

Imaginez avoir écrit le meilleur livre du monde, mais avoir oublié de l’enregistrer dans le registre de la plus grande bibliothèque de la ville. Personne ne pourra jamais le trouver ni le lire. En référencement naturel (SEO), le principe est exactement le même. Qu’est-ce que l’indexation et pourquoi est-elle la base absolue de toute stratégie de visibilité sur internet ?
Dans l’univers du référencement, l’index est tout simplement la gigantesque base de données dans laquelle un moteur de recherche stocke toutes les pages web qu’il connaît et qu’il juge pertinentes. Sans cette étape cruciale, votre site internet n’existe tout simplement pas aux yeux de Google.

Découvrez dans cette nouvelle page de notre dictionnaire SEO tout ce qu’il faut savoir sur ce mécanisme fondamental, de son fonctionnement jusqu’aux bonnes pratiques pour garantir votre présence dans les résultats de recherche.
Chapitre 1 : Indexation – Fonctionnement et importance SEO
Avant de vous submerger de termes techniques, il convient qu’on aborde le fonctionnement de l’indexation pour éviter toute ambiguïté dans le reste du guide.
1.1. Comment fonctionne l’indexation
Quand un site web est nouvellement créé ou une page est nouvellement ajoutée à un site, ils ne sont pas automatiquement accessibles aux moteurs de recherche. Les moteurs doivent d’abord suivre un certain nombre d’étapes avant de les trouver.
Et pour atteindre ces pages, les moteurs de recherche vont envoyer ce qu’on appelle en SEO, des robots d’exploration. Comme l’indique son nom, un robot d’exploration explore les sites en traçant un chemin à base de liens internes et externes.
À travers ces liens, le robot d’exploration va « voyager » entre les pages d’un site ou d’un site à un autre.

Au cours de ce voyage d’exploration, le robot va collecter des informations, les ordonner et les stocker dans une base de données : c’est l’étape d’indexation. Cette base de données est appelée « Index ».
Après une requête lancée, les moteurs de recherche vont puiser dans les informations stockées dans l’index pour proposer des éléments de réponse en fonction des mots-clés entrés par l’utilisateur dans sa requête.
Sans cette étape d’indexation, aucune page d’un site web ne peut être affichée dans les résultats des moteurs après une recherche. C’est une étape indispensable du référencement naturel, mais non suffisante, pour bien classer une page sur les moteurs de recherche.
C’est-à-dire que pour réussir à avoir un bon classement sur Google ou tout autre moteur de recherche, vous devez réunir d’autres critères de classement après l’étape l’indexation des pages.
Donc, lorsqu’un internaute lance une requête sur Google ou Bing par exemple, il ne lance pas sa recherche directement sur le web, mais plutôt dans l’index des moteurs.
Si la recherche lancée concerne bien votre thématique, votre page n’aura aucune chance d’être présentée à l’internaute si elle n’a pas été préalablement explorée et indexée.
De plus, il faut dire que les moteurs de recherche n’indexent pas toujours toutes les pages disponibles sur le Web. Parfois, à cause de la mauvaise qualité des contenus ou de mauvaises pratiques SEO, certaines pages d’un site peuvent ne pas être indexées.
Nous reviendrons plus en détail dans un chapitre ultérieur sur les facteurs qui peuvent empêcher l’indexation d’une page.
Mais dès que l’internaute lance sa requête, que se passe-t-il concrètement entre le laps de temps qui sépare sa requête et la réponse du moteur de recherche ?
Eh bien, le moteur va :
- Analyser la requête de l’internaute pour bien comprendre son intention de recherche.
- Fouiller son index et filtrer les informations en fonction de l’intention de l’internaute.
- Choisir toutes les pages jugées pertinentes à la requête sur la base de plusieurs critères de classement.
- Afficher ensuite ces pages à l’internaute par ordre de pertinence.
Pendant que certains sites mettent régulièrement leurs pages à jour, d’autres finissent obsolètes.
Aussi de nouvelles pages sont créées chaque jour, apportant si possible de nouvelles informations plus pertinentes que les anciens contenus.
Face à ce changement continuel de l’information, pour rester efficaces, les robots d’indexation sont contraints de repasser régulièrement sur les sites déjà indexés.

La fréquence de visite d’un robot d’exploration sur un site dépend de plusieurs facteurs qui définissent le Budget crawl du site.
1.2. Comment fonctionne l’indexation avec Google ?
Comme précédemment expliqué, Google fonctionne également de la même manière pour indexer ses pages web. Ce qu’il faut préciser, c’est que pour explorer le web et indexer les pages disponibles, Google utilise son robodesindexationt d’indexation, Googlebot.

Si au cours de l’exploration, Googlebot tombe sur une page qui est optimisée pour l’indexation, le robot pourra essayer de comprendre la thématique qu’elle aborde. Il peut s’agir d’une page nouvellement créée ou d’une page ancienne, pourvu qu’elle rassemble les critères d’optimisation pour l’indexation.
Pour commencer cette phase d’indexation, Googlebot va analyser le contenu de la page, cataloguer les visuels insérés ainsi que toute autre donnée disponible pouvant l’aider à comprendre l’objet de la page. Toutes les informations collectées seront ensuite classées par thématiques puis stockées dans l’index de Google.
Cet index de Google est une vaste base de données qui contient plusieurs centaines de milliards de pages. Le moteur de recherche lui-même estime la taille de son index à plus de 100 millions de gigaoctets.
À présent, intéressons-nous à l’importance de l’indexation pour le référencement de votre site.
1.3. Quelle est l’importance SEO de l’indexation ?
En expliquant comment les moteurs de recherche indexent les pages web, nous avons évoqué une première importance de l’indexation pour le référencement de votre site.
Vous savez déjà que sans la phase d’indexation, les pages de votre site ne peuvent pas être visibles par les internautes sur une page de résultats des moteurs.
Et ce n’est pas tout, lors du passage de Googlebot sur votre site, le robot pourra détecter éventuellement des logiciels malveillants, des problèmes techniques ou des contenus de mauvaise qualité.
En d’autres termes, vous pouvez prendre l’index de Google comme une source fiable. Si certaines de vos pages y sont répertoriées, c’est une preuve que ces pages témoignent d’une « bonne santé » et qu’elles sont suffisamment pertinentes pour être présentées aux internautes.
Toutefois, rappelons que Google dispose également d’un index secondaire où il stockent des pages de moindre qualité. Il s’agit notamment des pages dupliquées ou jugées « moins pertinentes » par le moteur de recherche.

https://www.twaino.com/wp-content/uploads/2020/12/1-Contenu-duplique-1.png
À priori, Google n’affiche pas les pages rangées dans l’index secondaire dans ses résultats, parce que le moteur de recherche n’accorde pas la même importance à toutes les pages. L’idéal serait donc que vos pages web soient classées dans l’index principal.
Mais pourquoi certaines pages ne sont-elles pas indexées par les moteurs de recherche ? On en parlera dans le prochain chapitre.
Chapitre 2 : Les facteurs qui empêchent l’indexation d’une page
Avant de présenter les facteurs qui pourraient bloquer l’indexation de vos pages, voici ce que vous encourez si cela arrive vraiment :
2.1. Les conséquences des problèmes d’indexation
La nature et les problèmes qui affectent l’indexation d’une page n’ont pas la même mesure en termes de conséquences sur le site.
Si c’est une page qui est moins importante pour le propriétaire qui est touchée, ce n’est sûrement pas la fin du monde.
Mais si en revanche, il s’agit d’une page importante avec un contenu hautement optimisé qui est affectée, c’est bien dommage et tous les efforts de référencement coulent à l’eau.
S’il s’agit d’une boutique e-commerce, les conséquences seront encore plus lourdes. On convient que pour ces sites de commerce en ligne, le trafic organique est plus rentable sur le long terme que les publicités ou les campagnes PPC.

https://www.twaino.com/wp-content/uploads/2019/08/SEO-SEA-SMO-court-moyen-long-terme.png
Imaginez qu’une bonne partie des fiches produits de l’entreprise ne soient pas indexées par Google. Les consommateurs ne les verront pas et la boutique verra son taux de conversion considérablement chuter.
À présent, intéressons-nous aux facteurs proprement dits :
2.2. 10 raisons courantes pour lesquelles Google n’indexe pas tous les liens
Il est vrai que nous avons défini l’index comme la base de données des moteurs, mais les robots d’indexation restent très sélectifs et ne stockent pas tout sur leur passage.
Il existe des raisons courantes pour lesquelles les moteurs de recherche n’indexent pas tous les liens :
2.2.1. Des pages qui renvoient des codes de réponse autres que 200
Vous l’ignorez peut-être, mais si les pages de votre site ne renvoient pas le code de réponse 200, il n’y a aucune chance qu’elles soient indexées ou qu’elles continuent d’être indexées si elles l’ont déjà été.
Le code 200 (OK) désigne une réponse favorable du serveur suite à une requête d’accéder à une page.
Pour des raisons de redirections d’URLs, l’accès à une page peut renvoyer des erreurs 404 ou 500. Et tant que l’erreur n’est pas levée, les moteurs de recherche n’indexeront pas cette page.
Vous pouvez vérifier le statut de vos pages importantes sur HTTPStatus.io. Juste l’URL de la page et l’outil affiche le statut de la page :

Si vous retrouvez des pages avec le code 404, je vous invite à consulter mon article Erreur 404 : Pourquoi et Comment la corriger efficacement ?
2.2.2. L’indexation peut être aussi bloquée par le fichier Robots.txt
Vous aurez beau investir la même attention pour rédiger tous vos contenus, mais il y a probablement des pages qui représentent plus d’intérêts pour vos affaires que d’autres.
Même si le défi des moteurs est de fournir des pages pertinentes aux internautes, quel serait votre intérêt s’ils priorisaient des pages qui ne sont pas forcément prioritaires pour vous.
C’est pourquoi les moteurs de recherche donnent la main aux propriétaires de sites web d’indiquer les contenus qu’ils souhaitent activement voir être indexés.
Le fichier Robots.txt se situe à la racine de votre site et permet de faire des recommandations d’indexation aux moteurs de recherche. Donc si l’une de vos pages ne se retrouve pas dans l’index de Google, le premier réflexe à avoir serait de consulter le fichier Robot.txt.
S’il s’agit d’une page déjà indexée par le moteur de recherche, vous recevrez un message vous notifiant que la page n’est plus disponible et que le problème provient du fichier Robots.txt :

Source : Kern Media
Consultez mon article sur le fichier Robots.txt pour découvrir comment optimiser votre fichier Robots.txt et lever de telles erreurs.
2.2.3. La balise Meta Robots avec la valeur « Noindex »
Une autre raison des plus fréquentes pour laquelle un site web peut se retrouver non indexé par Google est la présence de la balise Meta Robots dans la partie <head> du code source de la page.
Si cette balise prend la valeur « noindex », c’est un message adressé à Google lui indiquant de ne pas indexer la page concernée. Et effectivement, Google n’indexera pas la page tant que la valeur ne sera pas changée.
Pour vérifier la valeur que prend la balise Meta Robots sur une page, faites un clic droit sur la page et cliquez sur « Inspecter l’élément » pour accéder directement au code source.
Pour aller vite, vous pouvez combiner les touches Ctrl + U, toujours pour accéder au code source.

Une fois dans le code, remplacez la valeur du paramètre « content » par ce qui vous convient le mieux. Découvrez la syntaxe de la balise ainsi que les différentes valeurs possibles à attribuer dans cet article qui définit de long en large la balise Meta Robots.
2.2.4. La balise X-Robots avec la valeur « Noindex »
Cette balise fonctionne un peu comme la Meta Robots. Elle permet également de contrôler la façon dont Google doit indexer une page. Mais il faut dire que la balise X-Robots se retrouve plutôt dans la réponse d’en-tête des pages web ou de certains documents.
Il s’agit généralement des pages non HTML sans la section <head> telles que les documents PDF, DOC, etc.
À moins que vous ayez ajouté intentionnellement « noindex » à la balise X-Robots, il est très rare que cela se produise par accident. Dans tous les cas, vérifiez aussi cette éventualité pour vous assurer que ce n’est pas la balise X-Robots qui empêche l’indexation de votre page.
Pour le faire, vous pouvez utiliser l’extension chrome SEO Site Tools :

Source : Kern Media
2.2.5. Les contenus en double sur le site
Les contenus dupliqués sur un même site sont très néfastes pour le référencement en général. Un contenu qui se retrouve partiellement ou intégralement dupliqué sur une autre page du même site peut empêcher les autres à ne pas être indexées par les moteurs de recherche.
Donc si vous remarquez des contenus en double sur votre site, il est possible qu’ils soient à la base de votre problème d’indexation.
Si le nombre de copies est élevé, même la page originale se verra déclassée sur les SERP de Google. Donc si vous remarquez qu’une page
Pour savoir si vous avez des contenus dupliqués sur votre site, vous pouvez utiliser l’outil Siteliner pour explorer rapidement le site et récupérer les URLs des pages dupliquées.
Son utilisation reste assez simple, vous entrez juste le nom de domaine du site et l’outil se chargera de fournir un graphique avec le taux de pourcentage des contenus dupliqués.

Google reste assez ferme sur les contenus dupliqués et tolère à la limite quelques petits passages qui peuvent se répéter.
Donc dans une certaine mesure, il est bien possible que des pages avec des contenus semblables sur votre site puissent être indexées et obtenir un classement sur Google.
Mais s’il s’agit d’un contenu de volume important qui est copié-collé intégralement sur d’autres pages, il est probable que Google sanctionne ces pages quitte à même les supprimer de son index.
2.2.6. Les contenus en double à l’extérieur du site
Même si vous faites attention aux contenus dupliqués sur votre site, des contenus en double venant de l’extérieur, d’autres sites peuvent toujours vous atteindre.
Un nombre important d’un de vos contenus qui est dupliqué sur plusieurs autres sites est également très mal vu du moteur de recherche.
Qu’importe votre secteur d’activité ou le type de site que vous disposez, les sanctions de Google contre les contenus dupliqués restent les mêmes. Si vous soupçonnez quelques sites web d’avoir plagié un extrait de vos contenus, mettez l’extrait entre 2 guillemets puis lancez la recherche sur Google.
Vous aurez la liste des sites web qui ont utilisé cet extrait dans leur contenu, un peu comme on retrouve les citations sur Google.
Pour être sûr du résultat, vous pouvez utiliser un outil dédié capable de repérer les contenus dupliqués, il s’agit de Copyscape. L’outil fournit un rapport détaillé des sites web qui vous ont plagié.

Vous pouvez également utiliser l’outil de vérification de plagiat Quetext pour savoir si des sites ont copié scrupuleusement vos contenus.
Une fois ces sites répertoriés, découvrez dans cet article les stratégies à effectuer pour revendiquer vos contenus dupliqués et demander à Google de vous restituer le droit.
2.2.7. Des pages qui n’apportent aucune valeur ajoutée aux internautes
Le premier défi des moteurs de recherche est de fournir que des résultats qui soient pertinents et qui répondent efficacement à la requête de l’utilisateur.
Malheureusement, tous les contenus déversés sur le Net n’apportent pas une réelle valeur ajoutée aux internautes.
Si vous pensez être dans le même cas, arrangez la qualité de vos contenus le plus tôt possible pour offrir une meilleure expérience à vos utilisateurs. Google saura vous récompenser en indexant régulièrement vos pages.

Nous avons par exemple les sites d’affiliation qui génèrent généralement des publicités sans trop se soucier de la satisfaction de l’internaute. Les algorithmes de Google deviennent de plus en plus intelligents et sont à même de détecter ces pages de peu de valeur pour ne pas les indexer.
2.2.8. Votre site vient nouvellement d’être créé
Si vous venez de créer votre site, il est important de savoir que son indexation ne se fera pas de façon systématique. Il faut du temps pour que Google ou tout autre moteur de recherche vous découvrent.
Comme expliqué précédemment, pour atteindre votre site, Google se frayera un chemin construit avec des liens. C’est pourquoi il est important d’avoir de bonnes stratégies de création de liens, surtout s’il s’agit d’un site nouvellement créé.
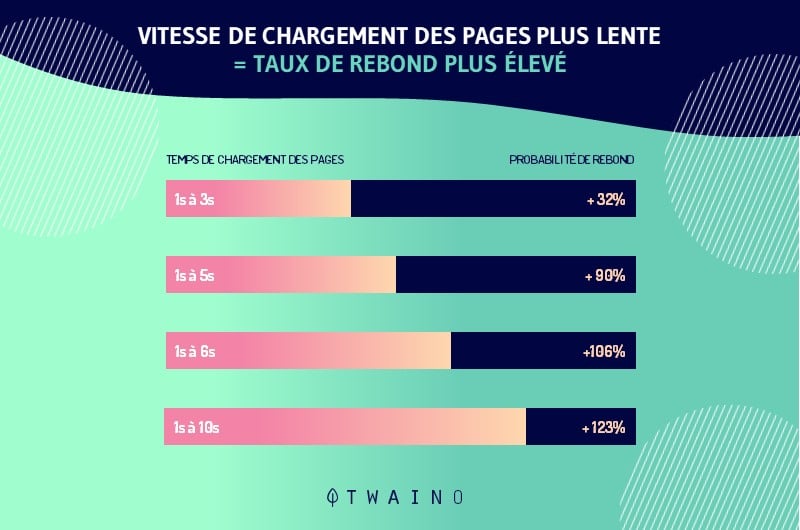
2.2.9. La vitesse de chargement de votre page
Au-delà de la qualité des contenus textuels, un site doit également améliorer ses performances techniques.
Malgré ses contenus, un site qui met une éternité à se charger ou qui enchaîne des fenêtres de pop-up de façon intempestive, un site qui offre une mauvaise expérience utilisateur pour faire court sera toujours mal vu par les moteurs de recherche.
Le temps de chargement que mettent vos pages impacte directement le taux de trafic. Plus le temps de chargement est lent, moins les internautes vont durer sur votre site.

Et puisque Google prône toujours l’expérience utilisateur, le moteur décourage les sites qui n’ont pas une vitesse de chargement rapide.
Si le problème de lenteur persiste, Google peut même décider de retirer la page concernée de son index.
Il existe un certain nombre d’outils pour tester la rapidité de chargement de vos pages, notamment le Page Speed Insights de Google ou l’outil GTMetrix.
2.2.10. Les pages orphelines
Pour mettre à jour son index, Google explore régulièrement les sites web y compris les plans de site XML. Si le vôtre est souvent visité par Googlebot et que vous réunissez les facteurs de classement, le moteur de recherche pourra améliorer votre positionnement sur ses SERP.
Mais si lors de l’exploration Google ne trouve pas de liens qui redirigent vers un contenu particulier de votre site, ce contenu ne sera simplement pas indexé.
Qu’importe si le lien est interne ou qu’il provienne d’un site extérieur, Google en a besoin pour atteindre le contenu, l’explorer et si possible l’indexer.
Ces pages qui n’ont aucun lien interne sont ce qu’on appelle en SEO des « pages orphelines ». Si votre site compte trop de pages orphelines, cela peut dissuader Google d’indexer régulièrement votre site.
Pour détecter les pages orphelines qui sont sur votre site, vous pouvez utiliser l’outil Screaming Frog.

Pour la petite astuce, vous pouvez exporter toutes les URLs explorées par Screaming Frog sur une feuille de calcul.
Puis comparez cette première liste d’URLs à celle disponible dans votre plan de site XML. Tous les liens qui se retrouveront dans le plan de site et non dans le rapport d’exploration de Screaming Frog seront donc considérés comme des pages orphelines.
C’est bien de savoir reconnaître les problèmes d’indexation qui minent votre site et les réparer.
Mais c’est encore mieux de garder constamment un œil sur le site pour vite repérer ces problèmes avant qu’ils n’affectent votre référencement.
2.3. Monitorez l’état d’indexation de votre site avec la Google Search Console
Comme on a pu le voir, avoir des erreurs d’indexation peut ruiner le référencement d’un site et faire baisser son chiffre d’affaires.
Mais avant d’en arriver là, Google met à votre disposition un outil pour surveiller constamment l’état d’indexation de votre site : il s’agit de la Google Search Console.
Pour l’utiliser, accéder à l’outil GSC ;
Ensuite dans la barre latérale gauche, cliquer sur les options « Sitemap » et « Couverture » situées juste en dessous de l’onglet « Index » :


Il est recommandé de vérifier l’état d’indexation au moins une fois chaque mois ou 2 mois pour détecter les erreurs plutôt.
Après avoir réparé les problèmes d’indexation de leur site, une question revient souvent dans le rang des propriétaires de site : « Quand est-ce que ma page sera indexée ? ».
2.4. Savoir quand une page sera indexée
Bon nombre de propriétaires de site web s’inquiètent et se demandent quand est-ce que leur page sera indexée. Eh bien, il n’existe malheureusement aucune réponse précise qu’on pourrait donner à cette question.
Le fait est que vous ne contrôlez pas tout quand il s’agit d’indexation d’une page. Malgré tous vos efforts, conformément aux guidelines de Google, il existe d’autres facteurs extérieurs qui ne dépendent pas forcément de votre volonté à voir page vite indexée.
Tout simplement parce que vous n’êtes pas le seul à vouloir être indexé par Google. Il existe des millions et des millions d’autres pages disponibles sur le Web qui attendent d’être explorées.
Votre tour peut-être demain, ou dans la semaine prochaine ou dans quelques mois, il est difficile de donner un délai exact. Tout va dépendre de la fréquence que Google s’est fixé d’explorer votre site.
Néanmoins, Google offre une possibilité de lui formuler une demande d’exploration de vos nouvelles URLs.
2.5. Comment demander une exploration à Google ?
Pour toute nouvelle page ou récemment mise à jour sur votre site, vous pouvez formuler une demande d’indexer adressée à Google en suivant les méthodes ci-après :
2.5.1. Utilisez l’outil d’inspection d’URL pour demander l’indexation de quelques pages
Avant de présenter la procédure à suivre, il est important de souligner que sans un accès à un compte Google Search Console, vous ne pouvez pas demander une indexation avec l’outil d’inspection de Google.
Pour cela :
- Surveillez l’URL concernée avec l’outil d’inspection d’URL de Google ;
- Sélectionnez « Inspection de l’URL ». L’outil démarrera un test de l’URL en ligne pour vérifier si elle est déjà indexée ou pas :

Vous serez notifié s’il y a le moindre problème ou si la page est déjà présente dans l’index de Google :

Mais si la page n’est pas encore indexée, vous pouvez demander une indexation :

Remarque : La demande d’exploration ne garantit pas que l’URL sera automatiquement stockée dans l’index de Google. Dans certains cas, l’indexation peut même ne pas avoir lieu. Le cas d’un contenu de mauvaise qualité par exemple.
2.5.2. Demande l’indexation d’un grand nombre d’URLs avec le sitemap
Le sitemap est un fichier dans lequel Google arrive à avoir une idée des URLs que compte votre site. Si vous ne savez pas créer un sitemap, vous pouvez consulter cet article proposé par Google.
Si un sitemap n’a pas été modifié depuis la dernière exploration de Google, il ne sert à rien de le renvoyer encore au moteur de recherche. Mais si vous avez ajouté des pages à votre sitemap, prenez soin de le taguer avec l’attribut <lastmod>.
Voici les différentes étapes à suivre pour alerter Google des modifications apportées au sitemap :
- Envoyez un sitemap grâce au rapport sur les sitemaps ;
- Avec votre navigateur ou l’éditeur de commande, vous pouvez envoyer une requête GET à l’adresse suivant en renseignant le lien complet du sitemap : http://www.google.com/ping?sitemap=<full_URL_of_sitemap>
Exemple :
http://www.google.com/ping?sitemap=https://example.com/sitemap.xml
- Ensuite, rendez-vous dans votre fichier Robots.txt et ajoutez le bout de code suivant :
Sitemap: http://example.com/my_sitemap.xml
Grâce aux étapes ci-après, Google pourra explorer les pages ajoutées au sitemap lors de sa prochaine visite.
Chapitre 3 : Indexation image : Comment référencer ses visuels ?
On l’oublie souvent, mais Google Images est le deuxième moteur de recherche le plus utilisé au monde ! Réussir son indexation image est donc une opportunité en or pour générer un trafic qualifié supplémentaire vers votre site web.
Cependant, les robots de Google n’ont pas d’yeux humains : ils ne peuvent pas « voir » vos photos ni comprendre de quoi elles parlent simplement en les regardant. Pour que les algorithmes comprennent le contenu de vos visuels et les ajoutent à leur index, vous devez absolument les aider en traduisant vos images en informations textuelles.
Voici les 4 bonnes pratiques incontournables pour garantir une excellente indexation image :
3.1. Un nom de fichier descriptif
Avant même d’importer votre image sur votre site, renommez le fichier brut sur votre ordinateur. Oubliez les noms génériques générés par les appareils photo comme IMG_8472.jpg. Utilisez des mots-clés clairs et séparez-les par des tirets (le tiret du 6). Exemple : chaussure-course-homme-rouge.jpg.
3.2. La balise Alt (Texte alternatif)
C’est le critère SEO le plus important pour vos visuels. Cette balise HTML permet de décrire de manière concise ce que contient l’image. Elle est lue par les robots pour comprendre le contexte, mais elle sert aussi à l’accessibilité web (lue par les logiciels pour malvoyants). Soyez précis et intégrez-y naturellement votre mot-clé principal.
3.3. Le poids et le format de l’image
Une image trop lourde (qui pèse plusieurs mégaoctets) va drastiquement ralentir le temps de chargement de votre page. Un site lent décourage les internautes, mais gaspille aussi le temps précieux des robots de Google (ce qui freine l’indexation de vos autres pages). Compressez toujours vos visuels avant publication et privilégiez des formats « next-gen » très légers, comme le WebP.
3.4. Le Sitemap dédié aux images
Si votre site repose fortement sur le visuel (comme une boutique e-commerce, un portfolio de designer ou un site de photographie), facilitez la tâche des moteurs de recherche. Générez et soumettez un sitemap XML spécifiquement dédié à vos images via la Google Search Console. Cela centralise toutes vos URL d’images au même endroit et garantit que même les visuels enfouis profondément dans votre site soient explorés.
Conclusion
En somme, l’indexation est une étape incontournable pour le référencement d’une page web et fait partie d’un processus assuré par les robots d’indexation.
Après avoir nouvellement créé un site web ou publié une nouvelle page, entièrement optimisée pour le référencement, la meilleure façon d’aider sa page à être indexée serait d’attendre.
Bien que pour certaines raisons, on peut parfois être obligé de recourir à des méthodes pour indiquer quelques recommandations aux moteurs de recherche.
J’espère que cette définition sur « L’indexation » vous aura servi et apportera un plus à votre connaissance dans le référencement.
Si vous avez d’autres questions, n’hésitez pas à me les poser dans les commentaires.
Merci et à bientôt !
FAQ – Indexation SEO : Définition, Fonctionnement et Guide Complet
Combien de temps met Google pour indexer une nouvelle page ?
Le délai d’indexation web est très variable. Cela peut prendre de quelques heures (pour un grand site d’actualités très visité) à plusieurs semaines pour un site récent. Pour accélérer ce processus, soumettez toujours votre nouveau lien (ou votre fichier Sitemap) directement via la Google Search Console et créez des liens internes vers cette nouvelle page.
Qu’est-ce que le budget de crawl en référencement ?
Le budget de crawl correspond au nombre maximum de pages que les robots d’exploration (comme Googlebot) vont visiter sur votre site pendant une période donnée. Pour garantir une bonne indexation moteur de recherche, il est crucial de ne pas gaspiller ce budget sur des pages inutiles, afin que les algorithmes se concentrent uniquement sur vos contenus stratégiques.
Faut-il indexer absolument toutes les pages de son site web ?
Non, c’est même fortement déconseillé ! Certaines pages n’ont aucune valeur SEO et ne doivent pas apparaître dans les résultats : panier d’achat, page de connexion, mentions légales ou résultats de recherche interne. L’utilisation d’une balise « noindex » sur ces URL permet de concentrer l’indexation sur vos contenus à forte valeur ajoutée et d’optimiser votre budget d’exploration.
Comment forcer la réindexation d’une page mise à jour ?
Si vous venez d’améliorer un article existant, vous n’avez pas besoin d’attendre le passage naturel des robots. Rendez-vous dans la Google Search Console, collez votre lien dans l’outil d’inspection d’URL, puis cliquez sur « Demander l’indexation ». Cela placera votre page dans une file d’attente prioritaire pour déclencher une reindexation rapide et afficher vos nouveautés dans les résultats.
Comment savoir si mon site est indexé sur Google ?
Pour vérifier l’indexation de votre site, la méthode la plus rapide est d’utiliser la commande « site: » directement dans la barre de recherche Google (par exemple : site:votre-nom-de-domaine.com). Les résultats affichés correspondront à toutes vos pages actuellement enregistrées. Pour une analyse technique plus précise page par page, utilisez le rapport de couverture de la Google Search Console.
Quelle est la différence entre indexation et positionnement ?
Ces deux concepts sont souvent confondus en SEO. L’indexation moteur de recherche signifie simplement que Google connaît votre page et l’a rangée dans sa base de données. Le positionnement (ou ranking) correspond à la place qu’occupe cette page dans les résultats. Une page peut tout à fait être indexée et connue de Google, mais stagner à la 80ème position !
Pourquoi Google refuse-t-il d’indexer ma nouvelle page web ?
Plusieurs facteurs peuvent bloquer ce processus. La cause la plus fréquente est la présence d’une balise HTML « noindex » dans votre code ou un blocage via le fichier robots.txt. Google peut aussi ignorer votre page si le contenu est de très faible qualité (thin content), s’il s’agit de contenu dupliqué, ou si la page manque cruellement de liens internes.
Qu’est-ce qu’une page orpheline et comment l’indexer ?
Une page orpheline est une URL qui existe sur votre site, mais qui ne reçoit aucun lien interne depuis vos autres pages. Les robots d’exploration de Google naviguant de lien en lien, ils auront énormément de mal à la trouver. Pour garantir son indexation web, intégrez toujours vos nouveaux articles dans le maillage interne de votre site.
Le fichier robots.txt bloque-t-il toujours l’indexation ?
C’est une erreur classique ! Le fichier robots.txt interdit l’exploration (le crawl) d’une page par les robots, mais n’empêche pas techniquement son indexation. Si d’autres sites font des liens vers cette page bloquée, Google peut quand même l’ajouter à son index sans en lire le contenu. Pour désindexer définitivement une page, privilégiez toujours la balise meta « noindex ».
Est-il obligatoire d’avoir un sitemap XML pour être indexé ?
Non, ce n’est pas strictement obligatoire, surtout pour un petit site vitrine où toutes les pages sont facilement accessibles via le menu principal. Cependant, c’est vivement recommandé ! Un sitemap agit comme un plan détaillé. Il facilite le travail des robots et accélère grandement l’indexation de vos nouvelles pages, particulièrement si votre site possède des milliers d’URL.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}