Descrizione Deep Crawl
Se hai bisogno di esaminare lo stato tecnico del tuo sito web,Deepcrawl è un esploratore che ti consente di vedere come i motori di ricerca eseguono la scansione del tuo sito.
Lo strumento fornisce una vasta gamma di informazioni su ogni pagina del tuo sito Web per darti un’idea chiara della sua indicizzabilità.
Scopriamo in questa descrizione come funziona Deepcraw.
Lo strumento funziona sottraendo dati da diverse fonti come sitemap XML, console di ricerca o analisi di Google.
Pertanto, ti dà la possibilità di collegare fino a 5 fonti per rendere l’analisi delle tue pagine efficace.
L’obiettivo è semplificare il rilevamento di difetti nell’architettura del tuo sito fornendo dati come pagine orfane che generano traffico.
Lo strumento ti offre una visione chiara della salute tecnica del tuo sito Web e approfondimenti utilizzabili che puoi utilizzare per migliorare la visibilità SEO e convertire il traffico organico in entrate.
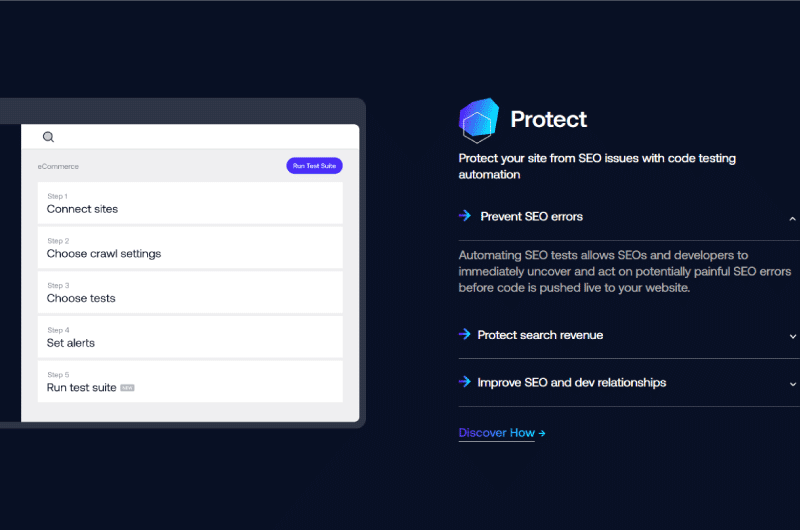
La configurazione di un sito Web per la scansione può essere eseguita in quattro semplici passaggi.
Quando ti registri per una prova gratuita di Deep Crawl, vieni reindirizzato alla dashboard del progetto. Il secondo passaggio consiste nello scegliere le origini dati per l’esplorazione.
Seguendo le istruzioni, puoi configurare rapidamente il tuo sito web e arrivare alle cose più importanti:
Cruscotti
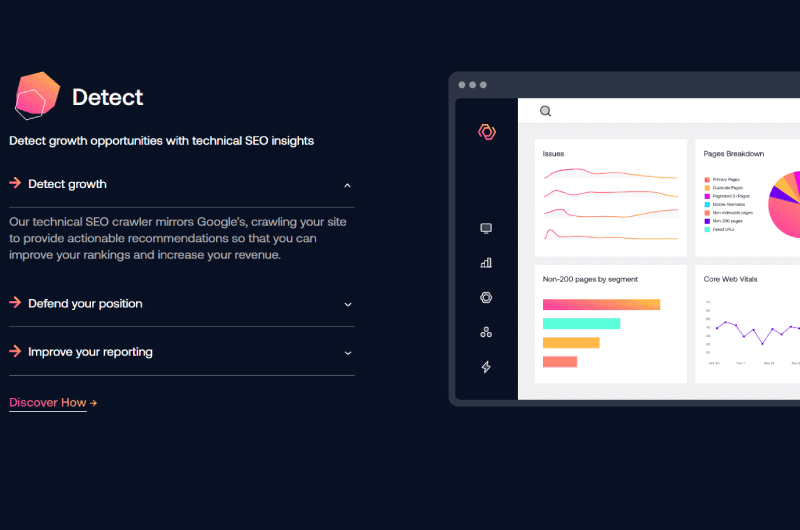
Quando Deep Crawl termina la scansione di un intero sito Web, visualizza in una dashboard abbastanza intuitiva una visualizzazione completa e accurata di tutti i file di registro trovati.
In un primo grafico possiamo leggere un’analisi completa e veloce di tutte le richieste effettuate dagli utenti di dispositivi mobili come i computer.
Segue un riepilogo che evidenzia non solo i principali problemi di scansione del sito web, ma anche un elenco di tutti gli elementi che possono, in un modo o nell’altro, impedire l’indicizzazione delle pagine del sito web.
Deep Crawl sottrae e analizza tutti i dati del payload da tutte le fonti collegate durante l’installazione e li combina con i dati dei file di registro per qualificare meglio ogni problema rilevato.
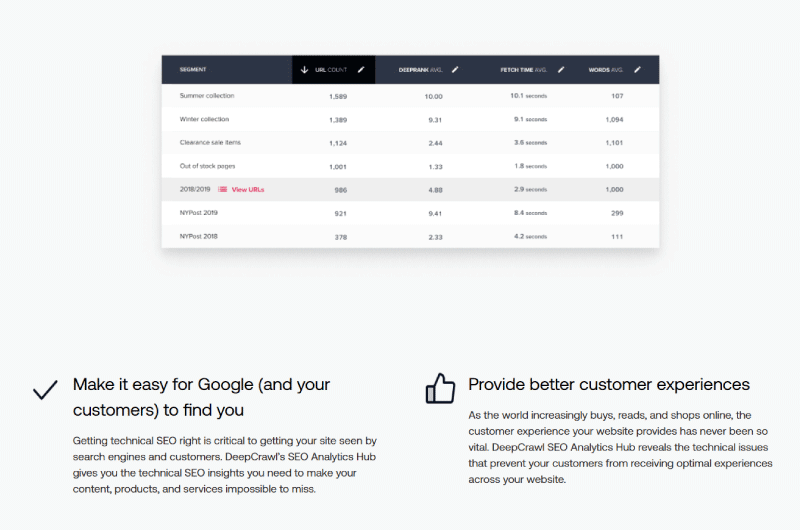
Osserviamo da questo rapporto che molti degli URL elencati nelle sitemap XML non sono stati richiesti.
E questo può essere dovuto ad un debole collegamento delle pagine tra loro o ad una profondità piuttosto importante dell’architettura del sito al punto che ci vuole un robot più potente per raggiungere le pagine web del fondo.
Inoltre, quando le sitemap XML vengono deprecate, non riflettono più in alcun modo gli URL attivi.
In questo caso, possiamo dedurre che un crawl budget è molto importante, soprattutto se hai un sito web di grandi dimensioni.
Ulteriori analisi
La sezione di approfondimento è caratterizzata da due set di dati che sono “Bot Hits” e “Issues”.
Il primo set di dati denominato “Bot Hits” elenca l’insieme di URL richiesti tenendo conto non solo del numero totale di richieste, ma anche dei dispositivi utilizzati per effettuare le richieste.
L’idea è di aiutarti a vedere le pagine su cui i robot si concentrano maggiormente quando esplorano il tuo sito Web e le aree di carenza come pagine potenzialmente obsolete o pagine orfane.
C’è anche un’opzione di filtro che ti consente di individuare tutti gli URL che sono probabilmente interessati dai problemi di pochi.
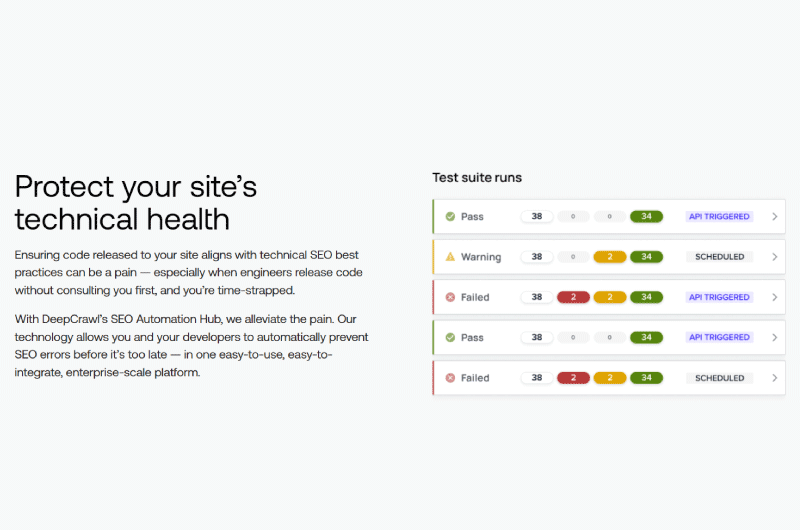
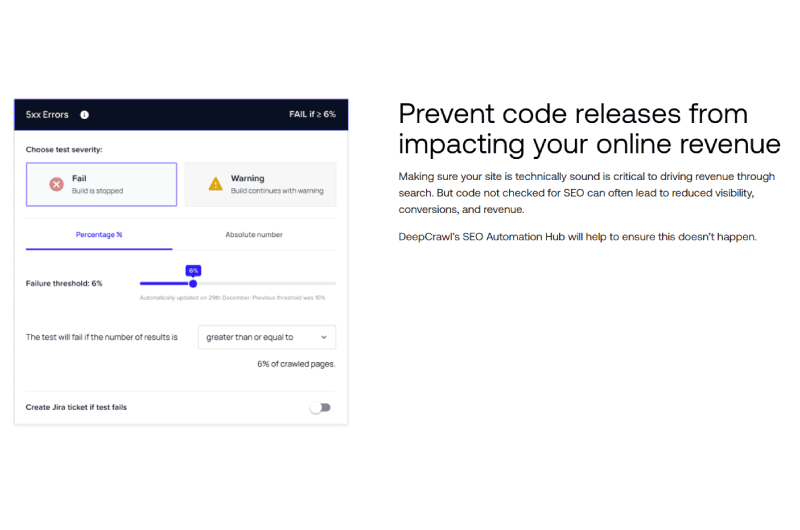
Inoltre, la scheda”Problemi” mostra eventuali problemi che interessano il tuo dominio con dettagli completi sull’errore basati sui dati del file di registro.
Si tratta principalmente di:
Pagine di errore
Questa sezione fornisce una panoramica di tutti gli URL trovati nel file di registro durante la scansione, ma che restituiscono un codice di risposta del server 4XX o 5XX.
Questi sono gli URL che possono causare enormi problemi al sito Web e richiedono una riparazione urgente.
Pagine non indicizzabili
Questa sezione evidenzia gli URL che possono essere scansionati dai motori di ricerca ma che sono impostati su noindex e contengono un riferimento canonico a un URL alternativo o sono bloccati, ad esempio, in robots.txt.
Questo rapporto visualizza gli URL considerando il numero di URL accessibili nei file di registro.
In realtà, non tutti gli URL qui sono necessariamente cattivi, ma è un ottimo modo per evidenziare il crawl budget effettivamente assegnato a pagine specifiche, permettendoti di fare una giusta suddivisione se necessario.
Pagine non autorizzate
Quando blocchi determinati URL del tuo sito dall’essere indicizzati in un file robots.txt, ciò non significa che non ci saranno richieste nel file di registro.
Questa sezione ti consente di identificare gli URL del tuo sito Web che possono essere indicizzati nonostante siano bloccati in un file robots.txt.
Ti permette anche di vedere gli elementi che mancano in determinate pagine in modo che non vengano indicizzati dai crawler dei motori di ricerca come avresti voluto, ad esempio pagine senza l’attributo noindex.
Pagine indicizzabili
Qui puoi vedere tutti gli URL del tuo sito web che possono essere facilmente indicizzati dai motori di ricerca.
La particolarità di questa funzione è che mostra anche un elenco di URL che non hanno generato alcuna query del motore di ricerca nei file di registro forniti.
Nella maggior parte dei casi si tratta di pagine orfane, cioè che hanno pochi collegamenti con altre pagine del sito web.
Pagine desktop e alternative mobili
Questi due report ti consentono di vedere se le tue pagine vengono visualizzate correttamente sui dispositivi per i quali le hai definite.
Questa visualizzazione è particolarmente utile per i siti che utilizzano una versione mobile autonoma o per i siti reattivi e adattivi. È anche un modo migliore per vedere gli URL meno richiesti, probabilmente vecchi o irrilevanti.






 Alexandre MAROTEL
Alexandre MAROTEL