrain ? Gary Illes : Vous n’avez pas de score. Je pense que la racine de votre question est de savoir si vous pouvez optimiser pour RankBrain – (Rires) ».
S’il n’y a donc pas de score ou un système de notation, comment RankBrain arrive à déterminer la satisfaction des utilisateurs en rapport avec ses résultats ?
Certains experts SEO estiment que RankBrain utilise l’UX ou les signaux de l’expérience utilisateur pour prendre ses décisions. Est-ce le cas ?
La question de savoir si RankBrain utilise les signaux relatifs aux utilisateurs pour effectuer ses classements est un sujet polémique au sein de la communauté SEO.
Alors que certains experts SEO estiment que l’UX ou l’expérience utilisateur n’est pas considéré par RankBrain, d’autres montrent qu’il s’agit d’un facteur important à considérer.
Il est difficile d’obtenir une réponse définitive sur le sujet. D’autant plus que Google ne semble pas vouloir donner des explications éclairées et définitives.
Mais je vous propose de décortiquer cette problématique par étape. Répondons d’abord à la question de savoir si Google prend en compte l’expérience utilisateur pour effectuer ses classements.
Chapitre 3. L’UX peut-il affecté le classement des sites web dans les SERPs ?
Avant tout, je pense qu’il est judicieux de voir quels sont les facteurs liés aux comportements des utilisateurs.
Dans mon article sur la technique de surenchère, j’ai eu l’occasion de parler en détail des métrics concernant l’expérience utilisateur.
Cela peut se résume parfaitement avec ces images :
La question de savoir si Google tient compte des signaux de l’expérience utilisateur pour classer les sites web fait également polémique dans l’univers du SEO.
Je vais tenter de répondre à la question avec des avis de Google sur le sujet et quelques études effectuées par quelques géants de l’industrie du SEO.
3.1. Google tient compte de l’UX pour son classement
3.1.1. Google considère les utilisateurs comme les juges les plus fiables
En 2015, Google a publié un brevet portant sur thème « Modifier le classement des résultats de recherche en fonction des commentaires implicites des utilisateurs et d’un modèle de biais de présentation » :
Google indique :
« Par exemple, les réactions des utilisateurs à des résultats de recherche particuliers ou à des listes de résultats de recherche peuvent être mesurées, de sorte que les résultats sur lesquels les utilisateurs cliquent souvent seront mieux classés. L’hypothèse générale d’une telle approche est que les utilisateurs de recherche sont souvent les meilleurs juges de la pertinence, de sorte que s’ils choisissent un résultat de recherche particulier, il est susceptible d’être pertinent, ou au moins plus pertinent que les alternatives présentées. ».
Ce brevet de Google montre clairement que les « réactions des utilisateurs » peuvent être mesurées et peuvent également affecter le classement dans les SERPs.
Néanmoins, je ne vais pas faire une conclusion hâtive et je vais prendre le temps de creuser encore plus.
3.1.2. Les moteurs de recherche peuvent collecter des informations sur le mouvement du curseur
Bien que Google soit le moteur de recherche qui détient la plus grande part du marché, il est possible d’avoir quelques indices auprès d’autres entités.
En 2012, Microsoft qui gère Bing a publié un article sur : « L’amélioration des modèles de recherche à l’aide de l’activité Curseur de la souris » :
La compagnie montre :
« Tout comme les clics fournissent des signaux de pertinence dans les résultats de recherche, le survol et le défilement du curseur peuvent être des signaux implicites supplémentaires. Nous trouvons que le survol et le défilement du curseur sont des signaux nous indiquant quels résultats de recherche ont été examinés, et nous utilisons ces interactions pour révéler les variables latentes dans les modèles de recherche afin de calculer plus précisément l’attrait et la satisfaction des documents. L’exactitude est évaluée en calculant dans quelle mesure notre modèle utilisant ces paramètres peut prédire les clics futurs pour une requête particulière. Nous sommes en mesure d’améliorer les prédictions de clics par rapport à un modèle de recherche de base pour les résultats de recherche les mieux classés en utilisant les données de journal supplémentaires. ».
Bien qu’il soit un peu difficile de comprendre l’enjeu de quelques termes, il est possible de comprendre le message que cet article passe.
Microsoft semble être en mesure de connaître le mouvement du curseur de ses utilisateurs et de prédire ensuite les résultats qui seront cliqués.
Google est-il capable de faire pareil ? Je pense qu’il n’y a pas de doute que le moteur de recherche le plus populaire soit en mesure d’avoir ces mêmes données et d’agir en conséquence.
3.1.3. Google peut connaître le temps passé sur un article donné
Restons dans le cadre des brevets et voyons quelle autre donnée Google est capable de connaître.
En 2015, le moteur de recherche Google a publié un brevet intitulé : « Méthodes et systèmes pour améliorer un classement de recherche utilisant des informations sur les articles ».
On peut lire :
« Les données de durée peuvent inclure, par exemple, le temps que l’utilisateur passe sur un article, comme une page Web. En outre, les données sur la durée peuvent inclure le temps que l’utilisateur passe sur un article, comme une page Web hébergée par une autre page Web. Par exemple, le temps qu’un utilisateur passe sur www.google.com/search/images.html peut être attribué, en partie, au temps passé sur l’hôte www.google.com. Les données d’accès peuvent inclure, par exemple, le nombre de fois que l’utilisateur consulte un article ou ouvre et entre ou interagit avec un article […] Les pages Web qui sont consultées beaucoup plus longtemps peuvent se voir attribuer des notes de classement plus élevées. En déterminant la durée de consultation d’une page Web, la présente invention peut déterminer, entre autres choses, si une activité de défilement ou autre est effectuée sur une page pour indiquer que l’utilisateur consulte effectivement la page et n’a pas simplement laissé une page Web ouverte en menant une autre activité. »
Voilà une autre information qui vient appuyer le fait que Google est en mesure d’utiliser les données de ses utilisateurs pour effectuer son classement.
Ici, il s’agit du temps passé sur la page web d’un site web. Plus le temps passé par les utilisateurs sur votre site web augmente, plus vos pages auront tendance à mieux se positionner.
Quelles autres données Google peut-il collecter ?
Je pense que le moteur de recherche peut avoir accès à beaucoup d’informations sur le comportement des utilisateurs dans le but de proposer des résultats pertinents.
Alors, par quel moyen peuvent-ils collecter les informations des utilisateurs ?
3.1.4. Google est capable de collecter les données de ses utilisateurs par les navigateurs
En 2012, Google a publié un autre brevet intitulé : « Classement des documents en fonction du comportement de l’utilisateur et/ou des données de caractéristiques » :
Le moteur de recherche indique :
« Les données relatives au comportement de l’utilisateur peuvent être obtenues à partir d’un navigateur Web ou d’un assistant de navigateur associé à des clients. Un assistant de navigateur peut inclure du code exécutable, tel qu’un plug-in, une applet, une bibliothèque de liens dynamiques (DLL), ou un type similaire d’objet ou de processus exécutable qui fonctionne conjointement (ou séparément) avec un navigateur Web. Le navigateur Web ou l’assistant de navigateur peut envoyer au serveur des informations concernant un utilisateur d’un client. »
Google est en mesure de collecter les données des utilisateurs grâce à aux navigateurs.
De quels navigateurs web s’agit-il ? Je ne saurais le dire, mais ce qui est évident est que Chrome qui est le navigateur de la compagnie en fait certainement partie.
Google va plus loin dans ses explications :
« Par exemple, le navigateur Web ou l’assistant de navigateur peut enregistrer des données concernant les documents auxquels l’utilisateur accède et les liens dans les documents (le cas échéant) sélectionnés par l’utilisateur. De plus, ou alternativement, le navigateur Web ou l’assistant de navigateur peut enregistrer des données concernant la langue de l’utilisateur, qui peuvent être déterminées de plusieurs façons qui sont connues dans l’art, comme l’analyse des documents auxquels l’utilisateur a accès. En outre, ou alternativement, le navigateur Web ou l’assistant de navigateur peut enregistrer des données concernant les intérêts de l’utilisateur. Cela peut être déterminé, par exemple, à partir des favoris ou de la liste de signets de l’utilisateur, des sujets associés aux documents auxquels l’utilisateur accède, ou d’autres façons qui sont connues dans l’art. De plus, ou alternativement, le navigateur Web ou l’assistant de navigateur peut enregistrer des données concernant les termes de requête saisis par l’utilisateur. Le navigateur Web ou l’assistant de navigateur peut envoyer ces données pour stockage dans le référentiel. »
Les navigateurs sont une alternatives pour les moteurs de recherche de collecter les informations des utilisateurs.
A cette étape, il n’y a plus de doute sur le fait que Google est en mesure d’utiliser l’UX pour influencer le classement des sites web dans les moteurs de recherche.
Voyons maintenant dans quelle mesure les signaux issus des comportements des utilisateurs peuvent être utilisés.
3.2. Comment Google utilise les signaux de l’UX dans ses classements ?
3.2.1. Google utilise les signaux de l’UX de façon indirecte
Eric Enge et Gary Illyes de Google ont eu à discuter sur le sujet lors de la SMX Advanced de 2016.
Mais d’abord, qui est Eric Enge ?
Eric Enge est un expert SEO de haut niveau qui a eu à publier le Livre « The Art of SEO », considéré comme l’une des bibles du SEO anglophone.
Il a obtenu plusieurs prix et distinctions que vous trouverez sur sa page LinkedIn :
Il est évident qu’il s’agit d’une source qu’il est possible de considérer comme étant fiable sur les questions liées aux moteurs de recherche.
Voici en vidéo, l’entretien que Gary Illyes de Google et Eric Enge à Pubcon :
En effet, les deux experts ont eu à discuter de comment Google peut considérer les signaux des utilisateurs comme des facteurs de classement.
Eric indique que le même sujet a fait l’objet d’une discussion entre lui et Paul Haahr de Google lors du SMX West en 2016 :
Dans son article, Eric affirme que selon ce dernier :
« Google utilise ces signaux comme facteur de positionnement indirect ».
Le concept peut être représenté de cette façon :
Pour reprendre les propos d’Eric :
« Avec le temps, ce type de boucle de rétroaction fera en sorte que les pages qui obtiennent le taux d’engagement le plus élevé (y compris le CTR le plus élevé) monteront dans les résultats de recherche. La subtilité de ce qu’a dit Haahr est que Google ne mesure évidemment pas directement les signaux d’engagement. Au lieu de cela, ils accordent leur utilisation d’autres signaux de sorte que les pages avec un engagement plus élevé soient déplacées vers le haut du classement. »
Est-ce que l’UX peut avoir un effet sur le classement ?
Même si c’est de façon indirect, cela se confirme une fois de plus avec les employés de Google.
Mais n’arrêtons-nous pas à ces affirmations et considérons les apports de Gary Illyes.
Remarque : Dans le souci de garder intact l’idée que le googler essaie de véhiculer, je vais me contenter de traduire les propos reportées par Eric :
« De nombreuses parties ont contesté cette affirmation de Google et, pour cette raison, j’ai demandé à Gary ce qu’il en pensait.
Voici ce qu’il a partagé :
Les signaux utilisateurs, comme les CTR, ont tendance à être très bruyants sur le web, et Google ne les trouve pas fiables.
Dans un environnement contrôlé, ils fonctionnent assez bien, et Google les utilise de cette manière. (Pour le reste de ce point, j’extrapolerais un peu à partir des commentaires de Gary). Pour ce faire, ils effectuent des tests d’échantillonnage pour évaluer la qualité de la recherche (Gary a suggéré qu’ils pourraient échantillonner 1 % des utilisateurs). Sur la base des résultats de ces tests, ils évaluent la qualité de leurs algorithmes de base. Selon les résultats, Google peut ajuster ses facteurs et réévaluer la situation.
L’exécution de ce type de processus continu de QC/QA entraînera en effet une montée des postes ayant un CTR élevé dans l’ensemble des SERP.
Le principal problème que pose l’utilisation de signaux d’engagement comme le CTR comme facteur direct est que la nature sporadique du CTR causerait probablement des mouvements sauvages dans les SERP à certains moments, et ce n’est pas nécessairement souhaitable (encore une fois, j’ai un peu extrapolé).
Dans un environnement de test contrôlé, Google peut reconnaître les mauvais ensembles de données et simplement les éliminer, leur donnant ainsi un bien meilleur contrôle sur le résultat.
Le CTR est l’une des choses examinées de cette manière, mais il y a aussi d’autres facteurs. »
Est-ce que le taux de clics ou CTR affecte le classement des pages ? Il est clair que Oui ! Mais pas de façon directe comme le pense beaucoup d’experts SEO.
De plus, il semble que les signaux de l’UX n’ont pas toujours les mêmes poids.
3.2.2. Les signaux de l’UX sont utilisés à des degrés différents
Les données sur le comportement des utilisateurs sont utilisées à des degrés différents selon les indicateurs.
Dans son brevet publié en 2015 sur les « Méthodes et systèmes pour améliorer un classement de recherche utilisant des informations sur les articles », Google écrit :
« Le processeur de classement détermine un score de classement basé au moins en partie sur les données de comportement côté client, extraites du processeur de données de comportement client, associées au nième article. Ceci peut être accompli, par exemple, par un algorithme de classement qui pondère les diverses données sur le comportement du client et d’autres facteurs de classement associés au signal de requête pour produire un score de classement. Les différents types de données sur le comportement des clients peuvent avoir différents poids, et ces poids peuvent être différents pour différentes applications. En plus des données de comportement du client, le processeur de classement peut utiliser des méthodes conventionnelles pour classer les articles selon les termes contenus dans les articles. Il peut en outre utiliser les informations obtenues à partir d’un serveur sur un réseau (par exemple, dans le cas de pages Web). Le processeur de classement peut demander une valeur PageRank pour la page Web d’un serveur et utiliser cette valeur pour calculer le score de classement. Le classement peut également dépendre du type d’article. Le classement peut également dépendre de l’heure, comme l’heure de la journée ou le jour de la semaine. Par exemple, un utilisateur peut typiquement travailler et s’intéresser à certains types d’articles pendant la journée, et s’intéresser à différents types d’articles pendant la soirée ou le week-end. ».
Bien qu’il ait des termes techniques, il est facile de comprendre que Google ne donne pas le même poids aux signaux des utilisateurs pour toutes les requêtes.
Selon les requêtes, certains signaux de l’UX peuvent avoir plus d’impact sur le classement que d’autres.
Nous savons désormais que Google utilise les signaux des utilisateurs pour effectuer ses classements. Même si c’est de manière indirecte, l’UX a un impact sur le classement.
Pour clore ce sujet, je vous propose de considérer quelques études d’industrie.
3.3. Les études d’industrie montrant des corrélations entre les métrics de l’UX et la position dans les SERPs
3.3.1. Les études de WordStream
WordStream est une compagnie de publicité en ligne fondée par Larry Kim :
Larry entretien une bonne réputation dans le digital marketing et dispose de 17 prix et distinctions :
Est-il une source fiable ? Je peux dire que oui !
Larry a mené quelques études en 2016, donc bien après le lancement de RankBrain, afin de déterminer s’il y une corrélation entre certains signaux de l’expérience utilisateur et la position des sites web dans les moteurs de recherche.
Vous pouvez retrouver son article sur Moz et comme lui-même le souligne, il ne faut pas graver dans le marbre les chiffres issus de ces études. Rappelez-vous que Google peut varier le poids des signaux en fonction des requêtes.
Ici, Larry indique :
« Nous n’examinons que les chiffres pour une verticale en particulier. L’engagement minimal prévu variera selon l’industrie et le type d’interrogation. ».
Cela dit, il s’agit d’une étude excellente !
Facteur 1 : Le taux de clic ou CTR est corrélé avec la position dans les SERPs
Gary a reconnu que le CTR peut influencer de façon indirecte le classement dans les SERPs.
Pour clarifier les choses, Larry a mené une étude basée sur 1 000 mots-clés qui lui permis d’avoir un tel graphique :
Il y a une forte corrélation entre le taux de clic et la position dans les SERPs. La corrélation est néanmoins différente selon le type de mot-clé court ou longue traîne.
Le même constat a été fait par Rand Fishkin de Moz qui a conduit une simple étude. Il a demandé à des gens d’effectuer une recherche particulière et de cliquer sur le lien de son blog qui occupait la 7eme position :
Source : Sparktoro
En l’espace de quelques heures, sa page web s’est retrouvée à la première position des SERPs :
Source : Sparktoro
A cette étape, il serait encore difficile d’avoir des incertitudes sur l’influence du taux de clic sur le classement dans les SERPs.
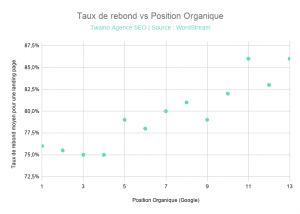
Facteur 2. : Le Bounce Rate a un impact sur la position organique
Le bounce rate ou taux de rebond design quand quelqu’un visite une page et appuie sur son bouton retour sans cliquer sur quoi que ce soit sur la page.
Officiellement, Google n’admet pas utiliser le taux de rebond ou les informations de Google Analytics pour effectuer ses classement.
@dnespo we don't use analytics/bounce rate in search ranking
— Gary 鯨理/경리 Illyes (so official, trust me) (@methode) May 13, 2015
Après son étude, Larry a constaté qu’il y a une corrélation entre le taux de rebond et la position organique :
Pour la requête qui a fait l’objet de son étude, avoir un taux de rebond de 76% accorde plus de chance d’apparaître dans les premières positions. En dépassant les 78%, votre site web risque d’avoir une moins bonne place.
Larry n’affirme pas que le bounce rate est un facteur de classement direct.
Il fait plutôt savoir :
« Mais je pense qu’il y a certainement un lien entre le taux de rebond et le classement. En regardant ce graphique, j’ai l’impression que ce n’est pas un accident, mais qu’il s’agit en fait d’un algorithme. »
En 2016 également, Brian Dean a effectué une étude sur 1 million de résultats Google et a constaté presque la même corrélation :
Il est important de rappeler qu’un bas taux de rebond n’est pas forcément synonyme d’un meilleur classement puisqu’il dépend de la niche du site web.
Mais de façon générale, un taux de rebond élevé sera un mauvais signe pour des sites tels que les e-commerces. Par contre, il le sera moins pour un site web qui donne juste des informations comme Wikipédia.
Cela étant, les conclusions que nous avons tirées jusque-là tiennent toujours la route, n’est-ce pas ?
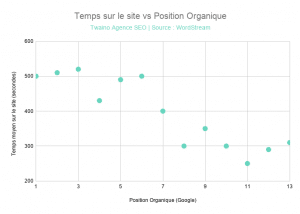
Facteur 3 : Le temps passé sur un site web peut affecter son classement
D’après l’étude de Larry King, le temps passé sur un site web présente une corrélation évidente avec la position dans les SERPs :
D’après ce graphique, si les visiteurs passent environ 500 secondes sur votre site web, vous avez des chances de faire partir des 6 premières positions.
Cela ne veut pas dire qu’il faut essayer d’atteindre coûte que coûte les 500 secondes. L’idée est de vous montrer qu’une amélioration constante de ce paramètre, aura un effet positif sur vos classements.
Et pourquoi ne pas dépasser les 500 secondes ou 8 minutes !?
Facteur 4 : Le dwell time et son impact sur la position dans les SERPs
Le dwell time est le temps qu’un chercheur Google passe sur une page des résultats de recherche avant de revenir aux SERPs.
Bien qu’il n’y pas une façon précise de déterminer le dwell time, il est possible de l’évaluer avec les facteurs que je viens de citer.
Larry estime que :
« Google utilise le dwell time – que nous ne pouvons pas mesurer, mais qui est proportionnel à l’engagement des utilisateurs comme le taux de rebond, le temps passé sur le site et les taux de conversion – pour valider les taux de clics. Ces mesures aident Google à déterminer si les utilisateurs ont finalement obtenu ce qu’ils cherchaient. »
Prenons un exemple pour illustrer ce paramètre.
Imaginez que vous utilisez la requête : « comment créer des backlinks ».
Google vous affiche certains résultats :
Le premier résultat semble bien adapté et vous cliquez dessus. Mais lorsque vous y arrivez, le site est :
Mal designer ;
Difficile à utiliser ;
Présente un contenu peu utile.
Pour cette raison, vous quittez le site après 10 secondes !
Votre dwell time est donc de 10 secondes et cette visite super brève indique à Google que vous n’étiez pas satisfait du résultat qu’il vous a proposé.
Maintenant, disons que vous cliquez ensuite sur le deuxième résultat et cette fois ci :
Le contenu est très utile ;
Vous avez une grande facilité à utiliser le site web ;
Le design est bien élaboré.
En bref, vous avez un contenu excellent :
Vous avez donc passé cette fois ci plus de 10 minutes sur le site web à prendre connaissance du contenu et vous retournez ensuite dans les SERPs.
Ce long dwell time, permet à Google de savoir que vous avez acquis une certaine valeur ajoutée grâce à ce site web.
Considérez maintenant que beaucoup d’utilisateurs, comme vous, passent un long moment sur la deuxième page web.
Le moteur de recherche aura tendance à booster le rang de cette page pour cette requête, n’est-ce pas ?
Est-ce que c’est comme cela que Google fonctionne réellement ?
« De plus, l’utilisateur peut sélectionner un premier lien dans une liste de résultats de recherche, se rendre sur une première page Web associée au premier lien, puis revenir rapidement à la liste des résultats de recherche et sélectionner un deuxième lien. La présente invention peut détecter ce comportement et déterminer que la première page Web n’est pas pertinente à ce que l’utilisateur veut. La première page Web peut être sous-classée, ou alternativement, une deuxième page Web associée au deuxième lien, que l’utilisateur a visualisé pour de plus longues périodes ou temps, peut être sur-classée. »
Un autre point, notamment l’utilisation du dwell time vient également d’être clarifiée. Si vous vous demandez s’il y a un dwell time standard, sachez que le dwell time dépend de plusieurs facteurs, à savoir :
Votre niche ;
Le type de contenu ;
La requête de recherche que les gens utilisent pour trouver votre page ;
Tendances saisonnières ;
Etc…
Au lieu de vous soucier d’un nombre arbitraire, je vous recommande de vous concentrer sur l’amélioration de votre dwell time à l’échelle de votre site web.
3.3.2. L’étude de Semrush
En 2017, Semrush a effectué une étude sur les facteurs de classement grâce à 600 000+ mots-clés. Les résultats se résument avec cette infographie :
Pour les mots-clés ayant été utilisé pour cette requête, les signaux utilisateurs sont très importants pour le moteur de recherche.
Ici, il s’agit :
Du temps passé sur le site web ;
Du nombre de pages par session ;
Du taux de rebond.
En plus des informations provenant de Google et des différentes études, il n’y a plus la moindre incertitude : Le moteur de recherche prend en compte l’expérience de l’utilisateur dans ses classements.
Même si c’est de manière indirecte et à des degrés différents, Google tient compte de l’UX. Si l’UX est aussi important, où se placera le SEO dans ce schéma ?
3.3.3. Le SEO et l’UX : Deux outils puissantes pour optimiser un site web !
Google a considérablement changé au fil des années.
En effet, le géant des moteurs de recherche met constamment à jour ses algorithmes pour s’assurer que les utilisateurs obtiennent les meilleurs résultats possibles.
Comme moi, beaucoup d’experts estiment que chaque mise à jour effectuée par Google a été conçue pour fournir des résultats plus conviviaux et plus axés sur l’utilisateur.
Nous avons eu le temps de voir les changements que le moteur de recherche à apporter aux SERPs et qui ont montré l’importance qu’il accorde à l’UX.
Il s’agit entre autres :
Des featured snippets ;
De Google Suggest ;
Du knowledge Graph ;
De Google Maps ;
De RankBrain ;
Etc…
Toutes les actions de Google vont dans le sens du fait d’apporter à ses utilisateurs la meilleure expérience possible.
Normal qu’il prenne en compte les signaux de l’expérience utilisateur pour effectuer ses classements, n’est-ce pas ?
D’ailleurs, les principes de base que le moteur de recherche indique aux webmasters dans ses consignes sont les suivantes :
«
Concevez vos pages en pensant d’abord aux internautes et non aux moteurs de recherche.
Ne trompez pas les internautes.
Évitez les « astuces » destinées à améliorer le classement sur les moteurs de recherche. Pour savoir si votre site Web respecte nos consignes, posez-vous simplement la question suivante : « Cela me dérangerait-il d’expliquer au propriétaire d’un site Web concurrent ou à un employé de Google quelles sont les solutions que j’ai adoptées ? ». Vous pouvez également vous poser les questions suivantes : « Ces solutions sont-elles d’une aide quelconque pour les internautes ? », « Aurions-nous fait appel à ces techniques si les moteurs de recherche n’existaient pas ? »
Pensez aux éléments qui rendent votre site Web unique et attrayant, et qui lui confèrent de la valeur. Faites en sorte que votre site Web se distingue des sites concurrents dans votre secteur d’activité. »
On est d’accord, l’utilisateur est au centre des décisions que prend le moteur de recherche.
Est-ce à dire que l’UX est plus important que le SEO qui vise à utiliser des techniques pour améliorer le positionnement d’un site web dans les SERPs ? Evidemment que non !
L’UX et le SEO partagent le même objectif et sont complémentaires ! Et voilà, je l’ai dit ☺
En effet, l’UX peut s’intégrer parfaitement dans le SEO parce qu’ils partagent tous les deux des objectifs communs.
Source : Paldesk
Si vous avez suivi le référencement naturel au cours des dernières années, vous saurez qu’il s’est éloigné du simple classement pour des termes de recherche.
Maintenant, le SEO cherche à fournir aux chercheurs des informations qui répondent à leurs besoins.
C’est là que l’UX et le SEO commencent à interagir puisque tous deux veulent aider les utilisateurs à accomplir leurs tâches en leur fournissant des informations pertinentes.
Alors que le SEO va conduire une personne au contenu dont elle a besoin, l’UX va répondre à sa question une fois qu’il se retrouve sur la page Web.
Cela étant, quand est-il de RankBrain ? Utilise-t-il l’UX pour influencer le classement ?
Chapitre 4. Comment RankBrain évalue le succès des résultats qu’il propose ?
Pour répondre à cette question, voyons d’abord quel rapport existe entre RankBrain et les autres signaux de classement.
Cette approche est beaucoup plus intéressante, ne trouvez-vous pas ?
4.1. RankBrain a un impact sur le classement de Google
4.1.1. RankBrain est un facteur de classement
Commençons par établir les bases afin de mieux comprendre ce point très important.
Vous rappelez-vous ? Greg Corrado a indiqué dans l’article de Bloomberg :
« RankBrain est l’un des » centaines » de signaux qui entrent dans un algorithme qui détermine quels résultats apparaissent sur une page de recherche Google et où ils sont classés. En quelques mois, RankBrain est devenu le troisième signal le plus important contribuant au résultat d’une requête de recherche. »
S’il est le troisième signal le plus important, on pourrait penser qu’il influence directement le classement, ne trouvez-vous pas ? Mais est-ce vraiment le cas ?
4.1.2. RankBrain influence les résultats des SERPs !
Avec le mot « Rank (rang) » dans le nom, c’est certainement ce que cela implique☺.
Mais ne nous limitons pas seulement à cette remarque banale et qui n’a visiblement aucun poids en termes d’argument.
Grâce à la section précédente, vous avez peut-être déjà une idée sur la question. Mais considérons une réponse plus directe de Gary Illyes :
Lemme try one last time: Rankbrain lets us understand queries better. No affect on crawling nor indexing or replace anything in ranking
— Gary 鯨理/경리 Illyes (so official, trust me) (@methode) March 18, 2016
@randfish I meant any ranking component. It does change ranking, e.g we're better at getting relevant results for negative queries
— Gary 鯨理/경리 Illyes (so official, trust me) (@methode) March 18, 2016
La traduction en français donne ceci :
« Rand Fishkin : je ne suis pas sûr de ce que signifie « remplacer quelque chose dans le classement » ? Êtes-vous en train de dire que Rankbrain n’a « aucun impact direct » sur le classement ? Gary Illyes : Je voulais dire n’importe quel composant de classement change le classement, par exemple, nous sommes meilleurs pour obtenir des résultats pertinents pour les requêtes négatives. »
On peut également considérer cette réponse de Gary à Moty Malkov :
@MotyMalkov that's the whole point of a ranking change. Now you can actually rank for queries like [can I finish super mario WITHOUT help]
— Gary 鯨理/경리 Illyes (so official, trust me) (@methode) March 18, 2016
Traduction :
« Moty Malkov : Ne sont-ils pas classés différemment lorsque vous les comprenez mieux ?
Gary Illyes : C’est tout l’intérêt d’un changement de classement. Maintenant, vous pouvez vraiment classer pour des requêtes comme [puis-je finir super mario SANS aide] »
Conclusion : RankBrain permet à Google de mieux comprendre les requêtes et de mieux classer ses résultats.
Est-ce uniquement les 15% des requêtes inconnus qui sont touchées ? Il semblerait que non puisque Danny Sullivan a publié un article sur le sujet :
Danny indique :
« Google est typiquement flou sur la façon exacte dont il améliore la recherche (quelque chose à voir avec la longue traîne ? ) mais Dean dit que RankBrain est « impliqué dans chaque requête », et affecte le classement réel « probablement pas dans chaque requête mais dans beaucoup de requêtes ». »
Voilà une affirmation qui permet de comprendre mieux le champ d’action de RankBrain. L’IA impacte presque tous les classements du moteur de recherche. Mais de quelle façon procède-t-il ?
4.1.3. Comment RankBrain peut influencer le classement ?
RankBrain n’a aucun impact sur les autres composants de l’algorithme de Google. La prochaine section détaille mieux cette allégation.
A ce niveau, il faut comprendre que si les visiteurs reviennent dans les SERPs juste après avoir cliqué et visité votre page web, RankBrain estime que votre page n’a rien à avoir avec ce que ses utilisateurs veulent.
Il n’évalue pas votre page web en considérant que votre contenu est mauvais, mais il essaiera prochainement de proposer un autre contenu afin de satisfaire l’intention de l’utilisateur pour la requête.
Ainsi, votre page web pourrait avoir une moins bonne position pour cette requête.
Mais cela ne veut pas dire qu’il ne sera pas mis en avant pour une autre requête.
Il est important de noter que RankBrain n’évalue pas la qualité de votre page. Les autres algorithmes du moteur de recherche se chargent d’évaluer les autres facteurs de classement.
L’IA de Google essaie simplement de comprendre ce que l’utilisateur veut dire lorsqu’il effectue une requête donnée.
Par conséquent, si RankBrain décide que votre page n’est pas ce que quelqu’un cherche, cela ne signifie pas que votre contenu n’est pas bon.
Plutôt, RankBrain considère que votre contenu n’était pas le meilleur.
Cette conclusion a été confirmée par Gary Illyes dans la précédente conversations avec Rand Fishkin :
@randfish I meant any ranking component. It does change ranking, e.g we're better at getting relevant results for negative queries
— Gary 鯨理/경리 Illyes (so official, trust me) (@methode) March 18, 2016
Prenons un simple exemple pour illustrer.
Un utilisateur de Google effectue la requête « construction d’un abris de jardin » et Rankbrain positionne votre page web à la première position.
Si le visiteur arrive sur votre site web et ne trouve pas l’information qu’il recherche, il est susceptible de le quitter rapidement.
Même si suffisamment d’utilisateurs font la même chose, RankBrain ne va pas considérer que vous avez un mauvais contenu.
Il va estimer qu’il a fait une erreur en donnant un résultat qui ne répond pas à l’intention de ses utilisateurs.
Pour une prochaine fois avec la même requête, il va alors ajuster le classement des pages. L’IA de Google va continuer de procéder ainsi jusqu’à trouver la meilleure réponse pour cette requête spécifique.
Il devient légitime de chercher à savoir la façon dont RankBrain évalue le succès ou l’échec de ses propositions.
4.2. RankBrain exploite des données historiques pour évaluer la pertinence de ses résultats
En ce qui concerne les machines learning, Wikipédia indique :
« En pratique, certains systèmes peuvent poursuivre leur apprentissage une fois en production, pour peu qu’ils aient un moyen d’obtenir un retour sur la qualité des résultats produits. ».
Comment RankBrain obtient des retours sur la qualité des résultats qu’ils proposent ?
Eric Enge, l’expert SEO que j’ai déjà eu l’occasion de citer, a eu un entretien avec Gary Illyes lors de l’événement Pubcon Las Vegas en 2016 :
Sur son blog, Eric a publié un cet article qui résume la discussion qu’il a eu avec le googler.
En ce qui concerne RankBrain, Eric montre que Gary ne s’est pas seulement limité sur la fonction de RankBrain que Google ne cesse de répéter depuis le lancement :
« Se concentrer sur l’amélioration du traitement des requêtes à longue traîne et inconnues ».
Etant donné qu’on a déjà parcouru cet aspect, il ne serait pas judicieux d’y revenir.
Par contre, certains points sont très cruciaux à retenir pour cerner le fonctionnement de RankBrain.
A l’instar des autres concepts très importants, je vais essayez de rapporter fidèlement ses propos (à quelques détails près puisqu’il s’est exprimé en anglais☺) :
« 2. Gary a également indiqué que RankBrain prend ses décisions en fonction de l’évaluation des données historiques de performance pour les requêtes jugées très similaires par RankBrain (dans le langage d’apprentissage machine, cela est déterminé en voyant comment une requête donnée est donnée aux requêtes historiques dans un espace vectoriel à haute dimension). Google peut utiliser les performances historiques de ces autres requêtes pour ajuster les résultats du classement de la nouvelle requête à longue traîne au fur et à mesure de son arrivée.”
3. J’ai demandé à Gary de peser le pour et le contre des allégations selon lesquelles RankBrain pilote d’autres parties de leur algorithme, et il a réitéré que cela ne change pas ces algorithmes. Ainsi, les algorithmes liés aux liens – Penguin, Panda, et autres algos – sont complètement inchangés par RankBrain. ».
Qu’est-ce que cela signifie en réalité ?
Laissons toujours Eric apporter quelques éclaircissements lors de sa deuxième rencontre avec Gary Illyes lors de la SMX Advanced en 2017 (soit 1 an plus tard) :
« RankBrain exploite les performances historiques de requêtes essentiellement, ou presque, identiques, pour voir ce qui a fonctionné et ce qui n’a pas fonctionné, puis exploite ces informations pour ajuster et améliorer les résultats fournis pour la requête courante. Plus en détail, RankBrain compare la requête de l’utilisateur avec d’autres requêtes historiques de nature similaire. C’est là qu’intervient l’apprentissage machine, car ils l’utilisent pour identifier les requêtes historiques qui sont les plus similaires à celles auxquelles Google a déjà répondu. Dans le langage d’apprentissage machine, cela se fait dans un « espace vectoriel à haute dimension ». Ceci est ensuite utilisé pour voir comment ces requêtes historiques se sont exécutées. En examinant de multiples requêtes, Google peut déterminer quels types de résultats ont donné de bons résultats et ceux qui n’en ont pas donné. Ces informations sont ensuite utilisées pouraffiner les résultats obtenus à partir des algorithmes Google habituels pour la nouvelle requête et, dans certains cas, elles peuvent même modifier les algorithmes invoqués pour traiter la requête. ».
Ce que Gary Illyes semble affirmé et l’interprétation qu’en fait Eric Enge, un an plus tard, sont similaires.
Maintenant, il y a un point crucial qu’il faut noter que : « RankBrain exploite les performances historiques des requêtes ». Que signifie réellement l’expression « performances historiques des requêtes » dans le contexte de RankBrain ?
Cette interrogation à mener plusieurs experts SEO à penser que RankBrain utilise les signaux de l’UX pour prendre des décisions. D’ailleurs, nous avons déjà vu que Google considère ses utilisateurs comme les meilleurs juges pour évaluer la pertinence de ses résultats.
Il s’agit d’un point qui fait polémique dans la communauté SEO. Alors qu’il y a certains experts qui soutiennent que RankBrain semble tenir compte de l’UX, d’autres réfutent catégoriquement cette hypothèse.
Il s’agit d’une hypothèse puisque Google ne semble pas vouloir nettement clarifier cette question.
Quoi qu’il en soit, nous savons que Google tient compte des signaux de l’UX pour effectuer ses classements. RankBrain fait partie du système et pourrait interagir avec ce type de signaux.
En effet, Eric Enge qui a longtemps discuté de RankBrain avec Gary Illyes schématise son fonctionnement de cette façon :
A un moment, RankBrain peut bien interagir avec des données concernant le comportement des utilisateurs. D’autant plus qu’il permet également à Google de classer une partie des résultats en tenant compte des performances passées.
La seule information tangible que nous avons à ce sujet concerne Google Brain, l’équipe de Google qui a conçu RankBrain :
Seroundtable dévoile l’intervention d’un employé de Google lors de l’événement Think Auto Google à Toronto en 2017 :
« Ainsi, lorsque la recherche a été inventée, comme lorsque Google a été inventé il y a de nombreuses années, ils ont écrit des heuristiques qui avaient compris quelle était la relation entre une recherche et la meilleure page pour cette recherche. Et cette heuristique a plutôt bien fonctionné et continue de fonctionner assez bien. Mais Google intègre maintenant l’apprentissage automatique dans ce processus. Il faut donc former des modèles pour savoir quand quelqu’un clique sur une page et reste sur cette page, quand il y retourne ou quand il y retourne et essaie decomprendre exactement cette relation. La recherche s’améliore donc de plus en plus grâce aux progrès de l’apprentissage machine. »
Il n’est pas explicitement indiqué que RankBrain intègre un système propre à lui qui évalue le dwell time et ses implications. Il peut bien s’agir d’une autre machine learning qui est/sera pourvue de cette faculté.
Dans tous les cas, l’expérience utilisateur est au cœur du développement de Google et RankBrain interagit probablement avec de tels signaux pour proposer de meilleurs résultats.
Pour finir cette partie, voyons dans quelle mesure RankBrain pourrait prendre en compte l’UX.
4.3. Comment RankBrain pourrait prendre en compte l’UX ?
Dans cette section, nous allons considérer le scénario selon lequel RankBrain tient compte de la satisfaction des utilisateurs pour valider les résultats qu’il propose. J’avoue que cette hypothèse semble le plus probable pour moi.
RankBrain pourrait procéder de cette façon :
RankBrain vous montre un ensemble de résultats de recherche qu’il estime que vous allez aimer.
Si un nombre important d’utilisateur aiment une page en particulier dans les résultats, le moteur de recherche donnera un coup de pouce au classement à cette page.
Si le résultat n’est pas satisfaisant, Google remplacera cette page par une autre.
Et la prochaine fois que quelqu’un cherchera ce mot-clé ou un terme similaire, le moteur de recherche verra comment ladite page performe auprès des utilisateurs.
Nous venons de parcourir de long en large le fonctionnement de RankBrain. Voyons quelques exemples qui décrivent RankBrain à l’œuvre.
Chapitre 5. Quelques exemples sur la façon dont RankBrain pourrait améliorer les résultats de recherche
Afin de comprendre précisément comment RankBrain améliore les résultats de recherche de Google, nous allons utiliser certains exemples.
Certains viennent directement de Google, d’autres proviennent des interprétations faites par certains experts SEO.
Remarque : Noter qu’overthinkgroup à réaliser le plus gros du travail puisque son article sur RankBrain a permis d’avoir les six prochains exemples réunis.
Je vais tenter de transmettre fidèlement ces exemples dans la mesure où certains exemples sont quasiment impossibles à refaire de nos jours.
5.1. RankBrain devine ce que vous cherchez, même si vous ne savez pas quels mots utiliser
Il s’agit du premier exemple donné à propos du fonctionnement de Rankbrain et il est tiré de l’article de Bloomberg.
Pour expliquer cette faculté de RankBrain, Danny Sullivan qui travaille désormais chez Google à utiliser la même requête que celle utilisée par Greg :
« What’s the title of the consumer at the highest level of a food chain ».
En français :
« Quel est le titre du consommateur au plus haut niveau de la chaîne alimentaire ? »
Il s’agit du genre de requête que nous tapons généralement dans Google lorsque nous avons oublié un terme en particulier.
Voici le résultat pour cette requête en 2016 :
Source : SearchEngineLand
Il faut constater que Google a clairement du mal à fournir un résultat précis et pertinent à cette requête.
Le moteur de recherche a néanmoins compris l’intention de recherche et a donné quelques résultats qui pourraient permettre à l’utilisateur de trouver sa réponse.
Cela dit, le chercheur devra fouiller de lui-même les pages pour avoir les informations dont il a besoin.
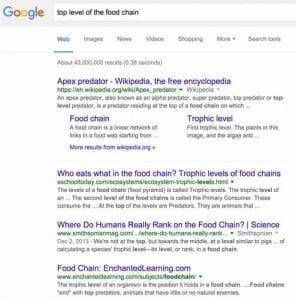
Le résultat n’est plus le même lorsqu’on recherche :
« Top level of the food chain » ou en français « plus haut niveau de la chaîne alimentaire » :
Cette requête est beaucoup plus précise et Google donne les éléments de réponse que l’utilisateur souhaite avoir.
La condition pour avoir un tel résultat était qu’il fallait entrer les bons termes pour avoir des réponses précises.
Selon Danny, RankBrain permet d’avoir le même résultat pour deux requêtes différentes s’il constate que l’intention de recherche reste le même.
En 2018, Danny a effectué la même requête :
« What’s the title of the consumer at the highest level of a food chain »
En français :
« Quel est le titre du consommateur au plus haut niveau de la chaîne alimentaire ? »
Le résultat est le suivant :
A ce niveau, on constate qu’il y a un featured snippet qui donne directement la réponse à la question posée.
De plus, il y a des questions relatives qui peuvent permettre d’avoir des éléments de réponses pour des questions connexes.
Il est possible de considérer RankBrain a compris au fil du temps que cette requête avait besoin d’une réponse très spécifique.
Il s’agit d’apex prédateur ou apex predator en anglais.
Par contre, le résultat est différent pour « top level of the food chain » :
RankBrain a suffisamment de données pour estimer que la deuxième requête devrait avoir un résultat différent de la première.
En effet, la deuxième requête vise à obtenir de l’information sur un niveau particulier de la chaîne alimentaire. Contrairement à la recherche plus longue qui vise à obtenir de l’information sur un consommateur particulier.
RankBrain essaie de comprendre des concepts et leurs nuances qui peuvent être très complexes à appréhender. C’est pour cette raison qu’il peut fournir des résultats précis même lorsque vous n’utilisez pas les mots et expressions exacts lors des recherches.
5.2. RankBrain arrive à déterminer quand les mots vides sont importants
Cet exemple a été donné par Gary Illyes à Danny Sullivan lors de la SMX Advanced conference.
La requête considérée à ce niveau est :
« Can I beat Mario Bros without using a walkthrough »
En français :
« Puis-je battre Mario Bros sans utiliser de procédure pas à pas ? »
Pour ce cerner cet exemple, il est important de noter que Google a l’habitude d’ignorer certains mots présents dans les requêtes.
Il s’agit des stops words ou mots vides en français.
Ranks donne une liste de mots vides qui sont souvent ignorés pas Google lorsqu’il traite les requêtes :
Revenons à notre exemple !
RankBrain est capable de déterminer lorsqu’un mot vide est important dans une requête.
A ce niveau, le mot « without » (« sans » en français) doit être considéré afin de ne pas altérer le sens de la phrase :
« Puis-je battre Mario Bros sans utiliser de procédure pas à pas ? »
Si le moteur de recherche ignore « sans », on se retrouve avec une autre requête et des résultats qui ne correspondent pas à l’intention de recherche.
A ce propos, Gary Illyes dit :
« Sans RankBrain, nous donnons des résultats intéressants qui ne répondent pas à mes besoins. Mais avec RankBrain, nous pouvons donner des résultats qui satisfont ma question. »
Si après avoir effectué cette recherche Google vous proposait des pages qui abordent uniquement la façon de battre Mario Bros avec un processus pas à pas, vous serez probablement frustré.
Toutefois, RankBrain est intelligent est en mesure de savoir que le mot « sans » est important.
Ainsi, il n affichera que les pages qui répondent à la question « est-ce que j’ai besoin d’un processus pas à pas pour battre Mario Bros ? ».
Les pages qui ne répondent pas précisément à cette question RankBrain va probablement les classer dans les postions inférieurs.
Cela ne signifie pas qu’ils sont de mauvaise qualité, ils ne répondent pas tout simplement à l’intention de recherche pour cette requête.
On peut conclure qu’il est important de parcourir tous les aspects concernant les sujets que vous avez à cœur de traiter.
5.3. RankBrain sait quand votre emplacement change et propose des résultats adéquats
Le troisième exemple est également issu de Danny Sullivan ☺ qui rapporte les propos de Google.
L’exemple concerne la requête :
« How many tablespoons in a cup ? »
Ou en français :
« Combien de cuillères à soupe dans une tasse ? »
Google fait savoir :
« RankBrain a favorisé des résultats différents en Australie par rapport aux États-Unis pour cette requête parce que les mesures dans chaque pays sont différentes, malgré des noms similaires »
En effet, les tasses et les cuillères à soupes sont plus grandes en Australie qu’aux Etats-Unis. Google doit tenir compte de votre position lorsqu’il affiche des résultats.
Toutefois, après avoir testé cet exemple, Danny Sullivan affirme qu’il n’a pas remarqué une réelle différence :
En effet, il a utilisé la même requête sur Google.com et Google Autralia.
Danny estime qu’il n’a pas trouvé une grande différence et que même sans RankBrain, les résultats étaient susceptibles de changer. Et ce, à cause de la tendance de Google à favoriser les pages de sites locaux les plus connus pour les utilisateurs locaux.
Mauvais exemple donné par Google ? Personnellement, il semblerait que oui.
Google essaie probablement d’expliquer de façon théorique le fonctionnement de RankBrain. Ou encore son utilisation des données de personnalisation.
Conclusion : RankBrain utilise la position pour interpréter ce que vous voulez vraiment dire par les mots que vous avez mis dans la barre de recherche.
5.4. RankBrain peut consolider des recherches similaires pour utiliser des données plus fiables
Une fois de plus, Danny Sullivan interprète le fonctionnement de RankBrain en se servant d’un exemple par rapport à la requête :
« Best flower shop in Los Angeles »
&
« Meilleur magasin de fleurs de Los Angeles »
Danny indique :
« Imaginez que RankBrain se lance à la recherche du « meilleur magasin de fleurs de Los Angeles (best flower shop in Los Angeles) ». Il pourrait comprendre qu’il s’agit d’une recherche similaire à une autre qui est peut-être plus populaire, comme « les meilleurs magasins de fleurs de LA (Best LA flower shops) ». Si c’est le cas, il pourrait alors simplement traduire la première recherche en coulisses dans la seconde. Il le ferait parce que pour une recherche plus populaire, Google a beaucoup plus de données d’utilisateur qui l’aident à se sentir plus confiant quant à la qualité des résultats. »
On peut comprendre que lorsque RankBrain est capable de déterminer si deux requêtes différentes ont la même intention de recherche.
Ainsi, il aura tendance à proposer les résultats de la requête la plus populaire pour des requêtes similaires.
Si les résultats d’une requête ont déjà été affichés plusieurs millions ou milliard de fois, il est tout à fait normal que les résultats de cette requête soient affichés pour une requête qui a la même intention de recherche et qui est moins populaire.
Mais comme l’affirme Danny :
« En fin de compte, RankBrain a changé le classement de ces résultats. Mais il l’a fait simplement parce qu’il a déclenché une recherche différente, pas parce qu’il a utilisé un facteur de classement spécial pour influencer l’ordre exact d’apparition de la liste. ».
RankBrain peut donc consolider des recherches similaires afin de fournir les meilleurs résultats.
5.5. RankBrain peut vous donner des résultats satisfaisants pour les intention de recherche subtiles
Cet exemple a été utilisé par Rand Fishkin de Moz dans son article sur : « Optimizing for RankBrain… Should We Do It? ».
Cette fois-ci la requête est :
« Best Netflix shows »
En français :
« Meilleures émissions Netflix ».
Comme nous l’avons vu, RankBrain a tendance à présenter des résultats similaires pour les requêtes ayant les mêmes intentions de recherche.
Il indique que RanKbrain aura tendance à faire la même chose pour ces cinq requêtes :
Best Netflix shows : Meilleures émissions Netflix ;
Best shows on Netflix : Meilleures émissions sur Netflix ;
What are good Netflix shows : Quelles sont les bonnes émissions Netflix ?
Good Netflix shows : Bonnes émissions Netflix ;
What to watch on Netflix : Que regarder sur Netflix.
Rand va plus loin et indique que pour ce type de recherche, le facteur « fraîcheur » du contenu est très important.
En effet, RankBrain va examiner toutes ces recherches et comprendre que : Vous cherchez ce qui se trouve sur Netflix en ce moment.
Ce qui est un élément qui n’est pas énoncé dans votre requête et qui est subtile.
Rand Fishkin affirme :
« Si vous n’êtes pas frais, vous ne montrez pas aux chercheurs ce qu’ils veulent, et Google ne veut donc pas vous afficher. En fait, le résultat numéro un pour tous ces films a été publié, je crois, il y a six ou sept jours, au moment du tournage de ce Whiteboard Friday. Pas particulièrement surprenant, n’est-ce pas ? La fraîcheur est très importante pour cette requête. »
Pour rappel, Google utilisait déjà la fraîcheur comme un facteur de classement avec Caffeine:
Avec RankBrain, Google est désormais meilleur puisqu’il est en mesure de déterminer lorsque ce facteur sera pris en compte ou pas pour une requête donnée.
Mettre à jour votre contenu est important comme j’ai eu l’occasion de le décrire dans mon article sur la technique de surenchère.
Mais il ne faut pas se lancer à corps perdu dans les mises à jour de tous vos contenus puisque Google n’accordera pas la même importance au facteur « fraîcheur » pour tous types de contenus.
Alors que le facteur fraîcheur sera capital pour les actualités sur les sorties du Président, il le sera moins pour une guide sur la création de backlinks.
5.6. RankBrain est vraiment bon pour comprendre les recherches compliquées
Le cinquième exemple a été donné par AL GOMEZ dans son article qui porte sur : « Creating content for Google’s RankBrain » (Créer du contenu pour Google RankBrain).
La principale requête utilisée est :
« Shape of conversion optimization in the future of digital marketing and beyond »
En français :
« Forme de l’optimisation de la conversion dans l’avenir du marketing numérique et au-delà »
Gomez a effectué plusieurs requêtes plutôt complexes qui se rapportent au même mot-clé : « conversion optimization (Optimisation de conversion) ».
Gomez a successivement effectué les requêtes suivantes dans Google :
Conversion optimization : Optimisation de conversion ;
Best conversion optimization tool : Meilleur outil d’optimisation de conversion ;
What is the top conversion optimization tool for marketers ? : Quel est le meilleur outil d’optimisation de conversion pour les spécialistes du marketing ?
Shape of conversion optimization in the future of digital marketing and beyond : Forme de l’optimisation de la conversion dans l’avenir du marketing numérique et au-delà.
Les résultats de Google sont les suivants :
En dépit de la complexité des requêtes, RankBrain ou Google a compris l’intention de recherche et a fourni les résultats adéquats.
Ce sont là quelques exemples de la façon dont RankBrain pourrait réellement changer les résultats que propose Google.
Maintenant, comment vous assurez-vous que RankBrain apprécie et classe votre page dans les meilleures positions ?
Chapitre 6. Comment optimiser vos contenus pour RanKbrain ?
La machine d’apprentissage automatique de Google est venue valider ce que les meilleurs référencements disaient depuis longtemps : Créer le meilleur contenu possible à votre audience.
Après son lancement en 2015, il faut attendre 2016 pour que Gary Illyes donne un élément de réponse quant à l’optimisation d’un contenu pour RankBrain :
« Optimiser pour RankBrain est en fait super facile, et c’est quelque chose que nous disons probablement depuis quinze ans maintenant, est – et la recommandation est – d’écrire en langage naturel. Essayez d’écrire un contenu qui sonne humain. Si vous essayez d’écrire comme une machine, alors RankBrain va juste devenir confus et vous repoussera probablement. Mais si vous avez un site de contenu, essayez de lire certains de vos articles ou ce que vous avez écrit, et demandez aux gens si cela semble naturel. Si ça sonne conversationnel, si ça sonne comme un langage naturel que nous utiliserions dans votre vie de tous les jours, alors bien sûr, vous êtes optimisé pour RankBrain. Si ce n’est pas le cas, alors vous êtes « non optimisé »
Je peux en déduire que la stratégie à adopter pour une optimisation pour RankBrain est de créer des contenus offrant une expérience utilisateur optimale.
Il est important de rappeler que RankBrain n’est pas un facteur de classement comme les autres. Nous n’avons pas un contrôle sur lui puisqu’il est une faculté de Google à mieux comprendre les requêtes de ses utilisateurs.
Prenons un simple exemple :
Les backlinks font partie des trois facteurs de classement les plus importants de Google. En obtenant des backlinks grâce à vos campagnes de netlinking, vous avez des chances d’améliorer votre classement dans les SERPs.
Vous pouvez mener des actions concrètes pour faire une optimisation pour ce facteur. Vous savez que si vous avez un nombre considérable de backlinks, vous pouvez être mieux classé.
Ce qui n’est pas le cas avec RankBrain qui essaie de comprendre les requêtes afin de proposer de meilleurs résultats. Est-il impossible d’optimiser les contenus pour RankBrain ? Non, vous pouvez optimiser vos contenus pour que l’IA de Google positionne mieux vos pages web.
6.1. Comment effectuer la recherche de mots-clés dans l’univers de l’IA ?
Avec RankBrain, Google est en mesure de mieux comprendre l’intention de recherche cachée derrière les requêtes de ses utilisateurs.
Est-ce à dire qu’il faut passer l’étape de rechercher les mots-clés ?
Non, il ne s’agit pas d’ignorer cette étape qui est d’ailleurs cruciale pour déterminer l’intention de recherche de votre audience. Dans la mesure où vous aurez la possibilité de concevoir des contenus qui répondent à leurs besoins et qui semblent suffisamment pertinents pour que RankBrain les positionnent dans ses meilleurs résultats.
A ce niveau, il s’agira de choisir les bons mots-clés et de les utiliser de la bonne façon.
6.1.1. Evitez d’optimiser différentes pages avec des mots-clés similaires
Il y a encore quelques années, il était pertinent d’optimiser différentes pages avec des mots-clés sensiblement différents.
Par exemple, supposons que vous optimisez deux différentes pages avec ces mots-clés légèrement différents :
« comment bâtir un abri de jardin »
« comment construire un bâtiment de jardin »
Le Google d’avant vous permet de vous positionner sur ces deux différents mots-clés :
Source : Backlinko
Avec RankBrain, Google arrive à savoir que l’intention de recherche est la même et donnera des résultats similaires.
Pour mon exemple, j’ai eu quasiment les mêmes résultats.
« comment bâtir un abri de jardin »
« comment construire un bâtiment de jardin »
Généralement, ce sont les mots-clés à longue traîne qui sont utilisés de cette façon. Autrement dit, ils ont parfois très peu de différence en termes de sens et d’intention de recherche.
Est-ce à dire qu’il ne faut plus les utiliser ?
Non, je n’essaie pas de dire qu’une catégorie de mots-clés est complètement obsolète. L’idée est simplement de vous assurer que vos pages sont optimisées avec des mots-clés nettement distincts et qui ont des intentions de recherche différentes.
Sans quoi, vous risquez la cannibalisation de mots-clés avec plusieurs pages qui se positionnent pour le même mot-clé ou des mots-clés similaires. Or, Google opte pour la diversité dans ses résultats de recherche et n’affiche pas dans ses résultats plus de deux pages web par site.
Alors, que faire concrètement ?
6.1.2. Optimisez vos pages avec des mots-clés de taille moyenne
Le fonctionnement de RankBrain pourrait impacter négativement les mots-clés de longue traîne de différentes façons.
Il ne fait pas de doute que les mots-clés à longue traîne sont les plus nombreux et sont beaucoup plus précis que les autres types de mots-clés :
En effet, RankBrain est en mesure de déterminer si deux requêtes sont similaires même si elles sont composées de mots différents. Pour cette raison, il pourrait afficher le même résultat pour « Comment construire un abris de jardin soi-même » et « construire un abris de jardin ».
Et c’est bien le cas pour cet exemple :
« Comment construire un abri de jardin soi-même »
« construire un abri de jardin » :
Une autre raison est le fait que RankBrain propose les résultats des mots clés les plus populaires pour des mots clés similaires.
Prenons mon exemple, « construire un abri de jardin » a plus de chance d’avoir un volume de recherche plus important que « Comment construire un abris de jardin soi-même ».
La première requête est populaire et RankBrain a déjà proposé plus fois des résultats qui ont satisfait ses utilisateurs. Il sera confident de proposer presque les mêmes résultats lorsqu’il traite des requêtes similaires.
C’est pour ces deux raisons qu’il est judicieux d’opter pour les mots-clés de taille moyenne.
Lorsque vous optimisez votre page autour d’un mot-clé à queue moyenne, la machine d’apprentissage automatique de Google vous classera automatiquement pour ce terme et pour des mots-clés similaires.
Vous avez certainement constaté que vos contenus ne se positionnent pas uniquement pour les mots-clés principaux pour lesquels vous les avez optimisés. Ils se classent sur des mots-clés connexes ou similaires.
Pour cela, vous pouvez opter pour les mots-clés LSI et la cooccurrence.
6.1.3. Utilisez les mots-clés LSI et la cooccurrence
La cooccurrence est la fréquence à laquelle les termes connexes apparaissent sur votre page.
En utilisant des termes faisant partie du même champ sémantique que votre mot-clé principal, RankBrain aura plus de précision sur la thématique que traite principalement votre article.
Lorsqu’il pense que quelqu’un cherche une information ayant rapport avec la thématique, il sait que votre contenu répondra à ses intentions.
Les mots-clés LSI ou Latent Semantic Indexing jouent également ce rôle en aidant RankBrain à voir la pertinence de votre contenu pour une requête donnée.
Les mots-clés LSI sont des mots et des phrases en rapport avec le sujet principal de votre contenu. Ils donnent également à RankBrain le contexte dont il a besoin pour bien comprendre votre page.
Supposons que vous écrivez un guide sur la « construction d’un abri de jardin ». Vous pourriez utiliser des mots-clés LSI tels que :
Abris de jardin monopente ;
Abris de jardin en bois ;
Coût de construction ;
Permis de construire abri de jardin ;
Outils et matériaux de constructions ;
Etc…
Quand RankBrain voit que votre contenu contient ces termes, il est confiant que votre page traite réellement de la construction d’abri de jardin ».
6.1.4. Ce qu’il faut éviter en utilisant les mots-clés
Mais il faut faire très attention pour ne pas tomber dans le Keyword Stuffing ou accumulation de mots-clés.
Rappelez-vous, on essaie de faire des optimisations pour offrir aux utilisateurs la meilleure expérience possible. Vos textes doivent être claire et « sonner comme unlangage naturel que nous utiliserions dans votre vie de tous les jours »
Gary Illyes montre :
« C’est un nouveau signal. Mais la raison pour laquelle j’ai demandé à propos de l’optimisation pour RankBrain, c’est parce que vous ne le faites pas. Il s’agit de s’assurer que l’utilisateur obtient le résultat qu’il mérite pour sa requête. Si vous écrivez en langage naturel, vous êtes prêt. Si vous remplissez votre contenu avec des mots-clés, cela ne sera certainement pas bon pour vous. »
Nous venons de faire le tour du sujet en ce qui concerne la recherche de mots-clés. Voyons comment vous pouvez optimiser vos pages pour une expérience utilisateur optimale.
6.2. Optimisez votre page pour les signaux UX
RankBrain examine les signaux de l’expérience utilisateur pour évaluer la pertinence des résultats qu’il propose.
Pour cela, vous devriez également utiliser les signaux UX pour déterminer si vous avez fait du bon travail ou pas.
Les principaux facteurs auxquels vous devez prêter attention sont :
Le CTR ou taux de clics dans les SERPs ;
Le taux de rebond sur votre page ;
Le dwell time.
6.2.1. Optimisez votre taux de clics dans les SERPs
Comme nous l’avons vu, le CTR organique est un signal clé du classement de Google. Rankbrain l’utilise probablement pour mieux classer les résultats qu’il propose.
Même le meilleur contenu au monde ne réalisera pas de bonnes performances dans les SERPs s’il n’incite pas des clics. Il ne fait pas de doute qu’avoir des clics est crucial puisqu’ils vous permettent d’avoir des visiteurs qui accompliront ensuite certaines actions sur votre site web.
En supposant que RankBrain inclut votre page dans les bons SERPs, vous devez faire en sorte qu’elle soit plus attrayante que la concurrence.
Pour faire cliquer les internautes sur votre résultat ou page, il y a trois principaux facteurs à considérer :
Le titre de votre page ;
La description de la page ;
Faire du branding.
Facteur 1 : Donnez des titres captivants à vos contenus
Le titre est l’élément principal que les internautes vont considérer pour déterminer si vous avez l’information qu’ils recherchent. Il ne suffit plus de mettre le mot-clé principal de votre contenu dans le titre pour qu’il performe.
Un titre attrayant devrait montrer clairement que votre contenu est en mesure de satisfaire le besoin du chercheur.
Envie de creuser le sujet, je vous invite à consulter mon guide complet sur la création de titres percutants et accrocheurs qui vous permet même d’accéder à des formules prêtes à l’emploi.
Noter également que les titres qui suscitent de vives émotions chez les internautes réalisent de très belles performances en termes de clics et d’engagements.
En effet, une étude de CoScheduke a montré que plus un titre suscite de l’émotion, plus il est susceptible d’avoir de l’engagement. Notamment en termes de partages :
BuzzSumo et OkDork ont également effectué une étude dans le même sens qui montre que les contenus suscitant certains types d’émotions connaissent le plus d’engagement.
Gardez à l’esprit que le plus important est d’être suffisamment clair sur ce que vous apportez à l’internaute. Votre titre devrait immédiatement véhiculer le message suivant : « vous trouverez définitivement ce que vous recherchez ici ».
Une fois que vous avez trouvé le bon titre pour votre contenu, il ne reste que la balise de description.
Facteur 2 : Optimisez votre balise de description pour avoir plus de clics
En plus de titre, c’est l’occasion de montrer en quoi votre contenu est unique et peut satisfaire l’intention de recherche de l’internaute.
Touchez les concepts clés de votre contenu pour que les utilisateurs sachent que vous avez ce qu’ils recherchent.
« Il n’y a pas de limite à la longueur des meta descriptions, mais les extraits des résultats de recherche sont tronqués au besoin, généralement pour s’adapter à la largeur de l’appareil. »
Il est néanmoins judicieux de faire en sorte que votre description soit courte avec environ 155 caractères pour éviter que Google ne tronque votre texte. Il faut également être clair, précis et n’oubliez pas d’inclure votre mot-clé.
Comme vous pouvez déjà l’imaginer, il est important de faire en sorte que votre balise méta « sonne humain » et naturelle.
Vous trouverez beaucoup plus d’informations sur la balise meta description dans mon article sur le SEO.
Facteur 3 : Faire du branding et faire connaître votre marque
WordStream a réalisé une étude qui montre que :
« les chercheurs sont plus susceptibles de cliquer sur vous s’ils ont déjà entendu parler de vous auparavant »
En effet, lorsque les gens sont dans les SERPs, ils sont beaucoup plus susceptibles de suivre un lien vers une marque qu’ils connaissent déjà et à laquelle ils font confiance.
Il s’agit d’un très grand avantage que vous pouvez optimiser en faisant connaître votre marque.
Le branding fait partie de mes stratégies de marketing comme je l’explique dans mon article qui porte sur comment je suis passé de 0 à 1 000 visiteurs.
Comme vous pouvez le constater dans l’image suivante, la requête qui me permet d’avoir le plus de trafic est le nom de mon Agence SEO : Twaino.
Cela montre qu’un grand nombre de mes visiteurs tapent directement le nom de mon agence dans les SERPs pour accéder à mon site web. Je vais prochainement dédier un article complet sur le branding de marque.
Pour l’instant, gardez à l’esprit de fournir la meilleure expérience possible à vos visiteurs afin qu’ils aient une certaine confiance en votre marque.
Pour ce faire :
Créez des contenus de grande qualité ;
Envoyez de bons e-mails ;
Soyez présent sur les réseaux sociaux ;
Etc…
Avec ces trois facteurs, vous serez en mesure d’améliorer significativement votre taux de clic. Mais une fois que vous avez conduit les visiteurs sur votre site web, il faut pouvoir les maintenir et leur permettre de trouver l’information qu’ils recherchent.
6.2.2. Comment réduire votre taux de rebond ?
Quand un visiteur arrive sur votre page et part immédiatement, c’est un bon indicateur qu’il est tombé au mauvais endroit.
Si un nombre important de visiteurs quittent votre page web de cette façon, RankBrain peut considérer que votre page ne satisfait pas l’intention de recherche pour cette requête.
Ainsi, il va diminuer le classement de la page et proposer un autre contenu à la place.
Même en ayant un taux de clics élevé, il est important de considérer ces deux facteurs pour réduire le taux de rebond sur vos pages.
Facteur 1 : Augmentez la vitesse de chargement de votre site web
Google a explicitement affirmé :
« Accélérer les sites Web est important – pas seulement pour les propriétaires de sites, mais pour tous les utilisateurs d’Internet. Des sites plus rapides créent des utilisateurs heureux et nous avons vu dans nos études internes que lorsqu’un site répond lentement, les visiteurs y passent moins de temps. ».
La vitesse de chargement est un facteur de classement très important dans la mesure où il a une forte corrélation avec la position dans les SERPs.
De plus, 53% des utilisateurs quitteront une page qui prend plus de 3 secondes pour se charger :
Votre taux de rebond va inévitablement augmenter si des visiteurs quittent votre page web de cette façon.
Gardez à l’esprit que les sites web les mieux classés ont en moyenne 1,9s de chargement. Il serait judicieux d’essayer de s’approcher de ce chiffre et pourquoi pas, de faire mieux.
Si vous souhaitez connaître la vitesse de chargement de votre site web, Google PageSpeed Insights est un très bon outil.
Facteur 2 : Assurez-vous que votre site s’adapte bien au mobile
Avec l’arrivé du mobile-first indexing, il est devenu crucial d’avoir un site web qui s’adapte aux téléphones mobiles.
Google préconise le responsive design qui aide ses algorithmes à :
« attribuer avec précision des propriétés d’indexation à la page au lieu de devoir signaler l’existence d’une correspondance entre les pages mobiles et pour ordinateur. ».
Si votre site web n’est pas mobile-friendly, vous risquez d’être pénalisé dans les SERPs.
De plus, vous risquez de perdre une grande partie de votre audience :
Vous devez donc faire des efforts dans ces sens puisqu’un site web qui n’est pas responsive risque d’avoir un taux de rebond élevé.
Ces deux facteurs vous permettent de réduire considérablement votre taux de rebond, mais vous pouvez aller plus loin en optimisant votre dwell time.
6.2.3. Comment augmenter le dwell time de vos pages ?
Plus votre contenu garde les visiteurs sur votre page, mieux c’est !
Cela permet à RankBrain de savoir qu’il a proposé un bon résultat pour une requête donnée.
C’est pourquoi, il est important de faire rapidement une bonne impression.
Lorsque quelqu’un accède à votre page à partir de Google, supposez que vous n’aurez que quelques secondes pour les impressionner. La première chose qu’ils verront doit leur confirmer qu’ils sont venus au bon endroit.
Ce n’est pas parce qu’ils ont atterri sur votre page web qu’ils ont décidé que vous étiez le meilleur choix.
Voici quelques tactiques qui peuvent vous permettre d’augmenter le temps que passent les internautes sur votre site web.
Tactique 1 : Rédiger des contenus d’autorité
La première astuce est de rédiger des contenus d’autorité qui traitent en profondeur les sujets que vous traitez. Avoir de longs contenus vous permet d’augmenter significativement votre dwell time.
Bien que de courts contenus permettent de répondre directement aux interrogations des lecteurs, ils les laissent parfois sur leur soif d’information.
De nombreuses statistiques montrent l’efficacité des contenus d’autorité et je vous invite à lire mon article sur la technique de surenchère.
Supposons que vous voulez savoir « comment construire un abri de jardin ».
Vous avez eu un contenu de 500 mots qui vous décrit brièvement les démarches à suivre et les matériaux à utiliser, cela laisse encore plusieurs questions non résolues.
Vous retournez donc dans les SERPs (pogo-sticking) et vous tomber finalement sur un contenu de 10 000 mots qui explique en détaille tout le processus.
Vous avez non seulement toutes les informations que vous vouliez, vous découvrez également des aspects du sujet auxquels vous n’aviez pas penser. Vous prenez donc le temps de tout consulter et de revenir plus tard sur des points que vous n’aviez pas retenus.
Les longs contenus réalisent de très belles performances et voici le résultat sur 1 mois lorsque je fais un tri des pages ayant connues une durée élevée :
Cela n’aurait pas été possible si les contenus n’étaient pas longs et apportant une certaines valeurs ajoutée aux lecteurs.
Cependant, il ne s’agit pas de publier un bloc de texte.
Puisqu’il faut le reconnaître, lire un contenu de 10 000 mots est particulièrement difficile.
Pour cela, utilisez-les :
Sous-titres ;
Les visuels ;
De petits paragraphes ;
De l’espace pour offrir une bonne expérience de lecture ;
Etc…
Source : SEOPressor
Essayez d’offrir une expérience optimale pour vos lecteurs.
Tactique 2 : Placez votre contenu au-dessus du pli
Vous n’avez que quelques secondes pour montrer aux visiteurs qu’il est au bon endroit pour trouver l’information qu’il recherche.
L’une des meilleures façon de le faire est de placer votre contenu au-dessus du plis de telle sorte que le visiteur ne soit pas obligé de défiler la page avant de lire les premières phrases.
Au lieu d’avoir quelque chose de ce genre :
Source : Backlinko
Optez plutôt pour une présentation comme celle-ci :
De plus, essayez d’avoir une introduction courte puisqu’elles sont beaucoup plus efficaces.
Dans la mesure où quand quelqu’un cherche quelque chose dans Google, il a déjà des connaissances sur le sujet. Vous n’avez donc pas besoin d’une longue introduction.
L’introduction est l’endroit où 90% de vos lecteurs vont décider de continuer la lecture ou de quitter la page. Alors travaillez-la de telle sorte qu’elle incite les internautes à continuer la lecture.
Avec ces deux tactiques, vous devriez être en mesure de garder plus longtemps vos visiteurs sur vos pages web.
Et voilà, vous venez d’optimiser vos contenus pour que RankBrain les comprenne et les considères comme les meilleurs résultats pour les thématiques que vous traitez.
Conclusion : L’optimisation pour RankBrain est très simple
Google améliore continuellement son système et les conséquences se font souvent remarquer au niveau du classement des résultats qu’il propose. Il s’agit de l’une des raisons pour lesquelles il est peu probable de conserver une position donnée dans les SERPs.
Les spécialistes du SEO se doivent donc de connaître les tendances liés aux différents facteurs qui peuvent affecter le positionnement de leur site web.
C’est le cas de RankBrain qui continue de profiter d’un certain mystère quant à son fonctionnement et sa relation avec les autres facteurs de classement.
Dans cet article nous avons eu l’occasion de ces différents éléments qui peuvent se résumer ainsi :
RankBrain sert à traiter les demandes inconnues ou imprécises grâce à sa capacité d’apprentissage et de prédiction ;
L’AI de Google fait partie des trois signaux de classement les plus importants dans la mesure où il permet de servir de meilleurs résultats à une requête ;
RankBrain n’affecte pas les autres processus traditionnels de classement et de notation ;
RankBrain pourrait utiliser les signaux de l’expérience utilisateur pour juger de la pertinence de ses résultats ;
L’AI de Google n’affecte pas également le crawling ni l’indexation.
Quant à l’optimisation, il est important de garder à l’esprit que l’IA de Google n’évalue pas les pages. Les autres signaux s’en chargent et sont déjà des facteurs pour lesquels vous devriez optimiser votre site web.
Quant à RankBrain, il suffit de publier des contenus hautement qualitatifs pour votre audience. Sans oublier de cibler des mots-clés à moyenne traîne ayant un volume important.
Les moteurs de recherche vont toujours continuer de s’améliorer afin de fournir des réponses comme la façon dont nous tenons nos conversations. Il est important de rester dans cette tendance afin d’offrir aux utilisateurs l’expérience la plus optimale possible.
Que pensez-vous de l’utilisation des signaux de l’expérience utilisateur par RankBrain ?
N’hésitez pas à partager votre point de vue !
A bientôt !
Alexandre MAROTEL
Fondateur de l'agence SEO Twaino, Alexandre Marotel est passionné par le SEO et la génération de trafic sur internet. Il est l'auteur de nombreuses publications, et détient une chaîne Youtube qui a pour but d'aider les entrepreneurs à créer leurs sites web et à être mieux référencés dans Google.
Augmentez votre chiffre d'affaires grâce au SEO avec l'agence Twaino
Twaino utilise des cookies pour analyser le trafic du site, améliorer votre expérience et personnaliser le contenu. Vous pouvez accepter, refuser ou personnaliser vos préférences.
Fonctionnel
Toujours activé
Le stockage ou l'accès technique est strictement nécessaire pour permettre le bon fonctionnement d'un service explicitement demandé (panier, connexion, langue, etc.).
Préférences
Le stockage ou l'accès technique permet de retenir vos préférences (affichage, langue) afin de personnaliser votre expérience de navigation.
Statistiques
The technical storage or access that is used exclusively for statistical purposes.Cookies utilisés exclusivement à des fins statistiques anonymes. Sans informations supplémentaires fournies par votre fournisseur d'accès, ces données ne peuvent pas vous identifier personnellement.
Marketing
Cookies utilisés pour créer des profils utilisateurs afin d'envoyer des publicités, ou pour suivre l'utilisateur sur ce site ou plusieurs sites à des fins marketing similaires.