Définition Scrap
Dans le domaine du SEO, le terme Scraping fait allusion à une stratégie employée par les référenceurs ou les marketeurs digitaux pour collecter et utiliser des contenus ou des données d’autres sites web. Le web scraping est considéré comme une…
Dans le domaine du SEO, le terme Scraping fait allusion à une stratégie employée par les référenceurs ou les marketeurs digitaux pour collecter et utiliser des contenus ou des données d’autres sites web. Le web scraping est considéré comme une stratégie White Hat SEO. Il permet aux référenceurs web de gratter automatiquement et rapidement des informations ou données sur le web pour analyser en vue d’élaborer / améliorer une stratégie de marketing. La pratique de cette technique nécessite l’utilisation des outils ou programmes informatiques dédiés.
La collecte de données sur les sites internet est autrefois une pratique très compliquée et était destinée uniquement aux web développeurs expérimentés. Mais depuis l’automatisation du web scraping avec l’implication des outils très performants, la pratique de l’extraction de données sur Internet se fait désormais de manière efficace et à la minute.
Dans cet article, je vais vous expliquer le concept “Scraping” tout en prenant le soin de mettre à votre disposition quelques outils d’automatisation du web scraping pour vous faciliter la tâche lors de vos prochaines pratiques de scraping.
Chapitre 1 : Définition, utilité et les différents types de scraping
Le Scraping est un processus de collecte de données sur le web qui se réalise généralement de manière automatique à l’aide des outils conçus à cet effet. Dans cette partie, je parlerai essentiellement de la signification du concept “Scrap” tout en insistant sur ses utilités dans le domaine du web marketing.
1.1. Que signifie le concept “Scrap” ?
Avant d’aller plus loin dans ce développement, il est important de clarifier une confusion commune qui se fait par rapport aux termes “ web Scraping”.
En effet, le terme « Scraping » s’écrit avec un seul “p” et non “Scrapping” qui a carrément une autre signification sortie de notre cadre. Cependant, il n’est pas rare de voir les gens confondre ces deux termes dans les milieux francophones.
L’écriture correcte “Scraping” provient du verbe anglais “to scrape” qui signifie en français “l’action de gratter ou d’érafler une partie” de quelque chose.
Le terme « scrapping » à ne pas utiliser dans le contexte d’extraction de contenus web vient du verbe “to scrap” et signifie littéralement “abandonner, se débarrasser d’une chose”. Le web “Scraping” signifie donc “grattage”.
Cette tournure de la langue anglaise fait allusion à une pratique de référencement naturel qui consiste à aspirer automatiquement les contenus existants sur des sites web en vue d’une utilisation interne.
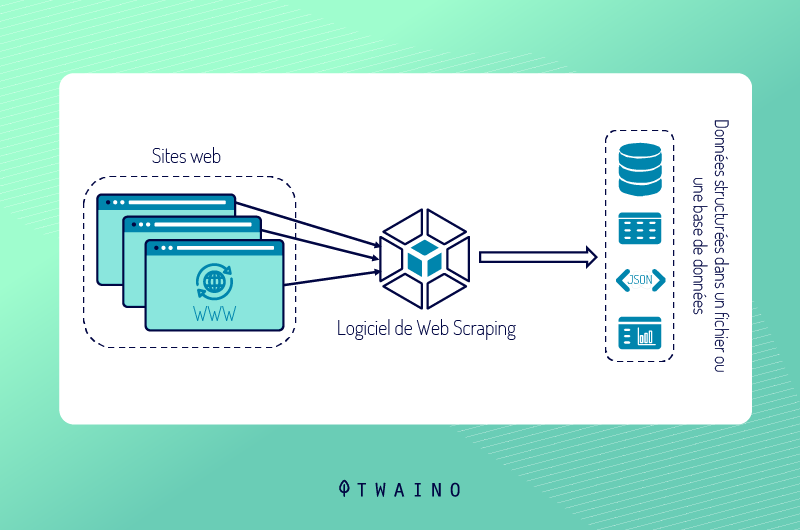
Pour faire du scraping, les référenceurs se servent des robots qui parcourent les sites et extraient automatiquement les contenus.
Les ressources web qui font souvent l’objet du scraping sont entre autres :
- Textes ;
- Images ;
- Vidéos ;
- Code ;
- Etc.
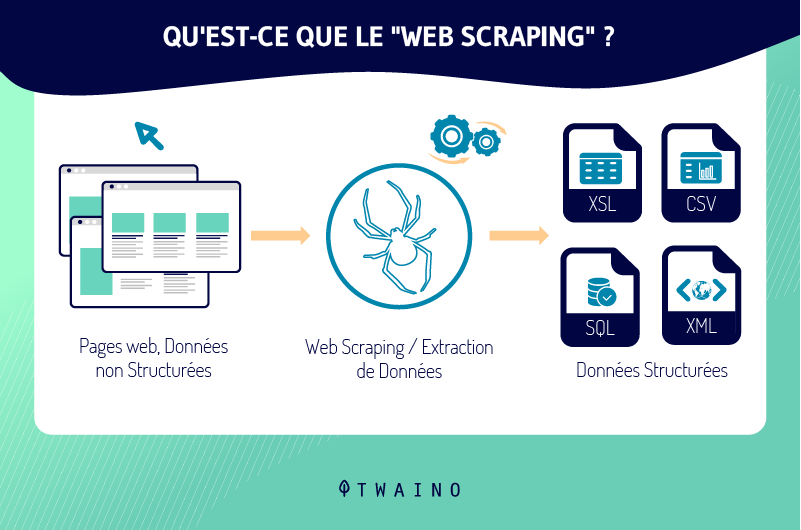
De façon concrète, le Web scraping est un processus d’extraction d’une multitude de données et d’informations utilisables sur d’autres sites web.
Il existe généralement deux manières de faire du scraping sur le web : Scraping manuel et automatique.
- Le scraping manuel : Cette méthode consiste à faire la copie et le collage des données et informations pour en constituer une base de données. Elle prend du temps et ne peut être appliquée que pour les petites quantités de données.
- Le scraping automatique : Cette méthode est la plus répandue et elle utilise différents outils comme des extenseurs et des logiciels pour la collecte des données.
1.2. À quoi sert le scrap ?
L’essentiel à garder lorsqu’on parle du scraping est qu’il s’agit de l’ensemble des pratiques qui permettent de racler des contenus ou des données bien structurées sur des web.
Le Scraping est une stratégie très astucieuse qui permet qui peut être utilisée à de nombreuses fins. À part l’utilisation louche qu’en font certains marketeurs en copiant et plagiant les contenus des autres sites web pour se faire classer sur les pages des résultats de recherche de Google, la pratique du scraping offre plusieurs avantages dans le secteur du marketing digital.
Dans le marketing, certaines personnes s’en servent par exemple pour réaliser de la veille concurrentielle.
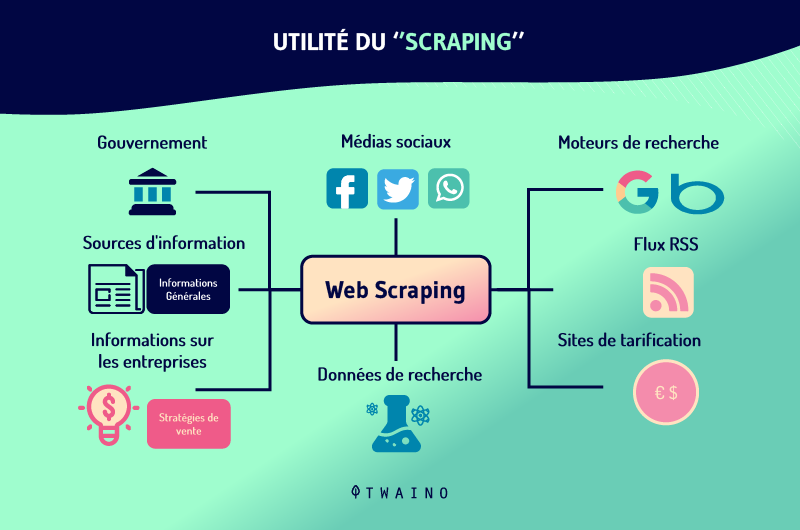
En effet, le scraping vous donne un large avantage vis-à-vis de vos concurrents. Il permet de récolter des informations et des données sur leurs sites en vue d’analyser et de comparer leurs stratégies par rapport au vôtre. Ceci est utile pour améliorer votre stratégie marketing.
Un e-commerçant peut par exemple utiliser le scraping pour consulter et comparer les produits des boutiques concurrentes et ses propres produits.
Le web scraping est également une stratégie très efficace en ce qui concerne les études de marché. Dans ce cas, il permet de constituer des informations et données pour analyser l’efficacité d’un marché ainsi que sa valeur financière.
Dans le domaine du tourisme, Google utilise le scraping de la meilleure façon et collecte des données auprès des comparateurs de prix afin de montrer à ses utilisateurs les prix des vols ainsi que des hôtels.
1.3. Les différents types de scraping
On distingue plusieurs types de scraping parmi lesquels on peut citer :
1.3.1. Le Screen scraping
Le screen scraping est le type de scraping qui se concentre exclusivement sur l’extraction de contenus et de données depuis un écran.
1.3.2. Le report mining
Il s’agit ici d’un type de scraping qui consiste à extraire des données depuis un rapport sous un format de fichier texte.
1.3.3. Le web scraping
Le web scraping est la technique d’extraction des contenus ou des informations depuis des sites web. La suite de ce développement sera exclusivement consacré à l’utilisation du web scraping.
1.4. Les différentes étapes du scraping
Quel que soit le type de scraping, l’emploi ou la pratique respecte toujours trois étapes essentielles à savoir :
1.4.1. Le Fetching
C’est l’étape de la requête où l’extension de navigation ou le robot scraper utilisé se charge tout simplement d’identifier et de télécharger les pages web qui seront analysées.
Il s’agit des différentes manières dont le programme utilisé va explorer les différents sites visés afin de stocker des URL pour le traitement des données.
1.4.2. Le Parsing
Cette étape est encore appelée le traitement. Après l’exploration des sites par le programme et le téléchargement des URL vient l’étape d’analyse et d’extraction.
Pour un traitement plus automatique, on utilise des sélecteurs CSS ou XPath qui permettent de traiter et d’extraire plus précisément les données essentielles.
1.4.3. Le stockage
Le programme de scraping utilisé se charge ici de récupérer, structurer et d’exporter les contenus ainsi que les données raclés afin de les sauvegarder sous un format de choix. Vous pouvez par exemple les sauvegarder dans un tableau de valeur ou une base de données.
1.5. Les différents types de Scrapers
Le web a connu une très brusque évolution et les techniques et moyens de développement sont également démocratisés.
Les moyens pour réaliser le scraping se sont développés au même titre que le web. Il existe aujourd’hui plusieurs moyens pour faire du web scraping de façon automatisée.
Découvrez ici les différents types de scrapers que vous pouvez utiliser pour faire de l’extraction de données web et leur fonctionnement.
1.5.1. Utiliser le Copier-coller pour faire du scraping
Le copier-coller est une méthode pour faire du scraping de façon manuelle. Certes, on a tendance à le minimiser, mais il s’agit d’une technique assez simple et très efficace surtout quand les données à extraire sont de petite quantité.
A l’aide du copier-coller, vous pouvez copier intégralement un tableau sur Wikipédia et le coller dans un tableur au lieu d’une manière très rapide. 1.5.2. Utiliser Linkclump pour gratter des liens et des titres
LinkClump est une extension du navigateur Chrome qui fait partie des meilleures extensions de boostage de vente. Il s’agit d’un scraper assez facile à utiliser qui permet globalement de :
- Extraire facilement les titres et les liens des sites web visés ;
- Trier et sélectionner seulement les liens et des données importants des pages récupérées ;
- Récupérer des images ou d’autres types de fichiers.
Source : Salesdorado
Avec LinkClump, vous pouvez récupérer les liens et les titres de toutes les pages sur le web et tout ceci en un bout de temps. Il est ultra pratique pour collecter les données des données des sites qui apparaissent sur les SERP comme le montre l’image ci-dessus.
1.5.3. Captain Data
Captain Data est un scraper qui permet de récupérer uniquement les données importantes. En quelques gestes, il peut explorer les sites à forte autorité et récupérer les données et informations demandées.
Source : Salesdorado
Captain data parcourt les sites qu’on aurait envie de gratter comme : les plateformes ou réseaux sociaux susceptibles de fournir des mails génériques (Facebook, Linkedin, Sales Navigator, Twitter, Instagram, indeed, etc.) Captain Data permet même dans certains cas d’envoyer des demandes de connexion surtout sur LinkedIn.
Le principale avantage de Captain Data réside dans le fait qu’il peut fonctionner avec les meilleurs outils de mails finders pour vous aider à :
- Détectez-les des contacts commerciaux sur Google ;
- Utiliser des données LinkedIn pour enrichir ces contacts ;
- Chercher des emails pour chacun des contacts avec l’intégration de drop contact.
Néanmoins, aussi simple et efficace qu’il soit, Captain data nécessite des abonnements à partir de 100 euros par mois.
1.5.4. Utiliser TabSave pour Scraper une banque d’images ou de fichier sur le web
TabeSave fonctionne de paire avec LinkClump. Par exemple, les photothèques ou les banques de fichiers regroupent généralement des milliers d’images ou de fichiers.. Avec LinkClump, vous pouvez récupérer tous les liens redirigeant vers les banques d’images ou de fichiers.
Source : Salesdorado
Le rôle de TabSave sera de télécharger toutes les images ou fichiers. Pour ce faire, vous allez coller tous les liens récupérés par LinkClump dans TabSave et cliquer sur “Download” pour télécharger une quantité considérable de ses images et fichiers.
1.5.5. Utiliser Google Spreadsheets et XPath pour scraper les titres H2
Il s’agit ici d’un usage un peu brut, mais il faut comprendre que Google Spreadsheets dispose d’une fonctionnalité appelée ImportXML qui permet de faire énormément de choses.
Source : Salesdorado
De même avec le programme XPath qui est d’ailleurs très important en web scraping, vous pouvez gratter facilement n’importe quel élément sur un site web. Particulièrement avec XPath, on peut récupérer tous les titres H2 d’un article sur des sites web choisis.
1.5.6. Web Scraper pour les débutants
Assez simple et sans code, Web Scraper est un outil de web scraping dont l’utilisation est très simple et efficace.
L’outils met à la disposition de ses utilisateurs des vidéos tutorielles qui vous permettront d’exécuter certaines tâches comme la pagination des contenus sur votre site et les interactions avec les pages, etc. Tout ceci sans même écrire une ligne de code auparavant. Néanmoins, il vous faut de la patience pour réaliser des patterns et faire du scraping. Cela peut vous prendre un peu de temps.
1.5.7. Utiliser SpiderPro a 38$
Encore un des outils les plus simples d’utilisation pour les novices. Avec seulement 38$, vous pouvez télécharger Spider Pro pour effectuer du scraping sur le web.
Source : Salesdorado
L’outil vous permet de sélectionner les contenus ou les données que vous désirez et de les transformer ensuite en données bien organisées téléchargeables en format JSON ou CSV.
1.5.8. Utiliser Apify
Apify est l’un des scrapeurs qui permettent de récupérer des données ordonnées des sites web en ligne.
Si vous disposez d’une boutique en ligne, vous pourrez scraper les données des sites de boutique de même catégorie que la vôtre à l’aide d’Apify en vue d’améliorer vos offres et faire de meilleures propositions pour vos clients.
Dans le cadre de votre veille concurrentielle, vous avez par exemple besoin de créer un tableau dans lequel vous pourrez mettre :
- Les tailles de robe ;
- marques ;
- Les couleurs ;
- Les prix.
La collecte de ces informations de façon manuelle pour compléter votre tableau peut prendre du temps et il est possible que vous n’ayez pas toutes les informations. Avec une configuration de Apify, vous pouvez créer votre tableau automatiquement et extraire les données de vos concurrents en quelques secondes.
Source : Salesdorado
En plus d’être un outil assez simple d’utilisation, Apify dispose de beaucoup de fonctionnalités vous permettant de mettre en place vos Scrapes.
- Apify possède une documentation bien réalisée en ligne comme Puppeteer, jQuery, underscoreJS, etc.
- Apify dispose aussi d’une API qui vous permet de créer des scripts de scrape au format Json,XML,HTML,CSV,RSS et traiter le résultat sur un Webhook.
1.5.9. Scrapy ; efficace et rapide
Scrapy est un outil de scraping destiné particulièrement à ceux qui s’y connaissent en Python. Il permet de scraper facilement et rapidement les ressources sur le web. Scrapy peut être exécuté sur un serveur en local ou sur scrapy cloud.
Par contre, l’usage de cet outil sur des pages générées avec JavaScript peut rencontrer des problèmes..

Source : Salesdorado
Scrapy demande dans ce cas d’utiliser”Network” pour rechercher directement les sources des données.Ainsi, au lieu de forcer l’exécution de la requête sur la page web générée avec JvaScript, vous pouvez le faire directement via votre navigateur web.
Chapitre 2 : Quels sont les avantages du scraping ?
Ce chapitre est consacré aux différents avantages du scraping.
2.1. Les avantages du scraping lié à l’utilisation des outils ?
Les données récupérées sur le web, que ça soit sur les sites concurrents ou sur les prospects peuvent vous permettre de faire plusieurs choses comme :
- Établir une liste d’entreprises bien ciblée ;
- Sélectionner les profils de clients qui vous intéressent ;
- Faire du Event Based Marketing (EBM), c’est-à-dire que détecter automatiquement des signaux chez vos clients. Cela vous permettra de passer à réagir beaucoup plus vite lorsque vos clients ont besoin de vous.
- Etc.
Depuis quelques années, on assiste au recours à l’automatisation qui accélère de plus en plus la popularité du scraping. Cette stratégie qui était autrefois réservée aux développeurs les plus expérimentés est aujourd’hui accessible à tous.
Avec un outil comme Captain data, le scraping se résume désormais au choix des sites à scraper et les données à extraire.
Grâce aux outils de scraping, il est possible de :
- Extraire des informations et des données sans avoir aucune notion technique de la programmation ;
- Mécaniser le processus de récupération des données sur le web ;
- Traiter et analyser les données afin de prendre des décisions stratégiques ;
- Etc.
2.2. Constituer une liste d’entreprise bien ciblée avec le Web Scraping
Si vous voulez faire de la prospection, vous devez nécessairement créer le profil de votre client idéal (Persona Branding). Il s’agit de la première étape de toute activité marketing.
Cette première étape consiste à créer un profil du client (Ideal Customer Profile) adapté à vos offres et services.. Avec le scraping, vous pouvez récupérer beaucoup de données sur les entreprises de votre profil type lorsque vous cibler des entreprises.
Vous allez pouvoir collecter à l’aide du scraping des informations précieuses comme :
- Des adresses ;
- Des emails ;
- Des numéros de téléphone.
L’objectif est d’avoir toutes les informations nécessaires pouvant vous conduire vers l’entreprise ou le client idéal. Si votre cible est sur LinkedIn par exemple, je vous recommande d’utiliser Linkedin Sales Navigator qui est un outil de scraping hyper puissant.
Source : Salesdorado
Ce Scraper vous permettra d’obtenir des listes d’entreprises bien ciblées.
Par ailleurs, Google Maps représente aussi une source très efficace où vous pouvez collecter des contacts des sites ayant les traits caractéristiques de votre cible.
2.3. Identifier et sélectionner les bonnes informations dans les comptes de vos clients cibles sur LinkedIn
Il existe plusieurs manières pour détecter les bons contacts et les données correctes donc vous avez besoin
Si vous avez une entreprise qui évolue dans le système B2B (Business to Business), vous pourrez trouver ces données là, en explorant les comptes de vos clients cibles sur LinkedIn. Les outils présentés précédemment peuvent vous aider à réaliser rapidement cette tâche et vous allez aussi gagner de précieuse minute au lieu de parcourir les profils un à un.
2.4. Repérer les signaux faibles avec la pratique du scraping
Le scraping est une stratégie qui permet de à un marketeur de suivre l’activité d’un prospect ou d’un concurrent en détectant les signaux qui lui permettront d’envisager des stratégies et des opportunités business.
Je vous propose ici quelques astuces que vous pouvez utiliser pour détecter les entreprises suivant vos besoins.
Source : Salesdorado
Astuce 1 : Appliquer les filtres spécifiques sur Sales Navigator
Ex. Si vous décidez de détecter des entreprises en pleine croissance, vous pouvez utiliser les filtres pour explorer “la Croissance du nombre d’employés”.
Astuce 2 : Utiliser la fonction “Job search” d’ Indeed pour agrémenter les données récupérées.
Cette astuce est plus adaptée lorsque votre cible est composée d’entreprises qui font du recrutement.
Dans ce cas, vous pouvez aussi aller sur LinkedIn pour chercher les entreprises qui postent des offres d’emploi. Il faut noter que les avis négatifs vous donnent une meilleure opportunité pour récupérer certains clients insatisfaits et mécontents de vos concurrents.
2.5. Le scraping permet de donner un score à chaque client : le scoring CRM
Si vous voulez identifier vos indicateurs clés de performance et évaluer votre marché, le scraping est également une meilleure stratégie à mettre en place. Commencer par détecter un site web ayant beaucoup de valeurs.
Vous pouvez notamment collecter beaucoups plus de données sur l’entreprise ciblée en grattant :
- Les réseaux sociaux ;
- les adresses et données légales ;
- Les données et informations facilement détectables (les langues, liens de navigations, numéros de téléphone, etc.).
De plus, vous pouvez créer des patterns pour extraire les emails des employés. Un pattern est défini comme étant la structure ou la construction d’une adresse email.
Image
Par exemple, les adresses email professionnelles sont généralement construites avec la structure : prénom@nomdelentreprise.com.
En détectant le pattern de l’entreprise, vous avez la possibilité d’avoir les emails de tous les employés.
Pour automatiser vos actions dans ce sens, vous pouvez utiliser un outil comme Hunter. D’autres outils comme Builtwith et Similartech peuvent aider à identifier le trafic de façon automatique et même d’identifier d’autres outils de scraping qu’utilisent les entreprises concurrentes.
2.5. Recueillir des données et des informations fiables
La qualité des données ou Data quality est l’aptitude d’une entreprise à mettre à jour ses données à mesure que les choses changent.
En tant qu’entreprise, vous devez donc lutter contre l’obsolescence de vos données. Pour le faire, le scraping peut également vous aider à suivre régulièrement vos bases de données et à les mettre à jour à temps.
En effet, on peut détecter une modification ou un changement d’une levée de fond par exemple avec des signaux des outils de scraping. Cela vous permettra d’identifier de nouvelles opportunités de business ou de stratégie marketing.
2.6. Rendre les données récoltées accessible et opérationnelle
Comme je l’ai expliqué dans la section précédente, la data quality permet d’actualiser les données.
Mais, notez que les données ne sont fiables que lorsqu’elles sont opérationnelles et identiques dans tous les systèmes (logiciel CRM, logiciel de marketing automation, etc.) où elles sont présentes.
Avec des outils de scraping comme Captain data, vous avez la possibilité de rendre les données accessibles sur le logiciel CRM, mais vous pouvez également les rendre disponible sur tous les logiciels de l’écosystème data de votre entreprise.
Chapitre 3 : Autres préoccupations par rapport à la pratique du scraping
3.1. Le scraping est-il une stratégie Black Hat ou White Hat ?
Les principaux objectifs de la pratique des techniques de scraping sont le référencement et la vente.
Le scraping est perçu comme une extraction frauduleuse des données sur le web. Il est utilisé parfois avec de mauvaises intentions et certains webmasters collectent des informations sur d’autres sites et viennent ensuite les collées sur leurs sites pour améliorer leur référencement.
Cette manière de faire va à l’encontre des directives de Google et constitue une mauvaise pratique lorsqu’il s’agit de référencer un site web.
Il s’agit donc clairement d’une pratique Black Hat qui peut susciter en revanche une pénalité manuelle ou simplement un déclassement de la part de Google.

Par contre, lorsque le scraping est utilisé dans l’intention d’améliorer votre stratégie de marketing, il peut être considéré comme du White Hat.
En effet, lorsque les données extraites des sites web sont traitées et analysées en vue de suivre l’évolution des concurrents pour définir une nouvelle approche marketing, le scraping contribuera à un développement de votre business de façon légale.
Notez que le scraping n’est pas explicitement une stratégie Black Hat même si certains l’utilisent de la mauvaise manière. D’ailleurs, Google fait aussi du scraping sur un grand nombre de sites afin de garantir à ses utilisateurs de meilleurs résultats de recherche dans les SERP.
3.2. Quelle est la différence entre web scraping et indexation web ?
Bien que le scraping et l’indexation de données web suivent presque le même processus, ils ne sont pas les mêmes et ont tous des objectifs différents.
L’indexation est une pratique qui permet à Google d’explorer les sites web et d’indexer les pages web disposant de contenus de qualité afin de les présenter dans les résultats de recherche.

Ce travail se fait par des Robots d’indexation encore appelés Spiders qui sont chargés de visiter les pages web tout en respectant les directives (Robot.txt, Nofollow,etc) du propriétaire du site.
Quant au scraping, l’objectif global est de récupérer les contenus des autres sites web pour une utilisation personnelle.
Le scraping se fait sans le consentement du propriétaire du site et les outils de scraping utilisés ne respectent aucune directive.
Conclusion
Dans cet article nous avons défini le scraping avec toutes les nuances possibles à faire avec le terme “Scrap” ainsi que les types et avantages du scraping pour le marketing digital.
Il ne fait aucun doute que l’automatisation de la pratique du scraping a beaucoup contribué à l’expansion de cette technique..
Nous avons également exposé une liste d’outils de scraping très performants pour aider à extraire des données et des contenus sur le web rapidement et en toute sécurité.
Cet article vous a- t-il été utile ?
Laissez-nous un commentaire et surtout mentionnez le Scraper qui vous a marqué et que vous comptez utiliser bientôt.

Termes reliés