Bienvenida » Herramientas » SEO » HTML Fetch | Internet Marketing Ninjas
HTML Fetch | Internet Marketing Ninjas
- Herramientas : SEO técnico
- Plataforma : Web
- Premio : Libre
Resumen rápido de la herramienta: HTML Fetch
¿Quiere mostrar el contenido de una página web sin el código HTML? Descubra cómo hacerlo al instante con la herramienta Fetch HTML content de IMN.
Presentación detallada de la herramienta: HTML Fetch
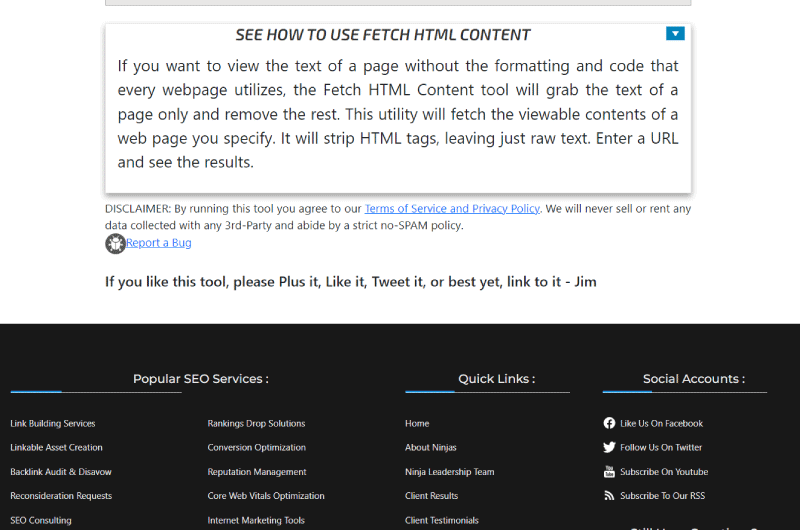
Descripción de la herramienta Fetch HTML content – Internet Marketing Ninjas
En un momento en que la competencia en las SERPs de Google es feroz, se vuelve fundamental realizar tareas que tengan un valor agregado real para la referenciación de su sitio web. De acuerdo con los requisitos de los motores de búsqueda, los esfuerzos se centran cada vez más en mejorar el contenido semántico de las páginas web.
El primer paso en este proceso es extraer el contenido textual de las páginas web que deberán optimizarse. Pero extraer contenido sin marcado HTML no es fácil. Existen muchas técnicas para hacer esto manualmente, y la mayoría de ellas requieren dominio de lenguajes de programación avanzados como Python, JavaScript, etc.
Fetch HTML content by IMN es una herramienta de extracción automática que se desarrolló para facilitar esta tarea a los profesionales y empresas de SEO. Descubramos en esta descripción cómo usarlo para separar el código HTML del contenido de su sitio web.
¿Qué es la herramienta de búsqueda de contenido HTML de IMN?
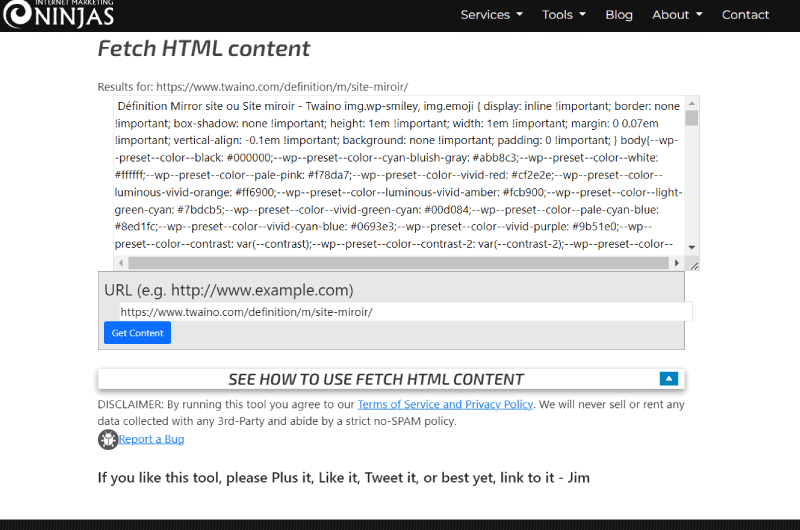
Fetch HTML content es una herramienta útil y gratuita que le permite ver el texto de una página web sin el formato y el código HTML que lo componen.
Disponible gratuitamente en línea de la gama de herramientas que ofrece Internet Marketing Ninjas (IMN), la herramienta separa el marcado HTML del resto del contenido textual de su página web sin manipular o modificar directamente el programa que lo compone.
Cuando hablamos de una página web, ésta sí incluye un programa largo que combina principalmente HTML. Para un desarrollador web, con unas pocas líneas de código, por ejemplo, algunas expresiones regulares, el truco está hecho. Podrá individualizar el contenido textual del marcado HTML de la página web sobre la que quiere trabajar sin demasiada dificultad. Pero para otros jugadores de SEO y marketing digital, es una historia completamente diferente.
Por lo general, quieren extraer texto que tenga sentido. Por eso es importante extraer la mayor calidad posible. La herramienta de extracción de contenido HTML de IMN elimina elementos HTML y conserva solo la parte de su página que le resulta útil: el texto que contiene la información relevante.
Así es como la utilidad Obtener contenido HTML le envía automáticamente texto libre de HTML y listo para usar.
¿Cómo utilizar la herramienta de búsqueda de contenido HTML de IMN?
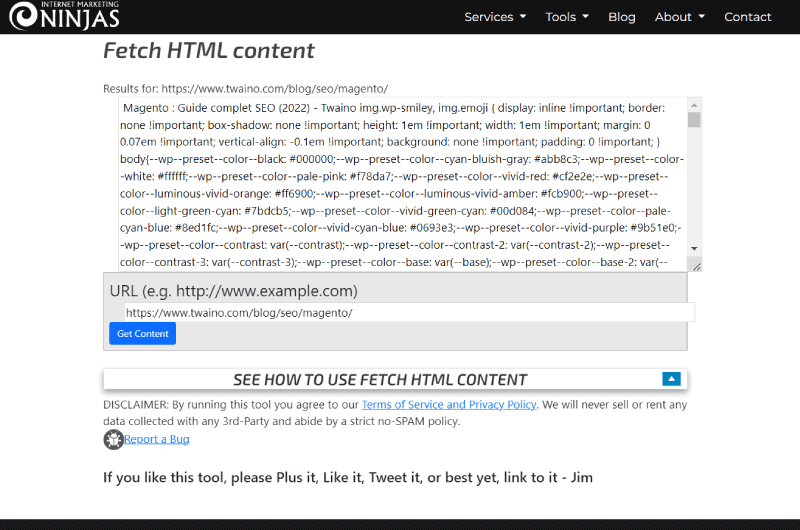
Extraer contenido de texto de una página web nunca ha sido tan fácil. De hecho, la Fetch HTML content de IMN es muy fácil de entender y usar.
Lo único que tiene que hacer es identificar la página web cuyo contenido textual desea obtener introduciendo su url en un campo habilitado a tal efecto. Luego, solo tiene que hacer clic en el botón «Obtener contenido» y la herramienta tomará instantáneamente el texto de la página después de eliminar el resto.
¿Cuáles son los pros y los contras de la herramienta Fetch HTML content de IMN?
Como es de esperar, existen muchos beneficios al usar la herramienta de extracción de contenido HTML que ofrece Internet Marketing Ninjas. Sin embargo, existen limitaciones relativamente inocuas.
Entre las ventajas de Fetch HTML content, las más importantes son las siguientes.
- Una herramienta práctica y accesible: Con este extractor de contenido textual no necesitas dominar lenguajes de programación web para separar el código HTML para poder recuperar el texto sin procesar que te es útil en una página web.
- Una herramienta eficaz y fácil de usar: esta utilidad le permite obtener de forma automática e instantánea el texto presente en una página web sin el formato y el código de dicha página web.
- Un facilitador de la referenciación natural de páginas web: Esta herramienta facilita la optimización y actualización del contenido web porque proporciona el texto necesario para la creación de resúmenes relevantes.
- Extracción del texto sin procesar de una página web sin modificar el código HTML de dicha página: La extracción se realiza de forma remota desde la página web cuyo contenido textual se desea recuperar, el riesgo de errores debido a la manipulación y modificación de la Se evita el programa HTML de la página.
Aparte de estas innegables ventajas, hay que decir que la herramienta Fetch HTML content tiene también una notable desventaja
El texto recuperado contiene un exceso de repetitivo: Con esta herramienta se recupera todo el contenido visible de la página web. Así, después de la extracción, terminamos con un texto ciertamente desprovisto de etiquetas HTML pero que contiene los elementos del menú, los medios, el encabezado y el pie de página también llamado repetitivo.
La utilidad gratuita Fetch HTML content desarrollada por Internet Marketing Ninjas, extrae el contenido visible de la página web de su elección. Elimina automáticamente las etiquetas HTML, dejando solo texto sin formato. Ingrese una URL y vea los resultados usted mismo.
Vídeos de herramientas: HTML Fetch
Galería de herramientas: HTML Fetch
Presentación de la empresa: HTML Fetch
Internet Marketing Ninjas es una empresa fundada en 1999 por Jim Boykin, con más de 10 años de experiencia en el campo del SEO. La misión de la empresa es ayudar a sus clientes a obtener un mejor tráfico en sus sitios web a través de métodos seguros.
Internet Marketing Ninjas se especializa en optimizar páginas y sitios web para motores de búsqueda. Con sede en Clifton Park, Estados Unidos, la empresa está compuesta por 50 miembros, todos expertos en sus
campos.Internet Marketing Ninjas ofrece a toda la comunidad digital servicios completos de marketing digital, pero también servicios y herramientas de SEO. Entre las más de 87 herramientas desarrolladas por ellos, aquí hay algunas herramientas gratuitas de SEO que han desarrollado:
- Herramienta Social Image Resizer;
- ¿Cuál es la herramienta de tamaño de mi navegador?
- Herramienta de visor de código fuente HTML;
- Analizador de metaetiquetas;
- Comprobador de edad de dominio;
- Generador de metaetiquetas y vista previa de fragmentos;
- Simulador de araña de motor de búsqueda;
- Herramienta de combinación de palabras clave;
- Herramienta de inspección de URL…
Estas herramientas están dirigidas a las agencias de SEO, así como a los profesionales del marketing, sin mencionar a las empresas. Seguramente ayudarán a mejorar sus diversas estrategias de marketing.
Encuentre la empresa: HTML Fetch
HTML Fetch en las redes sociales
- Chaîne Youtube
Les autres outils associés : Fetch HTML

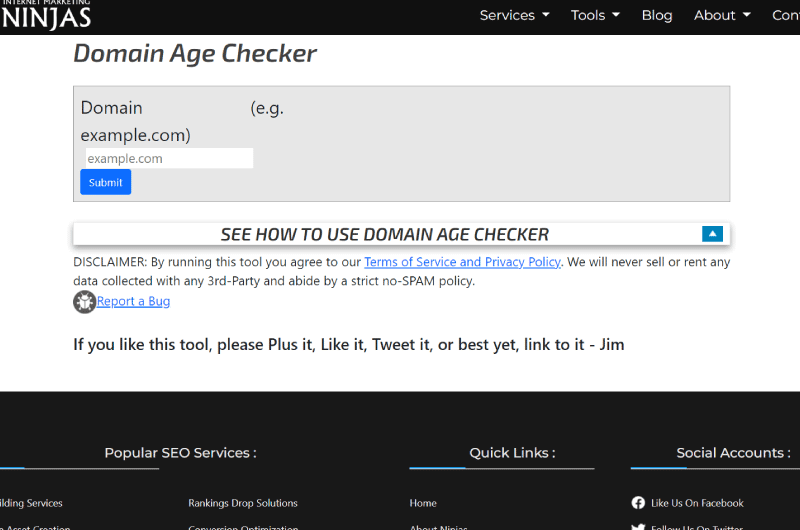

Antigüedad del dominio | Internet Marketing Ninjas
Domain Age Checker es una herramienta que puede decirle la edad de cualquier dominio, incluidos los de sus competidores, así como las URL que desee adquirir. Dado que los dominios más antiguos pueden tener una pequeña ventaja en las clasificaciones de los motores de búsqueda, el Verificador de edad del dominio también muestra cuándo Wayback Machine descubrió el dominio por primera vez.

 Alexandre MAROTEL
Alexandre MAROTEL