In un momento in cui la concorrenza nelle SERP di Google è agguerrita, diventa fondamentale svolgere attività che abbiano un reale valore aggiunto per la referenziazione del proprio sito web. In linea con i requisiti dei motori di ricerca, gli sforzi sono sempre più concentrati sul miglioramento del contenuto semantico delle pagine web.
Il primo passo in questo processo è estrarre il contenuto testuale delle pagine web che dovranno essere ottimizzate. Ma estrarre contenuti senza markup HTML non è facile. Esistono molte tecniche per farlo manualmente e la maggior parte di esse richiede competenza in linguaggi di programmazione avanzati come Python, JavaScript, ecc.
Fetch HTML content di IMN è uno strumento di estrazione automatica che è stato sviluppato per semplificare questo compito ai professionisti SEO e alle aziende. Scopriamo in questa descrizione come utilizzarlo per separare il codice HTML dal contenuto del tuo sito web.
Che cos’è lo strumento per i contenuti Fetch HTML di IMN?
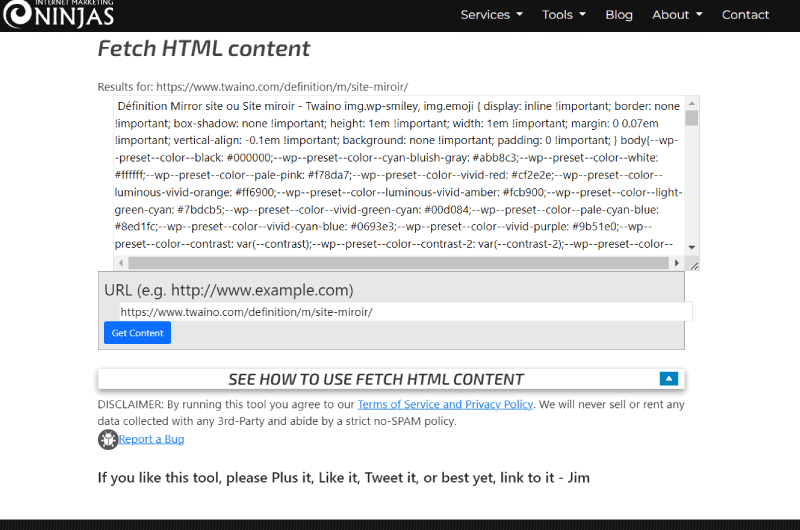
Fetch HTML content è uno strumento pratico e gratuito che ti consente di visualizzare il testo di una pagina Web senza la formattazione e il codice HTML che lo compongono.
Disponibile gratuitamente online dalla gamma di strumenti offerti da Internet Marketing Ninjas (IMN), lo strumento separa il markup HTML dal resto del contenuto testuale della tua pagina web senza manipolare o modificare direttamente il programma che lo compone.
Quando parliamo di una pagina web, questa include infatti un lungo programma che combina principalmente HTML. Per uno sviluppatore web, con poche righe di codice, ad esempio poche espressioni regolari, il trucco è fatto. Potrà individuare senza troppe difficoltà il contenuto testuale del markup HTML della pagina web su cui vuole lavorare. Ma per altri attori della SEO e del marketing digitale, è tutta un’altra storia.
In genere vogliono estrarre un testo che abbia un senso. Ecco perché è importante estrarre la massima qualità possibile. Lo strumento HTML Content Extractor di IMN rimuove gli elementi HTML e conserva solo la parte della tua pagina che ti è utile: il testo che contiene le informazioni pertinenti.
Questo è il modo in cui l’utilità di contenuto HTML Fetch ti invia automaticamente testo privo di HTML e pronto per l’uso.
Come utilizzare lo strumento per i contenuti Fetch HTML di IMN?
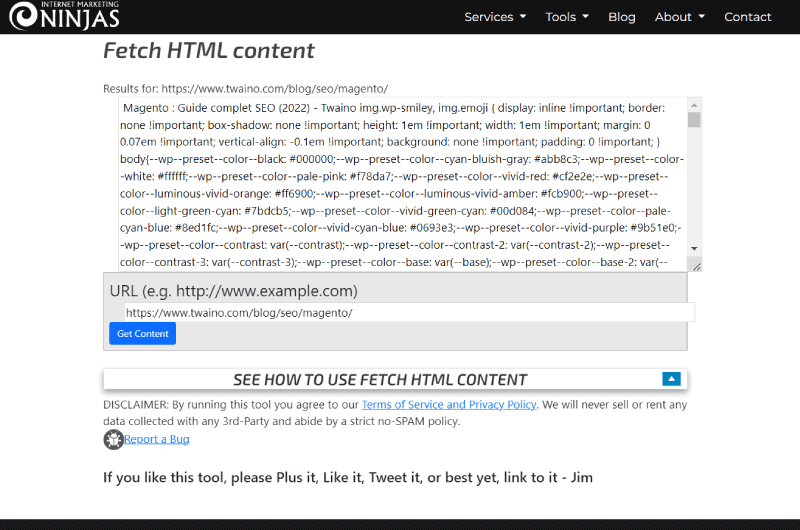
Estrarre contenuto di testo da una pagina web non è mai stato così facile. In effetti, lo strumentoRecupera contenuto HTML di IMN è molto facile da imparare e da usare.
Tutto quello che devi fare è identificare la pagina web di cui vuoi ottenere il contenuto testuale inserendone l’url in un campo previsto a tale scopo. Quindi devi solo fare clic sul pulsante “Ottieni contenuto” e lo strumento catturerà immediatamente il testo dalla pagina dopo aver rimosso il resto.
Quali sono i pro e i contro dello strumento per i contenuti Fetch HTML di IMN?
Come ci si potrebbe aspettare, ci sono molti vantaggi nell’usare lo strumento di recupero del contenuto HTML offerto da Internet Marketing Ninjas. Tuttavia, ci sono limitazioni relativamente innocue.
Tra i vantaggi di Fetch HTML content, i più importanti sono i seguenti.
- Uno strumento pratico e accessibile: Con questo estrattore di contenuti testuali, non è necessario conoscere alcun linguaggio di programmazione web per separare il codice HTML per recuperare il testo non elaborato che ti è utile su una pagina web.
- Uno strumento efficace e facile da usare:Questa utilità consente di ottenere automaticamente e istantaneamente il testo presente su una pagina web senza la formattazione e il codice di detta pagina web.
- Un facilitatore del riferimento naturale delle pagine web: Questo strumento semplifica l’ottimizzazione e l’aggiornamento dei contenuti Web perché fornisce il testo necessario per creare riepiloghi pertinenti.
- Estrazione del testo in chiaro di una pagina web senza alcuna modifica del codice HTML di detta pagina: Poiché l’estrazione viene effettuata in remoto dalla pagina Web da cui si desidera recuperare il contenuto testuale, si evita il rischio di bug dovuti alla manipolazione e alla modifica del programma HTML della pagina.
Oltre a questi innegabili vantaggi, va detto che lo strumento di contenuto Fetch HTML presenta anche un notevole svantaggio
Il testo recuperato contiene boilerplate in eccesso: Con questo strumento viene recuperato tutto il contenuto visibile della pagina web. Così, dopo l’estrazione, ci ritroviamo con un testo sicuramente privo di tag HTML ma che contiene gli elementi del menu, il media, l’header e il footer detto anche boilerplate.
L’utility gratuita Fetch HTML content sviluppata da Internet Marketing Ninjas, estrae il contenuto visibile della pagina web di tua scelta. Elimina automaticamente i tag HTML, lasciando solo testo normale. Inserisci un URL e guarda tu stesso i risultati.




 Alexandre MAROTEL
Alexandre MAROTEL