Definición de Duplicate Content o contenido duplicado

El duplicate content o contenido duplicado es contenu simiar o copias idénticas de un texto que aparece en varios sitios web o en diferentes páginas de un mismo sitio.
Según Matt Cutts de Google, entre el 25 % y el 30 % del contenido en Internet está duplicado. En la misma línea, un estudio de Raven Tools basado en datos de auditoría sitúa esta cifra alrededor del 29 %.
Aunque este fenómeno suele ser involuntario, Google y otros motores de búsqueda aplican penalizaciones indirectas a los sitios que presentan duplicaciones.
Para comprender mejor este concepto, abordaremos los siguientes puntos clave:
- Una visión general del significado de duplicate content
- Las causas y formas de detectar contenido duplicado con herramientas como duplichecker o dupli checker
- Las buenas prácticas para gestionar duplicaciones
¡Descúbrelo!

Aunque este fenómeno suele ser involuntario, Google y otros motores de búsqueda penalizan indirectamente los sitios web con contenido duplicado
Para entender mejor este concepto, hay que discutir los siguientes puntos clave:
- Un breve resumen del significado de »contenido duplicado» y sus diferentes tipos;
- Las causas y las formas de detectarlas;
- Buenas prácticas para tratarlas.
Estas son algunas de las muchas preguntas clave a las que responderé con claridad y precisión a lo largo de esta guía.
¡Descubra más!
Capítulo 1: ¿Qué debemos entender sobre el «contenido duplicado»?
En este capítulo analizamos los elementos esenciales:
- Recordatorio de su definición
- Tipos de contenido duplicado
- Impacto en el SEO










1.1 ¿Qué es el contenido duplicado?
El contenido duplicado es un bloque de texto que aparece varias veces en la web. Cuando un texto está en una sola URL hablamos de contenido único; en caso contrario, se considera duplicado.
En términos simples, implica copiar contenido de terceros y publicarlo en un sitio propio, generalmente sin autorización del autor.Esto genera dudas sobre la capacidad del sitio para producir contenido original y puede afectar negativamente el posicionamiento en buscadores. Por ello, muchos profesionales utilizan herramientas como duplichecker plagio, duplicheck, o dupli checker.com para verificar la originalidad.

Para ser más claros, se trata del acto de copiar la producción de otros y publicarla en su sitio. En general, esta duplicación se realiza sin el permiso previo del autor.
Esto no sólo hace dudar de su capacidad para producir textos atractivos y originales, sino que además Google puede penalizar su SEO.
1.2 Tipos de contenido duplicado










La duplicación no siempre proviene de copias intencionales. En muchos casos se debe a:
- Problemas técnicos del CMS
- Gestión del catálogo en e-commerce
- Configuración de URL
- Uso de parámetros dinámicos
De estas situaciones se distinguen dos tipos principales.
1.2.1 Contenido duplicado interno
El contenido duplicado interno se produce cuando hay una repetición de texto o partes de texto en dos o más páginas del mismo sitio web

Fuente: synchrone
Generalmente surge por:
- Errores técnicos
- Configuración incorrecta de URL
- Paginación
- Versiones imprimibles
En este caso no existe robo de contenido, sino una multiplicación involuntaria de páginas con el mismo texto.
1.2.2 Contenido duplicado externo
Se refiere a páginas cuyo texto es idéntico al de otros sitios web. Este tipo genera conflictos más graves.

Fuente: synchrone
Es frecuente en fichas de productos e-commerce que utilizan descripciones del fabricante. Cuando varios sitios venden el mismo producto y copian la misma descripción, el resultado es duplicación masiva.
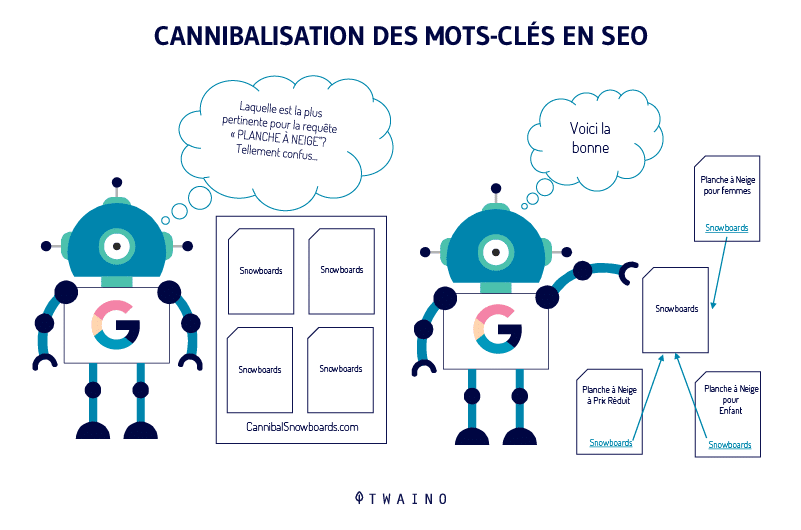
1.3 Impacto del contenido duplicado en el SEO
La duplicación genera confusión en los robots de búsqueda, provocando que:
Se reduzca la visibilidad del contenido principal
La autoridad se divida entre varias URL
Google tenga que elegir qué versión posicionar
Cada variante de URL recibe diferente autoridad, lo que afecta el ranking.
Con el tiempo, Google ha reconocido que la mayoría de duplicaciones no son intencionales. Sin embargo, análisis muestran que el 50 % de los sitios enfrenta problemas de duplicación.

Fuente : Semrush
El objetivo de Google es ofrecer diversidad en resultados, por lo que selecciona una única versión para posicionar. Esto implica que la página que el propietario considera más relevante puede no ser la elegida.

/wp-content/uploads/2020/03/143-Canibalisation-de-mots-cles.png
En resumen, los principales problemas derivados son:
- Dificultad de posicionamiento
- Mala experiencia de usuario
- Disminución del tráfico orgánico
Capítulo 2: Causas y detección del contenido duplicado
Tras conocer las causas, veremos cómo detectarlo con herramientas SEO como duplichecker, dupli checker, o funciones de buscar por imagen.










2.1 Causas del contenido duplicado
Existen múltiples razones por las que aparece duplicación.
2.1.1 HTTP vs HTTPS y www vs sin www
La instalación de certificados SSL permite pasar de HTTP a HTTPS y mejorar la seguridad del sitio. Sin embargo, si no se aplican redirecciones, se crean versiones duplicadas.

Del mismo modo, el contenido puede estar accesible con y sin www.
Por ejemplo:
Para los motores de búsqueda, son URLs diferentes aunque muestren el mismo contenido.
Esta es una de las causas más frecuentes de duplicación.
2.1.2 Contenido scrappeado o copiado
El scraping ocurre cuando otros sitios copian contenido. Si Google no identifica la fuente original, puede posicionar la copia en lugar del original.
Esto es común en e-commerce donde se utilizan descripciones del fabricante.Para detectar este problema, muchos SEO emplean herramientas como duplichecker gratis, que permite comprobar coincidencias textuales y localizar copias externas.

2.1.3 Variantes de URL
Las variaciones pueden originarse por:
- ID de sesión
- Parámetros de consulta
- Uso de mayúsculas
Si una URL contiene parámetros que no modifican el contenido, puede generar duplicación.
Los ID de sesión, utilizados para rastrear el comportamiento del usuario, crean nuevas URLs hacia la misma página.sesión a la URL de cada página en la que se hace clic

Fuente : Polepositionmarketing
Asimismo, el uso inconsistente de mayúsculas puede provocar duplicación. Por ejemplo:
- twaino.com/blog
- twaino.com/Blog
Ambas serían consideradas páginas diferentes.
Detección del contenido duplicado
Tras comprender las causas, el siguiente paso es la detección.
Algunas estrategias incluyen:
Uso de herramientas SEO
Plataformas como:
- duplichecker
- dupli checker
- duplicheck
- duplichecker plagio
permiten analizar textos y detectar coincidencias en la web.
Búsqueda manual
La función buscar por imagen o búsqueda de frases exactas en Google ayuda a localizar duplicaciones externas.
Auditorías SEO
Herramientas de auditoría permiten identificar páginas con contenido repetido dentro del sitio.
Buenas prácticas para gestionar contenido duplicado
Para evitar penalizaciones y mejorar el SEO:
1. Implementar redirecciones 301
Permiten consolidar versiones duplicadas hacia una única URL.
2. Usar etiquetas canonical
Indican a Google la versión preferida de una página.
3. Crear contenido original
Evitar copiar descripciones y apostar por contenido único.
4. Controlar parámetros de URL
Configurar correctamente el CMS y Google Search Console.
5. Monitorizar con herramientas
Utilizar regularmente duplichecker gratis o dupli checker.com para detectar duplicaciones.
2.2 ¿Cómo detectar contenido duplicado?
En esta sección veremos primero las formas gratuitas de identificar contenido duplicado y luego las herramientas especializadas de detección.
2.2.1 Métodos gratuitos para encontrar contenido duplicado
Existen varias estrategias gratuitas que permiten:
- Encontrar contenido duplicado
- Identificar páginas con múltiples URL
- Detectar problemas técnicos que generan duplicación
Estas técnicas constituyen el primer paso antes de usar herramientas como duplichecker gratis o dupli checker.
2.2.1.1 Google Search Console
Google Search Console es una herramienta gratuita y potente que ofrece visibilidad sobre el rendimiento de las páginas en los resultados de búsqueda.
Dentro del informe Cobertura del apartado Indexación, es posible identificar URL que pueden causar problemas de contenido duplicado.

Debes buscar los problemas más comunes:
- Versiones HTTP y HTTPS de una misma URL
- Versiones con www y sin www
- URL con y sin barra final “/”
- URL con y sin parámetros de consulta
- URL con mayúsculas y minúsculas
- Consultas long tail posicionadas en varias páginas
Es importante registrar las URL detectadas con problemas de duplicación para analizarlas posteriormente
2.2.1.2 Verificador gratuito de contenido duplicado
SEO Review Tools desarrolló un verificador gratuito para ayudar a combatir el robo de contenido.
Al introducir la URL en el verificador, se obtiene una vista de las páginas internas y externas que duplican el contenido.

La detección de duplicación externa es crucial, ya que puede indicar scraping o plagio. Cuando se identifica una copia, es posible solicitar a Google la eliminación del contenido duplicado.Herramientas como duplichecker plagio, duplicheck, o la función buscar por imagen pueden complementar este análisis.
2.2.2 Herramientas para encontrar contenido duplicado
A continuación, presentamos una visión general de herramientas gratuitas y de pago para detectar duplicación interna y externa.
2.2.2.1 Copyscape
Lanzado en 2004, Copyscape es uno de los verificadores de plagio más conocidos.

La versión gratuita permite introducir la URL y ejecutar la búsqueda sin registro. Sin embargo, presenta limitaciones, ya que no reconoce búsquedas previas realizadas por otros usuarios.
La versión premium ofrece funciones avanzadas:
- Introducir texto directamente
- Analizar más de 10 000 páginas
- Excluir dominios
Coste aproximado de 0,05 USD por búsqueda.
2.2.2.2 Dupli Checker
Dupli checker permite verificar texto introducido manualmente o cargado desde un archivo.

El sistema compara el contenido con resultados detectados y muestra el porcentaje de coincidencia, lo que facilita identificar duplicaciones.Este tipo de herramientas es similar a dupli checker.com o duplichecker, ampliamente utilizadas por especialistas SEO.
2.2.2.3 Plagiarisma
Plagiarisma permite analizar texto o URL, aunque la versión gratuita solo utiliza Bing como motor de búsqueda.

Existe una versión premium con funcionalidades adicionales, con un coste aproximado de 0,05 USD por búsqueda.
2.2.2.4 Plagium

Plagium ofrece dos versiones:
- Gratuita, con búsquedas limitadas introduciendo texto
- Premium, con coste aproximado de 0,07 USD por búsqueda y análisis más profundo
La versión de pago permite verificar documentos Word y PDF.
2.2.2.5 PlagScan
PlagScan es una herramienta completa de pago con planes desde 4,99 USD por 5000 palabras analizadas.

Permite:
- Identificar páginas con texto duplicado
- Localizar el contenido duplicado
Comparar diferentes páginas.
2.2.2.6 Quetext

Quetext es una herramienta muy popular para detectar plagio y contenido similar.
Ofrece la opción de calcular el score de similitud, proporcionando resultados más precisos.
Una vez detectadas duplicaciones, el proceso de eliminación resulta más sencillo.
Capítulo 3: ¿Cómo eliminar contenido duplicado?
Eliminar contenido duplicado ayuda a garantizar que la página correcta sea accesible e indexada por los motores de búsqueda.
Sin embargo, en algunos casos no es necesario eliminar el contenido, sino indicar la versión original










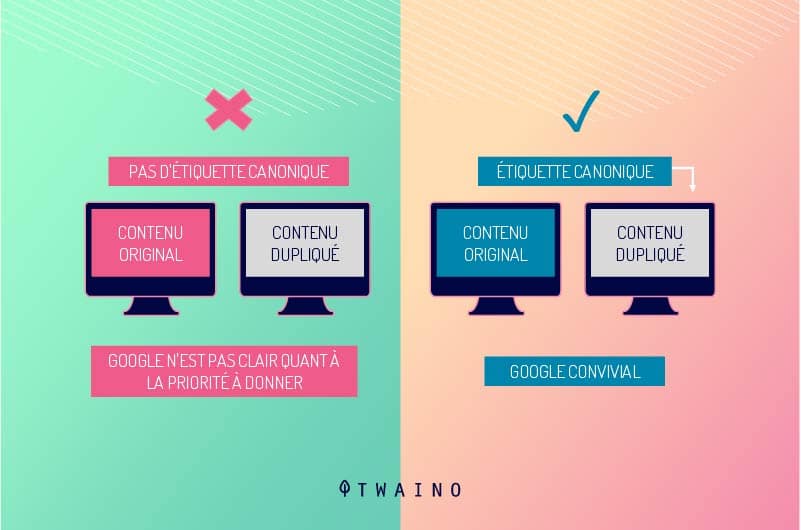
3.1. etiqueta rel = «canonical»
La etiqueta canonical permite a los motores de búsqueda identificar la versión original de una URL.
Los motores consolidarán la autoridad y los enlaces hacia la URL especificada, considerándola el contenido original.El uso de la etiqueta canonical no elimina la página duplicada de los resultados, sino que indica cuál debe recibir la equidad de enlaces.

/wp-content/uploads/2020/11/Pages-dupliquees-sans-indication-de-la-version-canonique.jpg
Es especialmente útil cuando no es necesario eliminar la duplicación, como en URLs con parámetros o variaciones técnicas.
3.2 Redirecciones 301
La redirección 301 es la mejor solución cuando no se desea que la página duplicada sea accesible.
Al aplicarla, se indica a los motores de búsqueda la URL destino, transfiriendo el tráfico y el valor SEO.

/wp-content/uploads/2020/07/guide-des-codes-detat-HTTP-pour-les-SEO.png
Para elegir la página principal, se debe seleccionar la más optimizada y con mejor rendimiento.
Al fusionar varias páginas que compiten por la misma palabra clave, se crea un contenido más fuerte y relevante.
3.3 Meta robots noindex
La etiqueta noindex es un fragmento de código que se añade en la cabecera HTML para excluir una página del índice.Al usar el atributo content = noindex, follow, se permite rastrear los enlaces de la página pero se evita su indexación.

/wp-content/uploads/2020/09/Les-attributs-index-1.jpg
Esta etiqueta es especialmente útil en paginaciones que generan múltiples URLs con contenido similar.
3.4 Canonical auto-referencial
Para protegerse del scraping, es posible añadir una etiqueta canonical que apunte a la misma URL.
Esto indica a los motores de búsqueda que la página actual es el contenido original.
Cuando el contenido es copiado, el HTML suele replicarse, incluyendo la etiqueta canonical, lo que ayuda a preservar la versión original.

Sin embargo, esta técnica solo funciona si el scraper copia el código completo.
Resumen
Aunque el contenido duplicado suele ser involuntario, puede afectar el SEO y el potencial de posicionamiento si no se gestiona correctamente.
Al implementar estrategias como:
- Auditorías SEO
- Uso de herramientas como duplichecker gratis y dupli checker
- Etiquetas canonical
- Redirecciones 301
- Meta noindex
los motores de búsqueda podrán indexar y posicionar el sitio de manera más eficiente.
El objetivo de este artículo ha sido detallar cada aspecto anunciado en la introducción para ayudarte a optimizar tu sitio web.
Si conoces otras estrategias para combatir el duplicate content, no dudes en compartirlas.
¡Hasta pronto!

Términos relacionados




{kind=link}
{kind=link}
{kind=link}
{kind=link}