

Avouons-le ! Le moindre changement que les moteurs de recherche, notamment Google, apportent à leur système ne passe pas inaperçu auprès de la communauté SEO
En 2010, nous savions que Google a apporté plus de 500 changements à son algorithme :

Ce chiffre est largement dépassé puisqu’en 2018 seulement, la firme a modifié son algorithme 3 234 fois, soit plus de 6 fois.
Evidemment, la plupart de ces mises à jour sont mineures et leurs impacts sur les classements sont insignifiants. Nous n’avons donc pas à nous inquiéter ?
Mais certains changements, considérés comme étant majeurs, sont facilement remarquables à cause de leur effet sur les classements et le trafic des sites web :

Source : Google
C’est le cas de la dernière mise à jour la plus importante de Google : BERT.

Aux vues des effets des mises à jour majeurs, il est tout à fait légitime de chercher à connaître les implications de Google BERT.
Par conséquent et à l’instar de mon article sur RankBrain, je vais essayer de montrer :
- Ce qu’est Google BERT ;
- Le fonctionnement de BERT et le problème qu’il essaie de résoudre ;
- L’impact de BERT sur le référencement ;
- Les différentes stratégies à adopter pour optimiser votre site web.
Allons-y !
Chapitre 1. Qu’est-ce que Google BERT ?
1.1. BERT : Le modèle d’apprentissage automatique de Google
Quelques années après RankBrain, Google lance une autre mise à jour qu’il qualifie de très importante : BERT.
Ce changement fut dans un premier temps déployé sur le territoire des États-Unis en octobre 2019. Pour les autres pays et langues, notamment la France, il faudra attendre le 9 décembre 2019 :
Comme ce tweet tente de le signaler, BERT va aider l’algorithme du moteur de recherche à mieux comprendre les recherches, tant au niveau de la requête que du contenu.
Toutefois, il est important de noter que BERT n’est pas seulement un algorithme de Google comme on l’aurait imaginé.
En réalité, BERT est aussi un projet de recherche et un document universitaire à code source ouvert qui a été publié en octobre 2018 :

Google l’affirme également dans son blog :
« Nous avons ouvert une nouvelle technique de pré-formation à la NLP appelée Bidirectional Encoder Representations from Transformers, ou BERT. Avec cette version, n’importe qui dans le monde peut former son propre système de réponse aux questions de pointe (ou une variété d’autres modèles) en environ 30 minutes sur un seul TPU Cloud, ou en quelques heures en utilisant un seul GPU. »
Vous pouvez déjà constater que BERT désigne « Bidirectional Encoder Representation from Transformers ».
De plus, BERT est un modèle d’apprentissage automatique utilisé pour considérer le texte des deux côtés d’un mot.
Oups ! on dirait que ça devient un peu compliqué avec des notions / termes techniques.
Ne vous inquiétez pas, je vais essayer d’expliquer le plus simplement possible ces différents concepts.
Notez que BERT est un modèle d’apprentissage automatique et fait donc partie de l’IA ou l’intelligence artificielle.
Et tout comme RankBrain, BERT ne cesse d’évoluer grâce aux modèles et données qui lui sont soumis.

1.2. BERT : La nouvelle ère du Natural Language Processing
Actuellement, BERT est devenu important parce qu’il a considérablement accéléré la compréhension du langage naturel pour les programmes informatiques.
En effet, le fait que Google ait mis en open source BERT a permis à l’ensemble du domaine de la recherche sur le traitement du langage naturel d’améliorer la compréhension globale du langage naturel.
Cela a d’ailleurs incité beaucoup de grandes firmes d’IA de construire également des versions BERT.
Nous avons ainsi :
- RoBERTa de Facebook :

- Microsoft qui étend BERT avec MT-DNN (Multi-Task Deep Neural Network) :

- SuperGLUE Benchmark pour remplacer le GLUE Benchmark :

Par exemple, il y a une forme de BERT qui porte la dénomination de « Vanilla BERT ».
Cette dernière permet d’avoir une couche de départ préformée pour les modèles d’apprentissage automatique en langage naturel. Ce qui permet d’avoir une base solide pour que leur structure soit continuellement améliorée. D’autant plus que Vanilla BERT a été préformé sur la base de données du Wikipédia anglais.
C’est l’une des raisons pour lesquelles BERT est considéré comme la méthode qui sera utilisée pour optimiser la NLP pour les années à venir.
Pour Thang Luong, senior research scientist à Google Brain, BERT serait la nouvelle ère de la NLP et probablement la meilleure qui ait été créée jusqu’à présent :
De ce qui précède, il faut comprendre que BERT n’est pas exclusivement utilisé par Google. Si vous avez effectué beaucoup de recherche sur le sujet, vous avez probablement constaté que la plupart des mentions de BERT en ligne ne concernent PAS la mise à jour de Google BERT.
Vous aurez droit à de nombreux articles sur BERT (qui donnent parfois des maux de tête puisqu’étant trop techniques / scientifiques) rédigés par d’autres chercheurs. Et qui n’utilisent pas ce que nous pouvons considérer comme la mise à jour de l’algorithme de Google.
Nous savons maintenant ce qu’est BERT et nous allons parler de comment il fonctionne.
Chapitre 2 : Comment fonctionne Google BERT ?
Pour comprendre comment fonctionne Google, il faut d’abord appréhender le concept de NPL.
2.1. Qu’est-ce que le NLP de Google et comment fonctionne-t-il ?
La communication entre les humains et les ordinateurs dans un langage à consonance naturelle est rendue possible grâce au NLP.
Le sigle NLP désigne « Natural Language Processing » ou en français « Traitement du langage naturel ».
Il s’agit d’une technologie basée sur l’Intelligence Artificielle qui consiste en l’apprentissage automatique du langage naturel.

Cette technologie est également utilisée dans :
- Les traitements de texte tels que Microsoft Word Grammarly qui utilisent la NLP pour vérifier l’exactitude grammaticale du texte ;
- Les applications de traduction de langue telle que Google translate ;
- Les applications de réponse vocale interactive (IVR) utilisées dans les centres d’appel pour répondre aux demandes de certains utilisateurs ;
- Les assistants personnels tels que OK Google, Hay siri, Cortana, Alexa…
Le PNL est la structure qui permet à Google BERT de fonctionner et qui se compose de cinq principaux services pour effectuer les tâches de traitement du langage naturel.
2.1.1. L’analyse syntaxique
Au cours de cette analyse, le moteur de recherche décompose la requête en des mots individuels et extrait ensuite les informations linguistiques.
Par exemple, prenons la requête suivante : « Planter un arbre dans un jardin »
Dans cette requête, Google peut décomposer la décomposer de cette façon :
- Planter tag : Verbe à l’infinitif
- Un tag : Déterminant
- Arbre tag : Nom commun
- Dans tag : Préposition
- Un tag : Déterminant
- Jardin tag : Nom Commun
Comme c’est le cas avec le Stanford/Parser qui est un analyseur de langage naturel :

2.1.2. Analyse du sentiment
Le système d’analyse des sentiments de Google attribue un score émotionnel à la requête.
Le tableau suivant montre quelques exemples expliquant comment fonctionne le concept de l’analyse des sentiments effectuée par Google.
Par conséquent, notez que les valeurs ne viennent pas de Google ont été pris au hasard :

2.1.3. Analyse des entités
Ici, Google prend en compte les entités qui sont présentes dans les requêtes pour présenter les informations les concernant, le plus souvent avec le Knowledge Graph.
Si vous recherchez par exemple « taille de la tour Eiffel », le moteur de recherche va détecter « Eiffel » comme étant une entité.
De cette façon, il va envoyer les informations concernant cette requête :

Google peut classer les choses de cette façon pour cet exemple issus de Toptal :
« Robert DeNiro spoke to Martin Scorsese in Hollywood on Christmas Eve in December 2011. »

2.1.4. Analyse du sentiment de l’entité
À l’instar de l’analyse des sentiments, Google essaie d’identifier le sentiment global dans les documents contenant les entités.
De cette façon, le moteur de recherche donne une note à chacune des entités en fonction de la manière dont elles sont utilisées dans les documents.
Prenons toujours un autre exemple de Toptal :
« The author is a horrible writer. The reader is very intelligent on the other hand. »

2.1.5. Classification du texte
L’algorithme de Google sait précisément à quelle thématique appartiennent les pages web.
Lorsqu’un utilisateur effectue une requête, Google correspond analyse la phrase et sait exactement dans quelle catégorie de pages web fouillées.
Voici un autre exemple issu de la même source :
Ils ont analysé avec le Google NLP API cette phrase issue d’une annonce sur Nikon :
« The D3500’s large 24.2 MP DX-format sensor captures richly detailed photos and Full HD movies—even when you shoot in low light. Combined with the rendering power of your NIKKOR lens, you can start creating artistic portraits with smooth background blur. With ease. »
Traduit nous, avons :
« Le grand capteur DX de 24,2 MP du D3500 capture des photos très détaillées et des vidéos Full HD, même en cas de faible luminosité. Combiné à la puissance de rendu de votre objectif NIKKOR, vous pouvez commencer à créer des portraits artistiques avec un flou d’arrière-plan lisse. En toute simplicité. »
Le résultat de la classification est le suivant :

On peut constater que le test est classé dans la catégorie :
- Arts et divertissements/Art visuel et design/Arts photographiques et numériques avec 0,95 comme indice de confiance ;
- Passe-temps et loisirs avec 0,94 comme indice de confiance
- Ordinateurs et électronique / Électronique grand public / Appareils photo et caméras avec 0,85 comme indice de confiance.
Voilà les 5 piliers du Google NLP qui ont pour grand défi, le manque de données.
Selon les termes de Google :
« L’un des plus grands défis du traitement du langage naturel (NLP) est le manque de données sur la formation. Parce que la NLP est un domaine diversifié avec de nombreuses tâches distinctes, la plupart des ensembles de données spécifiques à une tâche ne contiennent que quelques milliers ou quelques centaines de milliers d’exemples de formation marqués par l’homme. »
Pour résoudre le problème de la pénurie de données sur la formation, Google est allé plus loin et a conçu le Google AutoML Natural Language qui permet aux utilisateurs de créer des modèles d’apprentissage machine personnalisés.
Le modèle BERT de Google est une extension de Google AutoML Natural Language. C’est pour cela que la communauté NLP peut également l’utiliser.
2.2. Quels sont les problèmes que BERT essaie de résoudre ?
Étant humains, nous arrivons facilement à comprendre certaines choses que les machines ou les programmes informatiques sont incapables d’appréhender.
BERT est venu corriger à sa manière ce problème et voici les principaux points qu’il traite :
2.2.1. Le nombre et l’ambiguïté des mots
De plus en plus de contenu est diffusé sur la toile et nous sommes littéralement submergés :

Leur nombre n’est pas un problème en soi pour les machines qui sont conçues pour traiter une quantité astronomique de données.
En effet, les mots sont problématiques parce que beaucoup d’entre eux sont :
- Ambigus et polysémiques : Un mot peut avoir plusieurs sens ;
- Des synonymes : Des mots différents veulent signifier la même chose.

Bert est conçu pour aider à résoudre les phrases ambiguës et les expressions qui sont composées de mots polysémiques.
Vous conviendrez avec moi qu’il y a une multitude de mots qui ont plusieurs significations.
Lorsque j’écris le mot « aimant », vous ne savez pas s’il s’agit du matériel utilisé pour attirer le fer ou s’il s’agit de la conjugaison du verbe « aimer ».
Cette ambiguïté se remarque pour la rédaction ou les textes écrits, mais cela devient beaucoup plus difficile lorsqu’il s’agit du parler.
En effet, même le ton peut faire en sorte qu’un mot ait un autre sens.
Lorsque je dis une insulte avec un ton amical à un proche, cela n’a absolument pas la même signification que lorsque je profère des insultes sur un ton colérique.
Le premier aura tendance à faire rire, mais le second risque de me faire passer un mauvais quart d’heure. ?
Nous les humains, nous avons cette faculté naturelle à comprendre aisément les mots qui sont employés.
Ce que les ordinateurs ne peuvent pas encore parfaitement faire. Ce qui fait ressortir un autre problème beaucoup plus important :
2.2.2. Le contexte des mots
Un mot n’a de sens précis que s’il est utilisé dans un contexte particulier.
En effet, la signification d’un mot change littéralement au fur et à mesure qu’une phrase se développe.
Je prends un exemple tout simple : « Nous avons tous fait le travail, c’est un fait. »
En tant qu’humains, nous avons la faculté de vite savoir que les deux mots « fait » sont différents.
Utilisons une fois de plus le programme NLP Stanford Parser :

Une analyse de ma phrase me donne ce résultat :

Le logiciel est arrivé à faire la différence entre le « fait » en tant que verbe au participe passé et le « fait » nom commun.
Sans le NLP, il aurait été difficile pour les programmes informatiques de faire une différence assez nette entre ces deux termes.
En effet, c’est le contexte et particulièrement les autres mots de la phrase qui permettent de comprendre la signification exacte des mots.
Par conséquent, la signification du mot « fait » change en fonction de la signification des mots qui l’entourent.
Évidemment, plus la phrase est longue, plus il est difficile de suivre tout le contexte de tous les mots dans la phrase.
Ainsi, avec l’augmentation du contenu généré sur la toile, les mots deviennent plus problématiques et plus difficiles à comprendre pour les moteurs de recherche. Sans oublier la recherche conversationnelle qui est beaucoup plus complexe que l’écrit.
Le grand problème que BERT résout ici est d’ajouter un contexte aux mots utilisés afin de les comprendre.
Le rôle essentiel que joue BERT est donc d’essayer de COMPRENDRE les mots utilisés.
Nous allons y revenir dans les prochaines sections de ce guide. Pour l’instant, concentrons-nous sur un autre aspect du NLP qui est la différence entre le NLU et le NLR.
2.3. La différence entre la Compréhension du Langage Naturel (NLU) et la Reconnaissance du Langage Naturel (NLR)
Le Natural Language Understanding / La compréhension du langage naturel est différente du Natural Language Recognition / Reconnaissance du Langage Naturel.
Les moteurs de recherche savent reconnaitre les mots que leurs utilisateurs utilisent. Mais cela ne signifie pas qu’ils arrivent à comprendre les mots selon leur contexte.

En effet, pour prendre conscience du langage naturel, il faut faire preuve de bon sens. C’est une chose plutôt facile pour les humains, mais qui est difficile pour les machines.
Par exemple, nous avons l’habitude en tant qu’humain d’examiner plusieurs facteurs afin de comprendre le contexte des mots et donc l’information qui est véhiculée.
Il s’agit par exemple :
- Des phrases précédentes ;
- La personne à qui nous parlons ;
- Du cadre dans lequel nous sommes ;
- Etc.
Cependant, une machine ne peut pas faire cela aussi facilement, même s’il peut reconnaître les mots du langage naturel.
Pour cela, nous pouvons statuer que le NLU, BERT, permet à Google d’avoir une meilleure compréhension des mots qu’il a déjà l’habitude de reconnaître.
Il en va de même pour les données structurées et les données du Knowledge Graph qui ont beaucoup de lacunes que vient combler le NLU.

On peut se demander à raison : Comment les moteurs de recherche peuvent-ils combler les lacunes entre les entités nommées ?
2.4. La désambiguïsation du langage naturel ou Natural Language Disambiguation
Tout ce qui est mis en correspondance avec le knowledge Graph n’est pas utilisé par les moteurs de recherche. C’est pour cela que la désambiguïsation en langage naturel est utilisée pour combler les lacunes entre les entités nommées.
Elle se base sur la notion de cooccurrence qui permet d’avoir un contexte et peut modifier le sens d’un mot.
Par exemple, vous allez vous attendre à voir une expression telle que « site référent » dans un article qui aborde les backlinks. Mais voir une expression telle que « crypto-monnaie » serait hors contexte.
C’est pourquoi les modèles linguistiques qui sont formés sur de très grandes collections de textes doivent être balisés par des ensembles de données. Ceci, en utilisant la similarité de distribution afin d’apprendre le poids et la mesure des mots et leur proximité.
Ici, BERT est utilisé pour effectuer les tâches de formation de ces modèles entraînés pour faire la liaison entre les concepts et les mots :

Grâce à ces modèles, les machines arrivent à construire des modèles d’espace vectoriel pour l’incorporation des mots :

2.5. Comment Google BERT fournit le contexte aux mots
Un seul mot n’a de signification sémantique que lorsqu’il est placé dans un contexte donné.
BERT est alors utilisé pour assurer la « cohésion du texte », c’est-à-dire maintenir une certaine cohérence dans le texte.
Lorsqu’on parle de cohésion, il n’y a qu’un seul facteur qui donne un sens à un texte : Le lien grammatical.
Une partie importante du contexte sémantique est le marquage part-of-speech / part-of-speech tagging (POS) :

Nous avons eu à l’évoquer dans la section sur le NLP ! Vous vous en rappelez, n’est-ce pas ?
Maintenant, donnons une réponse à la question suivante :
2.6. Comment fonctionne Google BERT ?
Les anciens modèles linguistiques tels Word2Vec que nous avons vus dans l’article de RankBrain n’intègrent pas les mots avec leur contexte :

C’est justement ce que BERT essaie de permettre aux moteurs de recherche de faire.
Nous allons voir comment il fonctionne et pour ce faire, nous allons décortiquer l’acronyme en lui-même de BERT : Bidirectional modelling Encoder Representations Transformers
2.6.1. Le B de BERT : Bidirectionnel
Les modèles linguistiques étaient auparavant unidirectionnels lorsqu’ils essayaient de comprendre le contexte des mots.
Autrement dit, ils ne pouvaient déplacer la fenêtre de contexte que dans une seule direction pour comprendre le contexte du mot :

Prenons cet exemple pour mieux comprendre : « j’ai déjà consommé le contenu qui est publié »
Les modèles linguistiques ne pouvaient lire la phrase que dans un sens pour essayer de comprendre le contexte. Ce qui veut dire qu’ils ne pourront pas utiliser les mots entourant « consommé » dans les deux sens, pour savoir que ce mot signifie à ce niveau consulter / prendre connaissance.
C’est pourquoi nous disons que la plupart des modélisateurs linguistiques sont unidirectionnels et ne peuvent parcourir les mots que dans une seule direction. Ce qui peut faire une grande différence dans la compréhension du contexte d’une phrase.
Par contre, BERT utilise la modélisation bidirectionnelle du langage et peut voir les deux côtés d’un mot cible pour le placer dans son contexte :

BERT est le premier à être doté de cette technologie qui lui permet de voir la phrase entière de chaque côté d’un mot afin d’obtenir le contexte complet :

Google le souligne dans ce document de recherche intitulé « BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding » :
« BERT est le premier modèle de représentation basé sur le réglage fin qui atteint des performances de pointe sur une vaste suite de tâches au niveau de la phrase et au niveau du token, surpassant de nombreuses architectures spécifiques à la tâche…. Il est conceptuellement simple et empiriquement puissant. Il obtient de nouveaux résultats de pointe sur onze tâches de traitement du langage naturel, notamment en portant le score GLUE à 80,5% (amélioration absolue de 7,7%), la précision MultiNLI à 86,7% (amélioration absolue de 4,6%), la réponse à la question SQuAD v1.1 au test F1 à 93,2 (amélioration absolue de 1,5 point) et le test F1 SQuAD v2.0 à 83,1. »
Nous venons de voir la signification du « B », nous allons continuer avec le :
2.6.2. L’ER de BERT : Encoder Representations
Encoder Representation ou Représentations d’Encodeur est essentiellement l’action d’introduire des phrases dans l’encodeur pour que des décodeurs, des modèles et des représentations en sortent, en fonction du contexte de chaque mot.

Je pense qu’il n’y a rien à ajouter, passons à la dernière lettre du sigle :
2.6.3. Le T de BERT : Transformers
Le BERT utilise des « transformateurs » et la « modélisation du langage masqué » ou le Masked Language Modelling.
En effet, un autre problème important qu’on rencontre dans le langage naturel était de comprendre à qui / quel contexte un mot en particulier se réfère.
Par exemple, il est parfois compliqué de suivre de qui parle-t-on lorsqu’on utilise les pronoms dans une conversation. Surtout lorsqu’il s’agit une très longue conversation !

Ce problème ne manque pas au niveau des programmes informatiques. Et c’est un peu la même chose pour les moteurs de recherche, ils ont du mal à suivre quand vous utilisez les pronoms :
- Il / ils ;
- Elle / Elles ;
- Nous ;
- Ça ;
- Etc.
C’est dans ce cadre que les transformateurs se concentrent par exemple sur les pronoms et la signification de tous les mots qui vont ensemble. Ce qui leur permet de relier les personnes à qui l’on parle ou ce dont on parle à un contexte donné.
Les transformateurs sont toutes les couches qui forment la base du modèle BERT. Elles permettent à BERT non seulement de regarder tous les mots d’une phrase, mais aussi de se concentrer sur chaque mot individuel et d’examiner le contexte à partir de tous les mots qui l’entourent.
BERT utilise des transformateurs et le « Masked Language Modelling », qui signifie que certains mots d’une phrase sont « masqués », obligeant BERT à deviner certains mots :

Les mots sont masqués de manière aléatoire et BERT est tenu de prédire le vocabulaire original des mots en se basant uniquement sur son contexte.
Cela fait également partie du processus de mise au point du modèle.
Chapitre 3 : Études de cas : Comment BERT améliore concrètement les SERP ?
Pour comprendre le fonctionnement de Google BERT, nous allons nous servir des exemples que Google a fournis dans son article sur BERT.
Exemple 1 : La signification du mot « quelqu’un »
La requête qui est considérée est la suivante :

Littéralement traduits, nous avons : “ Pouvez-vous obtenir des médicaments pour quelqu’un pharmacie ”
Bien que ce ne soit pas très précis, on peut comprendre que l’utilisateur cherche à déterminer si le proche d’un patient peut aller chercher une ordonnance en son nom.
Avant que BERT ne soit intégré dans son algorithme, Google donnait ce genre de réponse :

Traduits, nous avons la réponse suivante :
« Votre prestataire de soins de santé peut vous délivrer une ordonnance en … Rédiger une ordonnance sur papier que vous apportez dans une pharmacie locale … Certaines personnes et compagnies d’assurance choisissent d’utiliser … »
Cette réponse est clairement insatisfaisante puisqu’elle fait abstraction de ce « quelqu’un » qui n’est pas le malade.
Autrement dit, Google n’a pas pu traiter la signification du mot « quelqu’un » dans le contexte de la requête.
Après BERT, Google semble être en mesure de capter les subtilités dans les requêtes qu’il traite.
Voici la réponse que Google fournit désormais à une telle requête :
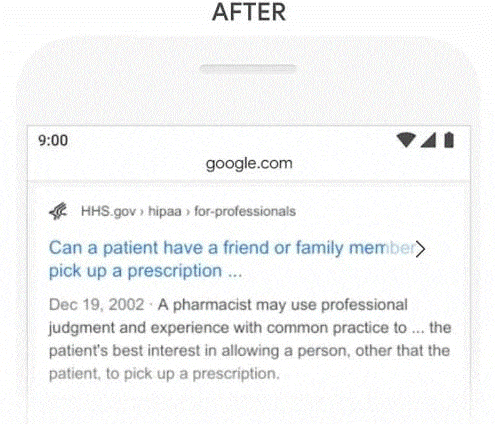
Traduit en français, nous avons :
« Un pharmacien peut faire appel à son jugement professionnel et à son expérience des pratiques courantes pour … dans le meilleur intérêt du patient en permettant à une personne, autre que le patient, de venir chercher une ordonnance. »
On peut convenir que cette réponse est explicite et répond sans ambiguïté à la requête du chercheur.
Autrement dit, Google a maintenant compris la signification sémantique du mot « quelqu’un », sans lequel la phrase prend un tout autre sens.
Alors, quel a été le rôle de BERT dans cette tâche ? On convient que BERT a aidé Google à comprendre la requête.
En effet, Google a su maintenant repérer les mots les plus importants de la requête grâce à leur contexte et accorder lors du traitement une certaine note d’importance.
Cette façon de procéder a permis à Google de fournir des résultats de recherche beaucoup plus précis.
Exemple 2 : Pris en compte du mot « stand »
La requête suivante :

Traduit, nous avons :
« Les esthéticiennes travaillent-elles beaucoup »
Avant BERT, Google donne cette réponse :

Traduit, nous avons :
« le type d’entreprise dans lequel travaille une esthéticienne peut avoir un impact sur ses revenus, … les écoles proposent des programmes d’esthétique, bien qu’il existe également des écoles d’esthétique indépendantes. »
La réponse n’a vraiment rien à avoir avec la requête de l’utilisateur.
En effet, Google n’a pas su bien interpréter le terme « stand » en le liant à l’expression « stand-alone » qui signifie « indépendant / autonome ».
C’est pour cette raison que Google a proposé un résultat qui évoque le travail indépendant des esthéticiennes.
Avec Bert, Google devient un peu plus intelligent et arrive à comprendre le contexte de la requête :

Traduit en français :
« Parler clairement pour que les auditeurs puissent comprendre. Tenez le bras et la main dans une position ou tenez la main droite tout en bougeant… »
Ici, Google énumère l’effort physique que les esthéticiennes sont amenées à effectuer dans le cadre de leur travail.
La réponse à la question « les esthéticiennes travaillent-elles beaucoup » trouve une meilleure réponse.
C’est exactement ce que Google indique :
« Auparavant, nos systèmes adoptaient une approche consistant à faire correspondre des mots clés, en faisant correspondre le terme « stand-alone » dans le résultat avec le mot « stand » dans la requête. Mais ce n’est pas la bonne utilisation du mot « stand » dans le contexte. Nos modèles BERT, en revanche, comprennent que le mot « stand » est lié au concept des exigences physiques d’un emploi et affiche une réponse plus utile. »
Exemple 3 : Le contexte du mot « adults »
Comme troisième exemple, nous avons cette requête :

Traduit en français, nous avons :
« Livre de pratique de mathématiques pour adultes »
Ici, on peut supposer que l’utilisateur à l’intention d’acheter des livres de mathématiques pour adultes.
La réponse que Google proposait avant BERT est la suivante :

Le constat est que Google renvoie des résultats suggérant des livres pour les enfants, notamment les classes de 6 à 8 ans.
Google a fourni cette réponse parce que la page contient l’expression « young adult ».
Mais dans notre contexte, faire seulement correspondre les mots ne fonctionne pas et évidemment, « jeune adulte » n’est pas pertinent pour la question.
Après BERT, Google est capable de discerner correctement la différence entre les deux expressions « Young Adults » et « adult ».
Ou il comprend le contexte dans lequel ces deux expressions sont employées et exclut les réponses hors contexte :

Traduit en français :
« Mathématique pour les adultes (grandes personnes) et des millions d’autres livres sont disponibles pour Amazon Kindle. … (Mathématiques de base pour adultes) Partie 1. »
Exemple 4 : Tenir compte du mot « sans »
Considérant un autre exemple ou Google ne tient pas compte d’une préposition très important :

Traduit en français :
« Stationnement sur une colline sans trottoir »
Voici la réponse que Google propose avant BERT :

Traduit, nous avons :
« Parking sur une colline. Montée : lorsque vous montez une colline, tournez les roues avant pour les éloigner du trottoir et laissez votre véhicule rouler lentement vers l’arrière jusqu’à ce que la partie arrière de la roue avant repose contre le trottoir en l’utilisant comme bloc. En descente : Lorsque vous arrêtez votre voiture dans une descente, tournez vos roues. »
On peut constater que Google a accordé beaucoup trop d’importance au mot « trottoir » en ignorant le mot « sans ».
Google ne comprenait probablement pas à quel point ce mot était essentiel pour répondre correctement à cette requête.
Il renvoyait donc les résultats pour un stationnement sur une colline avec un trottoir.
Bert semble régler ce problème, car le moteur de recherche comprend mieux la requête et le contexte.

Traduit nous avons :
« Pour le stationnement en montée ou en descente. S’il n’y a pas de trottoir, tournez les roues vers le côté de la route afin que la voiture s’éloigne du centre de la route si les freins tombent en panne. Lorsque vous vous garez sur une allée en pente, tournez les roues de manière à ce que la voiture ne roule pas dans la… »
Comme vous pouvez le voir, Google a donné une réponse plutôt correcte pour la requête en question.
À cette étape, vous avez une meilleure compréhension de Google BERT. Voyons comment vous pouvez optimiser votre site web pour profiter d’un bon référencement à l’ère de BERT.
Chapitre 4 : Comment optimiser votre site web pour Google BERT ?
L’optimisation pour les moteurs de recherche consiste à optimiser la visibilité d’un site web dans les moteurs de recherche.
Par conséquent, toute mise à jour que les moteurs de recherche apportent à leur algorithme influence le processus de classement.
4.1. Quel est l’impact de BERT sur le référencement naturel ?
Le point le plus évident et qui découle de tout ce que nous avons évoqué jusque-là est que BERT aide Google à mieux comprendre le langage humain.
BERT arrive à déceler les nuances dans le langage naturel humain, ce qui va faire une grande différence quant à la façon dont Google va interpréter les requêtes.
La firme estime que ce changement va affecter 10% de toutes les requêtes, comme Google tente de le faire savoir :
« En fait, en ce qui concerne le classement des résultats, BERT aidera Search à mieux comprendre une recherche sur dix aux États-Unis en anglais, et nous l’étendrons à d’autres langues et lieux au fil du temps. »
À l’instar de RankBrain, Google compte traiter principalement des requêtes longues et conversationnelles avec BERT :
« En particulier pour les requêtes plus longues et plus conversationnelles, ou les recherches où des prépositions comme « pour » et « à » ont une grande importance pour le sens, Search sera en mesure de comprendre le contexte des mots de votre requête. Vous pouvez effectuer votre recherche d’une manière qui vous semble naturelle. »
Le moteur de recherche compte également appréhender les requêtes dans lesquelles les prépositions ou tout autre mot ambigu sont importants pour comprendre le sens de la phrase.
Ce qu’il faut garder : BERT est une puissante mise à jour que Google utilise pour mieux traiter les requêtes afin de présenter les meilleurs résultats possible à ses utilisateurs.
Évidemment, une autre interprétation / meilleure compréhension des requêtes amène Google à donner d’autres réponses à la place de celles qu’il avait l’habitude de donner.
Beaucoup de gens se plaignent de l’impact sur leur classement et d’autres ont vu leur classement s’améliorer, comme on pouvait s’y attendre.
Avec BERT, Google est en mesure de déterminer si les pages qu’il a classées pour certaines requêtes sont pertinentes ou pas.
Dans ce cas, il pourrait les déclasser et mettre à la place d’autres pages qu’il estime comme étant beaucoup plus approprié.
Et la question tant attendue :
4.2. Comment optimiser votre site web pour Google BERT ?
On aura beau décrire BERT, mais la question la plus importante reste de savoir ce que vous pouvez faire pour optimiser votre site web pour BERT.
Pour cela, nous allons nous référer à Danny Sullivan dont j’ai beaucoup parlé dans mon article sur RankBrain.
Il est le responsable de la liaison avec le public de Google, ce qui veut dire qu’il aide les gens à mieux comprendre la recherche et aide Google à mieux appréhender les réactions du public.
Sa réponse à la question est assez simple :
Traduit en français, nous avons :
« Il n’y a rien à optimiser avec le BERT, ni rien à repenser pour qui que ce soit. Les principes fondamentaux qui nous poussent à récompenser les “grands” contenus restent inchangés… Ma réponse a été que le BERT ne change pas les principes fondamentaux de ce que nous disons depuis longtemps : écrire du contenu pour les utilisateurs. Vous ou toute personne travaillant avec des clients pouvez depuis longtemps dire que c’est ce que nous disons. »
Ce que Danny souligne en fait, c’est qu’il n’y a rien que vous devriez faire à partir d’aujourd’hui que vous n’auriez pas dû faire avant le BERT.
Comme RankBrain, Google BERT permet à Google de mieux comprendre les requêtes.
Par exemple, il n’évalue pas le contenu comme le ferait un algorithme qui tient compte de la vitesse de chargement des sites web pour les classer.
Par conséquent, une optimisation pour BERT revient à : Ecrire des contenus de qualité pour les utilisateurs.
Il ne fait aucun doute que Google se concentre sur le contenu depuis quelques années et je pense que ses prochaines mises à jour iront dans le même sens.
Mais essayons de comprendre comment optimiser le référencement d’un site dans le contexte du BERT.
Je pense que deux aspects principaux doivent être pris en considération lorsque vous souhaitez optimiser votre contenu pour cette mise à jour majeure de Google.
Optimisation pour BERT : Identifiez l’intention de recherche de vos utilisateurs
BERT tente de mieux comprendre les requêtes de l’utilisateur ou pour être plus précis son intention de recherche.
Si les gens effectuent des recherches, c’est avant tout parce qu’il a un besoin à satisfaire.

Dans les exemples donnés par Google et que nous avons vus dans le chapitre précédent, il fallait comprendre l’intention des utilisateurs pour donner une réponse pertinente.
Prenons le premier exemple : « Pouvez-vous obtenir des médicaments pour quelqu’un pharmacie ».
Il faut comprendre que l’intention de recherche est de : Savoir s’il est possible pour un proche de prendre les médicaments à la pharmacie pour un patient.
En lisant la requête d’un trait, il n’est pas évident de déceler cette intention de recherche. C’est pourquoi, il est très important de passer par l’étape de la détermination de l’intention de recherche une fois que vous avez mots-clés.
Pour connaître l’intention de recherche, il faut se poser des questions telles que :
- Pourquoi votre audience des recherches en utilisant certains mots-clés en particulier ?
- Que cherchent-ils à obtenir par leur recherche ?
- Essaient-ils de trouver la réponse à une question ?
- Veulent-ils atteindre un site web spécifique ?
- Veulent-ils effectuer des achats lorsqu’ils utilisent ces mots-clés ?
- Etc.
Avec l’utilisation croissante de la recherche mobile et vocale, où les gens ont besoin de réponses rapides et contextuelles à leurs questions, Google essaie de devenir de plus en plus capable de déterminer l’intention de recherche des gens.
Il faut donc garder à l’esprit que l’ensemble du SERP de Google essaie désormais de correspondre au mieux à l’intention de recherche et non au mot-clé exact recherché.
Depuis quelques années, vous allez constater qu’il y a des situations où le terme exact recherché ne sera même pas inclus dans la page de résultats de recherche de Google. Je le dis par expérience et je suis convaincu de ne pas être le seul.
Cela se produit parce que Google est devenu de plus en plus performant pour déterminer l’intention de recherche des personnes.
J’ai longuement traité ce sujet que vous allez trouver à travers des articles tels que :
Les contenus qui répondent aux intentions de recherche des internautes seront récompensés avec Google BERT.
Optimisation pour BERT : Pensez à la recherche vocale et au featured snippets
Google a déclaré que le BERT concerne les requêtes longues et conversationnelles. Et devinez dans quel type de recherche on retrouve généralement ces deux éléments : la Recherche vocale.
Si BERT traite majoritairement les requêtes longues et le langage naturel, cela voudra dire qu’il permet à google de traiter une bonne partie des recherches vocales qui sont généralement longues :

En plus de la longueur, les requêtes sont généralement conversationnelles.
De la même façon que vous ne pouvez pas dire à votre ami « Eiffel » pour avoir des informations sur ce monument, vous n’allez pas le faire avec votre assistant vocal.
Vous allez être plus conversationnel en posant une question complète : « Qu’est-ce que la tour Eiffel ».
Avec des requêtes longues + conversationnelles, vous allez utiliser tous les mots pour formuler votre question. Ce qui peut vous amener à utiliser les prépositions dont parle Google et qui sont parfois importantes.
Conclusion : La recherche vocale correspond au type de requêtes que Google souhaite traiter avec Google BERT.
Ce fait est peut-être dû au fait que les utilisateurs utilisent de plus en plus d’assistants vocaux pour effectuer des recherches :

Google ne souhaite visiblement pas rater cette révolution qui est beaucoup plus exigeante que la recherche classique avec l’écrit :

Il faut essayer d’optimiser vos contenus pour la recherche vocale et l’une des meilleures manières de commencer est de penser au featured snippet :

Il faut comprendre que les chercheurs ont envie de trouver très rapidement le contenu qui répond exactement à leur question.
Si vous recherchez quelque chose comme « combien font 300 euros en dollars », vous obtiendrez une réponse directe dans le featured snippet :

Avec la mise à jour de BERT, Google s’est efforcé de montrer des featured snippets encore plus pertinents.
Consultez mon article sur la recherche vocale pour apprendre quelques astuces utiles.
Finissons notre guide avec quelques bonnes pratiques à adopter en création de contenu à l’ère de BERT.
Chapitre 5 : Quelques bonnes pratiques à adopter dans le content marketing à l’ère de BERT ?
Google accorde de plus en plus de crédit aux contenus de grande qualité et vous devez vous concentrer sur la rédaction de contenus pertinents pour l’utilisateur.
Si vous avez des contenus de basse qualité sur votre site, il est peut-être temps de faire le ménage ou de les actualiser puisqu’ils risquent de ne pas performer avec Google BERT.
Ce qui nous conduit à la première pratique :
Pratique 1 : Faites un audit des contenus que vous avez publiés
Avant de vous lancer dans la création de nouveaux contenus, la meilleure des approches est de faire un audit des contenus que vous avez publiés jusque-là.
Cette étape vous permet principalement de connaitre les contenus qui apportent le plus de trafic à votre site web et qui vous permettent d’occuper les meilleures positions dans les SERPs.
Une fois ces contenus déterminer, vous allez effectuer une évaluation pour déterminer s’ils :
- Sont naturels et ne contiennent pas de mots-clés ayant une connotation mécanique ;
- Répondent aux intentions des internautes ;
- Sont optimisés pour la recherche conversationnelle ;
- Sont suffisamment qualitatifs pour apporter une réelle valeur ajoutée aux internautes ;
- Sont optimisés pour l’E-A-T ;
- Etc.
Avec les ressources que j’ai énumérées jusque-là, vous aurez probablement plusieurs indicateurs que vous allez examiner.
Cette action vous permet d’optimiser vos contenus de telle sorte qu’ils ne perdent pas en positionnement dans les SERPs.
D’autant plus que si la concurrence des contenus qui offrent une expérience utilisateur meilleur que les vôtres, vous allez moins performer.
Ainsi, un audit de contenu vous permet de renforcer et/ou d’améliorer la position de vos contenus qui performent déjà bien dans les SERPs.

C’est aussi l’occasion de découvrir les contenus de mauvaise qualité et de les optimiser ou de les supprimer s’ils ne servent finalement à rien.
Cela dit, si vous venez de lancer votre site web, il ne faut pas oublier le fait qu’il faut généralement du temps pour que vos contenus commencent à performer.
Pour aller plus loin à ce niveau, vous pouvez envisager un audit SEO complet ou profiter de mon audit SEO gratuit.
Pratique 2 : Créez des contenus d’autorité
Par définition, le marketing de contenu implique la création de contenus à forte valeur ajoutée pour attirer et fidéliser un public clairement défini.
Comme Google comprend mieux le langage naturel, il est clair que les rédacteurs de contenu ont de grandes chances de servir leurs lecteurs avec un contenu écrit de manière plus « humaine ». Et qui répondent entièrement aux intentions de recherche des chercheurs.

BERT semble faire en sorte que Google comprenne encore mieux les requêtes du chercheur, vous n’avez donc pas d’excuse.
Créer des contenus d’autorité est l’une des stratégies les plus efficaces pour appâter Google. La preuve : Toute ma stratégie de création de contenu est basée exclusivement sur les contenus evergreen, ce qui m’a permis d’atteindre actuellement les 6 000 visiteurs par mois.
Consultez mon article sur la technique de surenchère pour savoir comment créer de tels contenus.
Le conseil le plus important est d’effectuer une analyse du SERP pour connaitre le niveau actuel de qualité des contenus présents dans les résultats de Google.
J’ai détaillé ce processus dans mon article sur les 5 étapes à suivre pour analyser le SERP en vue de proposer un meilleur contenu.
Vous allez prêter attention :
- Aux volumes de recherche pour les mots-clés ;
- Le type de contenu classé sur les mots-clés ;
- La difficulté de se classer sur ces requêtes ;
- Les backlinks qui ont permis aux pages de figurer dans les premiers résultats de Google ;
- Etc.
Vous pouvez vous faciliter la tâche en utilisant des outils tels que Moz, Ahrefs, Ubersuggest…
Et si vous vous demandez pourquoi vous avez besoin d’un outil, je vous dirai qu’un outil peut vous donner beaucoup d’indications sur ce qui intéresse réellement vos utilisateurs. Ce qui vous permet d’écrire un contenu qui répondra réellement aux besoins de votre audience.
Pratique 3 : Optimisez votre E-A-T (Expertise Authoritativeness and Trustworthiness)
Google met de plus en plus l’accent sur le concept de l’E-A-T, notamment pour les sites YMYL.
Il s’agit des sites web qui ont un impact sur la vie des internautes :

Mais même si votre site web ne fait pas partie de ces catégories, il est tout aussi important d’accorder une grande importance à l’E-A-T.
Vous vous demandez peut-être quel est le lien avec Google BERT ?
Notez que vous pouvez créer des contenus de qualité, mais si vous manquez d’autorité ou de fiabilité sur la toile, vous risquez de moins performer par rapport à vos concurrents.
Par conséquent, penser à optimiser votre site web pour l’E-A-T est l’une des meilleures stratégies SEO :

Et voilà, il n’y a quasiment rien à ajouter que vous ne connaissiez déjà.
Conclusion : Google BERT – Soyez tout simplement naturel dans la création de vos contenus à forte valeur ajoutée

Depuis sa création, Google n’a cessé d’entretenir sa vision qui est d’offrir les meilleurs résultats à ses utilisateurs.
Dans cette logique, le leader des moteurs de recherche vient d’ajouter une autre mise à jour majeure à sa liste : BERT.
Comme d’habitude, ce changement n’est pas resté inaperçu auprès de la communauté SEO qui se doit de maitriser le fonctionnement des moteurs de recherche pour optimiser leur stratégie de référencement.
Dans cet article, j’ai essayé de montrer comment Google BERT fonctionne en évitant autant que possible les termes techniques. Je n’y ai pas complètement échappé malheureusement ☹
Mais nous avons compris que BERT est un modèle d’apprentissage automatique « open-source » qui se présente comme une avancée majeure dans le domaine du Natural Language Processing.
Google l’utilise pour mieux comprendre les différents mots des requêtes notamment par leur contexte. Une meilleure compréhension qui impacte 10% des requêtes traitées par le moteur de recherche.
Le seul conseil que la firme donne est de se concentrer sur : La création de contenu de haute qualité.

Effectivement, toutes les dernières mises à jour de Google tendent à privilégier les contenus apportant une grande valeur ajoutée aux internautes.
Par conséquent, il est plus que jamais temps de concentrer exclusivement vos efforts sur la création de contenus de haute qualité.
J’ai eu l’occasion de vous donner quelques pistes que vous pouvez exploiter pour profiter pleinement de l’ère Google BERT et probablement des prochaines mises à jour de Google.
Vous souhaitez, comme d’habitude, beaucoup de trafic, je vous dis :
A bientôt !

